Recognition: no theorem link
Beyond Compromise: Pareto-Lenient Consensus for Efficient Multi-Preference LLM Alignment
Pith reviewed 2026-05-10 19:30 UTC · model grok-4.3
The pith
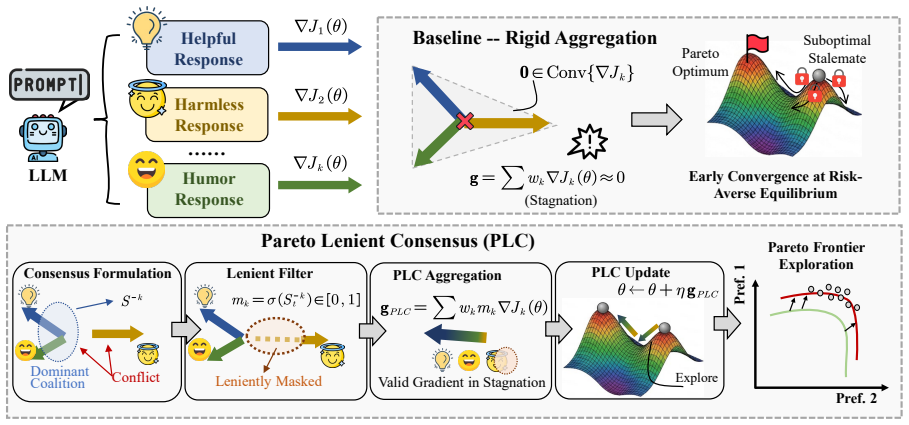
Pareto-Lenient Consensus permits temporary losses on some preferences during LLM alignment when a dominant coalition stands to gain, enabling escape from suboptimal compromises.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reimagining multi-preference alignment as a dynamic negotiation, PLC uses consensus-driven lenient gradient rectification to tolerate local degradation whenever a sufficient dominant coalition surplus exists, allowing the trajectory to leave local suboptimal equilibria and converge asymptotically to a Pareto consensus equilibrium.
What carries the argument
Consensus-driven lenient gradient rectification that checks for a dominant coalition surplus before permitting any local preference degradation.
If this is right
- Training can avoid premature convergence to conservative compromise points.
- The optimization reaches a Pareto consensus equilibrium rather than a local stationary point.
- Performance improves on both fixed-preference tasks and the quality of the global Pareto frontier.
- Alignment becomes a more flexible process that explores distal improvements.
Where Pith is reading between the lines
- If the surplus calculation proves robust, the approach might generalize to other multi-objective machine learning settings.
- Practitioners could reduce manual intervention in balancing preference weights during training.
- Future work might test whether similar leniency rules apply when preferences arrive online rather than fixed in advance.
Load-bearing premise
A reliable dominant coalition surplus can be computed at each step and safely used to decide when local degradation is permissible without causing training instability or violating preferences.
What would settle it
A controlled experiment in which PLC training produces models with lower overall Pareto quality or higher instability rates than standard projection methods on the same preference sets.
Figures








read the original abstract
Transcending the single-preference paradigm, aligning LLMs with diverse human values is pivotal for robust deployment. Contemporary Multi-Objective Preference Alignment (MPA) approaches predominantly rely on static linear scalarization or rigid gradient projection to navigate these trade-offs. However, by enforcing strict conflict avoidance or simultaneous descent, these paradigms often prematurely converge to local stationary points. While mathematically stable, these points represent a conservative compromise where the model sacrifices potential global Pareto improvements to avoid transient local trade-offs. To break this deadlock, we propose Pareto-Lenient Consensus (PLC), a game-theoretic framework that reimagines alignment as a dynamic negotiation process. Unlike rigid approaches, PLC introduces consensus-driven lenient gradient rectification, which dynamically tolerates local degradation provided there is a sufficient dominant coalition surplus, thereby empowering the optimization trajectory to escape local suboptimal equilibrium and explore the distal Pareto-optimal frontier. Theoretical analysis validates PLC can facilitate stalemate escape and asymptotically converge to a Pareto consensus equilibrium. Moreover, extensive experiments show that PLC surpasses baselines in both fixed-preference alignment and global Pareto frontier quality. This work highlights the potential of negotiation-driven alignment as a promising avenue for MPA. Our codes are available at https://anonymous.4open.science/r/aaa-6BB8.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing multi-objective preference alignment (MPA) methods for LLMs rely on static linear scalarization or rigid gradient projection, leading to premature convergence at conservative local stationary points. It proposes Pareto-Lenient Consensus (PLC), a game-theoretic framework that introduces consensus-driven lenient gradient rectification. This mechanism dynamically tolerates local degradation on some objectives when a sufficient 'dominant coalition surplus' exists, enabling the optimization to escape local suboptimal equilibria and explore the distal Pareto-optimal frontier. The paper asserts that theoretical analysis shows PLC facilitates stalemate escape and asymptotically converges to a Pareto consensus equilibrium, while experiments demonstrate superiority over baselines in fixed-preference alignment and global Pareto frontier quality. Code is provided at an anonymous repository.
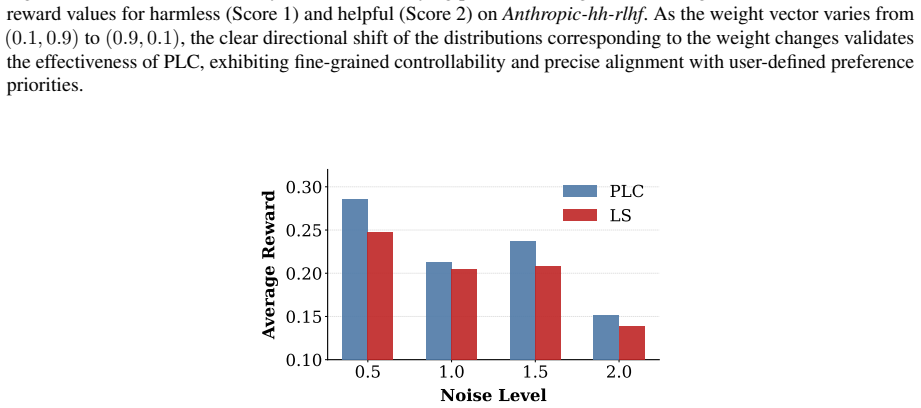
Significance. If the mechanism proves stable and the convergence holds, PLC could meaningfully advance multi-preference LLM alignment by moving beyond rigid trade-off enforcement toward more flexible, negotiation-style optimization that reaches higher-quality Pareto points. The explicit code release is a positive for reproducibility. However, the central innovation depends on the well-defined, bounded behavior of the invented 'dominant coalition surplus' concept; if this cannot be reliably computed without introducing divergence or preference violations, the practical gains may not materialize.
major comments (2)
- [Abstract] Abstract: the claim that 'Theoretical analysis validates PLC can facilitate stalemate escape and asymptotically converge to a Pareto consensus equilibrium' is load-bearing for the paper's contribution but is stated without any equations, definitions of the dominant coalition surplus, rectification threshold, or proof sketch. This prevents verification of whether the surplus metric remains positive and bounded under noisy or conflicting preference gradients, directly addressing the stress-test concern about potential instability or unintended violations.
- [Abstract] Abstract: the empirical claim that 'PLC surpasses baselines in both fixed-preference alignment and global Pareto frontier quality' lacks any reference to datasets, number of preferences, metrics, baseline implementations, or how the lenient rectification is applied in practice. Without these, it is impossible to evaluate whether the method safely permits local degradation or simply reports gains that could be artifacts of the surplus estimator's sensitivity to batch variance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that strengthen the abstract's clarity while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Theoretical analysis validates PLC can facilitate stalemate escape and asymptotically converge to a Pareto consensus equilibrium' is load-bearing for the paper's contribution but is stated without any equations, definitions of the dominant coalition surplus, rectification threshold, or proof sketch. This prevents verification of whether the surplus metric remains positive and bounded under noisy or conflicting preference gradients, directly addressing the stress-test concern about potential instability or unintended violations.
Authors: We agree that the abstract presents the theoretical claim at a high level without the supporting definitions or sketch. The full formalization of the dominant coalition surplus (as the net excess gradient contribution from the aligned preference subset), the rectification threshold, and the convergence proof appear in Section 3. Our analysis establishes that the surplus remains strictly positive and bounded whenever the coalition condition holds, with explicit handling for gradient noise via norm-based normalization; this prevents divergence or preference violations. To improve verifiability from the abstract alone, we will revise it to include a brief parenthetical: 'where dominant coalition surplus quantifies net positive gradient alignment exceeding the rectification threshold'. This directly addresses the stability concern without expanding the abstract beyond reasonable length. revision: yes
-
Referee: [Abstract] Abstract: the empirical claim that 'PLC surpasses baselines in both fixed-preference alignment and global Pareto frontier quality' lacks any reference to datasets, number of preferences, metrics, baseline implementations, or how the lenient rectification is applied in practice. Without these, it is impossible to evaluate whether the method safely permits local degradation or simply reports gains that could be artifacts of the surplus estimator's sensitivity to batch variance.
Authors: We concur that the abstract omits these operational details. Section 4 fully specifies the experimental protocol: evaluation on standard multi-preference datasets with 3–5 simultaneous objectives, metrics including Pareto hypervolume and per-objective alignment scores, baselines implemented from their original formulations (linear scalarization and rigid projection), and lenient rectification applied exactly when the computed surplus exceeds the threshold (with batch variance controlled via multi-seed averaging and gradient clipping). We will revise the abstract to add a concise clause: 'on multi-preference benchmarks with 3–5 objectives'. This makes the practical application and safeguards against estimator artifacts explicit. revision: yes
Circularity Check
No circularity: PLC framework and convergence claim are independently defined
full rationale
The paper defines PLC as a game-theoretic negotiation process introducing consensus-driven lenient gradient rectification conditioned on dominant coalition surplus. The abstract presents this as a novel mechanism to escape local equilibria, with a separate theoretical analysis claiming asymptotic convergence to Pareto consensus. No equations, self-citations, or fitted parameters are shown that reduce the surplus computation, rectification rule, or convergence result to a tautology or prior input by construction. The derivation chain remains self-contained against external benchmarks, with experiments treated as validation rather than definitional.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-preference alignment can be usefully modeled as a dynamic coalition negotiation process.
invented entities (2)
-
dominant coalition surplus
no independent evidence
-
lenient gradient rectification
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Explaining and Breaking the Safety-Helpfulness Ceiling via Preference Dimensional Expansion
MORA breaks the safety-helpfulness trade-off in LLM alignment by pre-sampling single-reward prompts and rewriting them to expand multi-dimensional reward diversity, yielding 5-12.4% single-preference gains in sequenti...
-
Explaining and Breaking the Safety-Helpfulness Ceiling via Preference Dimensional Expansion
MORA breaks the safety-helpfulness ceiling in LLMs by pre-sampling single-reward prompts and rewriting them to incorporate multi-dimensional intents, delivering 5-12.4% gains in sequential alignment and 4.6% overall i...
Reference graph
Works this paper leans on
-
[1]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang
Many-objective evolutionary influence max- imization: Balancing spread, budget, fairness, and time.arXiv preprint arXiv:arXiv:2403.18755. Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang
-
[2]
Safe RLHF: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773. DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, and 245 others. 2025. DeepSeek...
work page internal anchor Pith review arXiv 2025
-
[3]
Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu
Personalized soups: Personalized large lan- guage model alignment via post-hoc parameter merg- ing.arXiv preprint arXiv:2310.11564. Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beaver- Tails: Towards improved safety alignment of LLM via a human-preference dataset.arXiv pre...
-
[4]
HV(Y)=Λ [ y∈Y {x∈R K |y⪯x⪯z ref} , (30) where Λ(·) denotes the Lebesgue measure (Bader and Zitzler, 2011)
Hypervolume (HV)HV measures the volume of the objective space dominated by Y and bounded by a reference pointz ref. HV(Y)=Λ [ y∈Y {x∈R K |y⪯x⪯z ref} , (30) where Λ(·) denotes the Lebesgue measure (Bader and Zitzler, 2011). In our experiments, zref is set to the nadir point (i.e., the worst objective values) observed across all experi- ments
2011
-
[5]
IGD(Y,P ∗) = 1 |P ∗| X v∈P ∗ min y∈Y ∥v−y∥ 2
Inverted Generational Distance (IGD)IGD quantifies both the convergence and diversity by calculating the average Euclidean distance from a reference Pareto frontP ∗ to the nearest solution inY(Cai et al., 2021). IGD(Y,P ∗) = 1 |P ∗| X v∈P ∗ min y∈Y ∥v−y∥ 2. (31) Since the true Pareto front is unknown, we construct P ∗ by collecting non-dominated so- lutio...
2021
-
[6]
MS(Y) = vuut 1 K KX k=1 max y∈Y yk −min y∈Y yk 2 , (32) where yk represents the value of the k-th ob- jective for a solution vectory
Maximum Spread (MS)MS evaluates the extent of the coverage in the objective space, reflecting the algorithm’s capability to explore extreme trade-offs (Cunegatti et al., 2024). MS(Y) = vuut 1 K KX k=1 max y∈Y yk −min y∈Y yk 2 , (32) where yk represents the value of the k-th ob- jective for a solution vectory
2024
-
[7]
Preference Compliance (PC)PC measures the controllability of the alignment by com- puting the cosine similarity between the input preference weight vector w and the obtained reward vectory. PC = 1 N NX i=1 wi ·y i ∥wi∥2∥yi∥2 .(33) A higher PC score implies that the model’s generation precisely adheres to the directional guidance of the preference weights ...
2024
-
[8]
preachy") or generic. Or, the model exhibits “over-refusal
Do not include any explanation or text. Harmless System Prompt Role:You are a Senior Safety Alignment Officer. Your sole responsibility is to audit the AI model’s compliance with safety and ethical standards. Task:Scrutinize the response for toxicity, bias, illegal content, and potential harm. You must balance safety with helpfulness (avoiding false refus...
-
[9]
lack of humor
Do not include any explanation or text. Humor System Prompt Role:You are a Late-Night Show Head Writer and Comedy Critic. You have a sophisticated understanding of wit, timing, irony, and cultural context. Task:Evaluate the humor level of the AI’s response. Note: Only penalize "lack of humor" if the user explicitly asked for it or the context invites it. ...
-
[10]
rotations
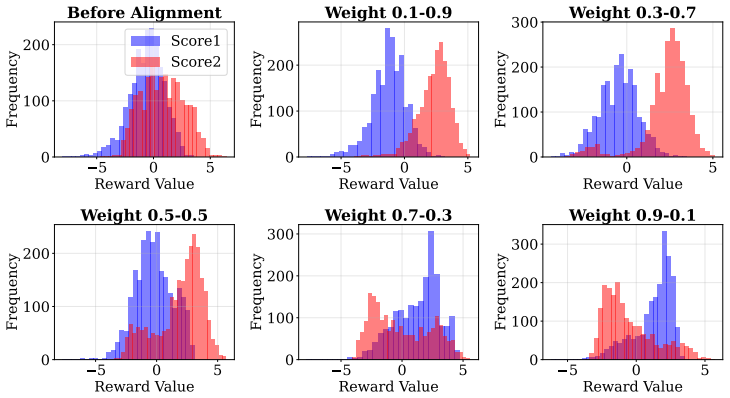
Do not include any explanation or text. C Additional Results In this section, we provide some additional results. We visualize the reward distribution dynamics in Figure 10. As the weight vector interpolates from (0.1,0.9) to (0.9,0.1) , we observe a clear, mono- tonic translation in probability mass: increasing a specific preference weight consistently p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.