Recognition: 1 theorem link
· Lean TheoremAttention, May I Have Your Decision? Localizing Generative Choices in Diffusion Models
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
Self-attention layers localize the implicit decisions that resolve ambiguous prompts in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
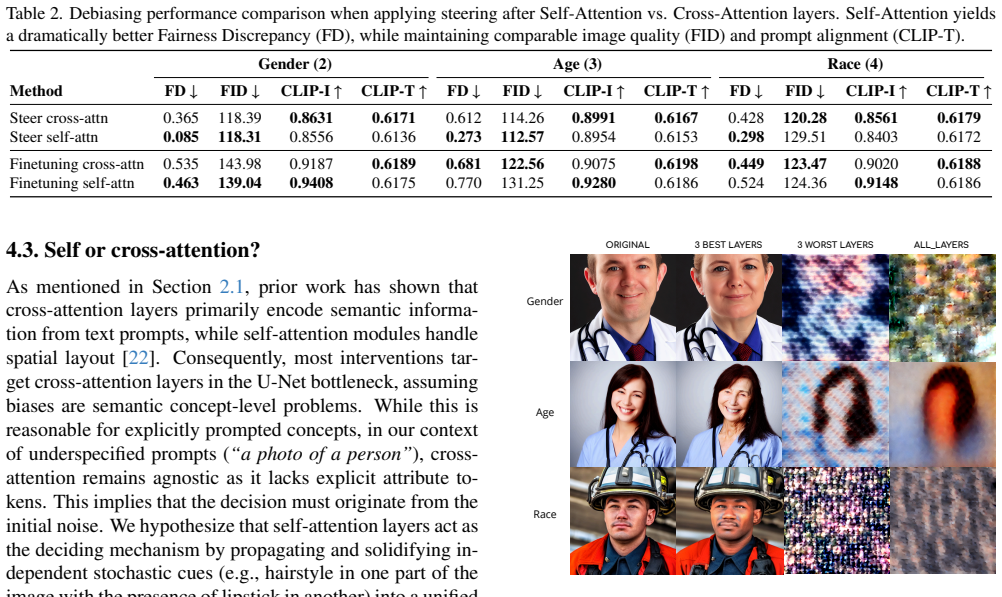
Text-to-image diffusion models make implicit generative decisions for ambiguous prompts principally inside their self-attention layers. A probing-based localization method ranks layers by attribute separability and identifies self-attention blocks as the highest-ranking sites. Targeted edits applied only to this small subset of layers yield stronger debiasing performance and fewer unintended artifacts than existing state-of-the-art steering approaches.
What carries the argument
Probing-based localization that ranks layers according to their attribute separability for concepts, isolating self-attention layers as the dominant sites for resolving implicit generative choices.
If this is right
- Interventions can be restricted to a small number of self-attention layers while still altering implicit choices.
- ICM outperforms prior steering methods on debiasing tasks with reduced visual artifacts.
- Explicit conditioning from the prompt can be kept separate from the implicit decision process during editing.
- Fewer layers need modification, lowering the computational cost of precise generative control.
Where Pith is reading between the lines
- The same localization approach could be applied to other generative architectures to find their implicit decision points.
- Targeted layer edits might support fine-grained image editing tasks that current global methods cannot achieve cleanly.
- Auditing self-attention layers could reveal where models systematically inject biases for particular ambiguous attributes.
Load-bearing premise
The probing method correctly isolates layers that handle implicit decisions separately from explicit prompt conditioning, and edits to those layers causally change the generated content without large side effects.
What would settle it
If applying the same magnitude of intervention to the identified self-attention layers produces no measurable shift in how ambiguous concepts are resolved, or yields the same level of artifacts as intervening on randomly chosen layers, the localization claim is falsified.
Figures














read the original abstract
Text-to-image diffusion models exhibit remarkable generative capabilities, yet their internal operations remain opaque, particularly when handling prompts that are not fully descriptive. In such scenarios, models must make implicit decisions to generate details not explicitly specified in the text. This work investigates the hypothesis that this decision-making process is not diffuse but is computationally localized within the model's architecture. While existing localization techniques focus on prompt-related interventions, we notice that such explicit conditioning may differ from implicit decisions. Therefore, we introduce a probing-based localization technique to identify the layers with the highest attribute separability for concepts. Our findings indicate that the resolution of ambiguous concepts is governed principally by self-attention layers, identifying them as the most effective point for intervention. Based on this discovery, we propose ICM (Implicit Choice-Modification) - a precise steering method that applies targeted interventions to a small subset of layers. Extensive experiments confirm that intervening on these specific self-attention layers yields superior debiasing performance compared to existing state-of-the-art methods, minimizing artifacts common to less precise approaches. The code is available at https://github.com/kzaleskaa/icm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that implicit generative decisions in text-to-image diffusion models for ambiguous prompts are localized primarily in self-attention layers, identified via a probing technique that ranks layers by attribute separability. It introduces the ICM intervention method targeting a small subset of these layers and reports superior debiasing performance over existing methods with fewer artifacts.
Significance. If the localization holds, the work would offer a more precise mechanism for steering implicit choices in diffusion models, improving control over debiasing and reducing side effects from broad interventions. The public code release supports reproducibility and allows direct verification of the reported gains.
major comments (2)
- [Abstract] The abstract asserts superior debiasing performance but supplies no quantitative metrics, baseline comparisons, or experimental controls; this absence prevents assessment of whether the central claim is supported by data.
- [Method (probing technique)] The probing-based localization ranks self-attention layers highest for attribute separability on ambiguous concepts, yet the method does not include controls that would isolate this from the layers' known generic role in cross-token feature aggregation (e.g., separability scores on fully-specified versus underspecified prompts, or on non-ambiguous attributes). Without such controls the inference that these layers are the privileged site for implicit decisions remains under-supported.
minor comments (1)
- [Method] Notation for the separability metric and the precise definition of 'attribute separability' should be formalized with an equation to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the presentation of our results and the rigor of our localization analysis. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts superior debiasing performance but supplies no quantitative metrics, baseline comparisons, or experimental controls; this absence prevents assessment of whether the central claim is supported by data.
Authors: We agree that the abstract's brevity limits immediate assessment of the quantitative claims. In the revised manuscript we will expand the abstract to include the primary performance metrics (e.g., the reported improvement in debiasing scores relative to baselines), a brief statement of the experimental controls used, and the key comparison against prior state-of-the-art methods. These additions will be drawn directly from the results already presented in the experimental section. revision: yes
-
Referee: [Method (probing technique)] The probing-based localization ranks self-attention layers highest for attribute separability on ambiguous concepts, yet the method does not include controls that would isolate this from the layers' known generic role in cross-token feature aggregation (e.g., separability scores on fully-specified versus underspecified prompts, or on non-ambiguous attributes). Without such controls the inference that these layers are the privileged site for implicit decisions remains under-supported.
Authors: The referee correctly identifies that additional controls would more convincingly isolate the role of self-attention layers in implicit generative choices from their general cross-token aggregation function. While our current probing focuses on attribute separability for ambiguous prompts, we acknowledge the value of the suggested comparisons. In the revised manuscript we will add new experiments reporting separability scores on fully-specified prompts and on non-ambiguous attributes, thereby providing the requested controls and strengthening the localization argument. revision: yes
Circularity Check
No circularity: empirical probing and intervention results are independent of inputs
full rationale
The paper introduces a probing technique that ranks layers by attribute separability on ambiguous concepts, reports that self-attention layers score highest, and validates the finding by showing superior debiasing when intervening on those layers. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on experimental measurements rather than reducing by construction to the probing inputs or prior self-references. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a probing-based localization technique to identify the layers with the highest attribute separability for concepts... self-attention layers... ICM (Implicit Choice-Modification)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On mechanistic knowledge lo- calization in text-to-image generative models
Samyadeep Basu, Keivan Rezaei, Priyatham Kattakinda, Vlad I Morariu, Nanxuan Zhao, Ryan A Rossi, Varun Man- junatha, and Soheil Feizi. On mechanistic knowledge lo- calization in text-to-image generative models. InForty-first International Conference on Machine Learning, 2024. 1, 2
2024
-
[2]
Morariu, Soheil Feizi, and Varun Manjunatha
Samyadeep Basu, Nanxuan Zhao, Vlad I. Morariu, Soheil Feizi, and Varun Manjunatha. Localizing and editing knowl- edge in text-to-image generative models. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
2024
-
[3]
Ledits++: Limitless image editing using text-to-image models
Manuel Brack, Felix Friedrich, Katharia Kornmeier, Linoy Tsaban, Patrick Schramowski, Kristian Kersting, and Apolin´ario Passos. Ledits++: Limitless image editing using text-to-image models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8861–8870, 2024. 2
2024
-
[4]
Dissect- ing bias in llms: A mechanistic interpretability perspective
Bhavik Chandna, Zubair Bashir, and Procheta Sen. Dissect- ing bias in llms: A mechanistic interpretability perspective. arXiv preprint arXiv: 2506.05166, 2025. 3
-
[5]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–10, 2023. 2
2023
-
[6]
Chieh-Yun Chen, Chiang Tseng, Li-Wu Tsao, and Hong-Han Shuai. A cat is a cat (not a dog!): Unraveling information mix-ups in text-to-image encoders through causal analysis and embedding optimization.Advances in Neural Informa- tion Processing Systems, 37:57944–57969, 2024. 2
2024
-
[7]
Diffusion in style
Martin Nicolas Everaert, Marco Bocchio, Sami Arpa, Sabine S¨usstrunk, and Radhakrishna Achanta. Diffusion in style. InProceedings of the ieee/cvf international conference on computer vision, pages 2251–2261, 2023. 1
2023
-
[8]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 5111–5120, 2024. 1, 2
2024
-
[9]
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image dif- fusion models via initial noise optimization.arXiv preprint arXiv: 2404.04650, 2024. 2
-
[10]
Debiasing text-to- image diffusion models.arXiv preprint arXiv: 2402.14577,
Ruifei He, Chuhui Xue, Haoru Tan, Wenqing Zhang, Yingchen Yu, Song Bai, and Xiaojuan Qi. Debiasing text-to- image diffusion models.arXiv preprint arXiv: 2402.14577,
-
[11]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. 4
2021
-
[13]
A style-based generator architecture for generative adversarial networks,
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks,
-
[14]
Train- ing unbiased diffusion models from biased dataset.arXiv preprint arXiv: 2403.01189, 2024
Yeongmin Kim, Byeonghu Na, Minsang Park, JoonHo Jang, Dongjun Kim, Wanmo Kang, and Il-Chul Moon. Train- ing unbiased diffusion models from biased dataset.arXiv preprint arXiv: 2403.01189, 2024. 3
-
[15]
Interpretable diffusion via information de- composition.arXiv preprint arXiv:2310.07972, 2023
Xianghao Kong, Ollie Liu, Han Li, Dani Yogatama, and Greg Ver Steeg. Interpretable diffusion via information de- composition.arXiv preprint arXiv:2310.07972, 2023. 2
-
[16]
Diffusion models already have a semantic latent space, 2023
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space, 2023. 2, 5
2023
-
[17]
Fairface: Face at- tribute dataset for balanced race, gender, and age, 2019
Kimmo K ¨arkk¨ainen and Jungseock Joo. Fairface: Face at- tribute dataset for balanced race, gender, and age, 2019. 5, 3
2019
-
[18]
Hang Li, Chengzhi Shen, Philip Torr, V olker Tresp, and Jindong Gu. Self-discovering interpretable diffusion latent directions for responsible text-to-image generation.arXiv preprint arXiv: 2311.17216, 2023. 2, 3
-
[19]
Self-discovering interpretable diffusion latent di- rections for responsible text-to-image generation, 2024
Hang Li, Chengzhi Shen, Philip Torr, V olker Tresp, and Jin- dong Gu. Self-discovering interpretable diffusion latent di- rections for responsible text-to-image generation, 2024. 5
2024
-
[20]
Senmao Li, Joost van de Weijer, Taihang Hu, Fahad Shah- baz Khan, Qibin Hou, Yaxing Wang, and Jian Yang. Get what you want, not what you don’t: Image content sup- pression for text-to-image diffusion models.arXiv preprint arXiv:2402.05375, 2024. 2
-
[21]
De- biasing algorithm through model adaptation.arXiv preprint arXiv:2310.18913, 2023
Tomasz Limisiewicz, David Mareˇcek, and Tom´aˇs Musil. De- biasing algorithm through model adaptation.arXiv preprint arXiv:2310.18913, 2023. 3
-
[22]
Towards understanding cross and self-attention in stable diffusion for text-guided image editing
Bingyan Liu, Chengyu Wang, Tingfeng Cao, Kui Jia, and Jun Huang. Towards understanding cross and self-attention in stable diffusion for text-guided image editing. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7817–7826, 2024. 2, 6
2024
-
[23]
Faster diffu- sion via temporal attention decomposition.arXiv preprint arXiv:2404.02747, 2024
Haozhe Liu, Wentian Zhang, Jinheng Xie, Francesco Fac- cio, Mengmeng Xu, Tao Xiang, Mike Zheng Shou, Juan- Manuel Perez-Rua, and J ¨urgen Schmidhuber. Faster diffu- sion via temporal attention decomposition.arXiv preprint arXiv:2404.02747, 2024. 1, 2
-
[24]
Locating and Editing Factual Associations in GPT, January 2023
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt. arXiv preprint arXiv: 2202.05262, 2022. 2, 3
-
[25]
Editing implicit assumptions in text-to-image diffusion models
Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text-to-image diffusion models. In 9 Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7053–7061, 2023. 1, 2
2023
-
[26]
Venkatesh Babu
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, and R. Venkatesh Babu. Bal- ancing act: Distribution-guided debiasing in diffusion mod- els, 2025. 2, 3, 5
2025
-
[27]
Cross-attention head position patterns can align with human visual concepts in text-to-image gen- erative models
Jungwon Park, Jungmin Ko, Dongnam Byun, Jangwon Suh, and Wonjong Rhee. Cross-attention head position patterns can align with human visual concepts in text-to-image gen- erative models. InThe Thirteenth International Conference on Learning Representations, 2025. 1
2025
-
[28]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations, 2024. 2, 5, 7
2024
-
[29]
Zhanyue Qin, Yue Ding, Deyuan Liu, Qingbin Liu, Junxian Cai, Xi Chen, Zhiying Tu, Dianhui Chu, Cuiyun Gao, and Dianbo Sui. Lftf: Locating first and then fine-tuning for mit- igating gender bias in large language models.arXiv preprint arXiv: 2505.15475, 2025. 3
-
[30]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 3
2021
-
[31]
High-resolution image syn- thesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. 1
2022
-
[32]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 5
2022
-
[33]
Finetuning text-to- image diffusion models for fairness.arXiv preprint arXiv:2311.07604, 2023
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Finetuning text-to- image diffusion models for fairness.arXiv preprint arXiv:2311.07604, 2023. 2, 3
-
[34]
Finetuning text-to-image diffusion models for fairness, 2024
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Finetuning text-to-image diffusion models for fairness, 2024. 5
2024
-
[35]
Dissecting and mitigating diffusion bias via mechanistic interpretability,
Yingdong Shi, Changming Li, Yifan Wang, Yongxiang Zhao, Anqi Pang, Sibei Yang, Jingyi Yu, and Kan Ren. Dissecting and mitigating diffusion bias via mechanistic interpretability,
-
[36]
Efficient fine- tuning and concept suppression for pruned diffusion models
Reza Shirkavand, Peiran Yu, Shangqian Gao, Gowthami Somepalli, Tom Goldstein, and Heng Huang. Efficient fine- tuning and concept suppression for pruned diffusion models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 18619–18629, 2025. 1
2025
-
[37]
Precise parameter localization for textual generation in diffusion models
Łukasz Staniszewski, Bartosz Cywi ´nski, Franziska Boenisch, Kamil Deja, and Adam Dziedzic. Precise parameter localization for textual generation in diffusion models. InThe Thirteenth International Conference on Learning Representations. 1
-
[38]
Sana: Efficient high-resolution im- age synthesis with linear diffusion transformers, 2024
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. Sana: Efficient high-resolution im- age synthesis with linear diffusion transformers, 2024. 2, 5, 7
2024
-
[39]
Localizing knowledge in diffu- sion transformers.arXiv preprint arXiv:2505.18832, 2025
Arman Zarei, Samyadeep Basu, Keivan Rezaei, Zihao Lin, Sayan Nag, and Soheil Feizi. Localizing knowledge in diffu- sion transformers.arXiv preprint arXiv:2505.18832, 2025. 2
-
[40]
Magnet: We never know how text-to-image diffusion models work, until we learn how vision-language models function.Advances in Neural Information Processing Systems, 37:57115–57149,
Chenyi Zhuang, Ying Hu, and Pan Gao. Magnet: We never know how text-to-image diffusion models work, until we learn how vision-language models function.Advances in Neural Information Processing Systems, 37:57115–57149,
-
[41]
A realistic photo of a doctor sitting and writing notes
2 10 Attention, May I Have Your Decision? Localizing Generative Choices in Diffusion Models Supplementary Material A. Implementation details on Steering vectors To calculate the steering vectors discussed in Section 3.2, we use a pipeline composed of a StandardScaler1 and a LogisticRegression2 model (with a maximum of 1000 iterations) on the pooled acti- ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.