Recognition: no theorem link
PromptEvolver: Prompt Inversion through Evolutionary Optimization in Natural-Language Space
Pith reviewed 2026-05-13 20:35 UTC · model grok-4.3
The pith
PromptEvolver recovers high-fidelity natural-language prompts for text-to-image models by evolving them with a genetic algorithm guided by a vision-language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PromptEvolver demonstrates that treating prompt inversion as an evolutionary search problem in natural language space, guided by vision-language model fitness signals, yields prompts that achieve higher reconstruction fidelity while remaining interpretable and works on black-box generators by using only their image outputs.
What carries the argument
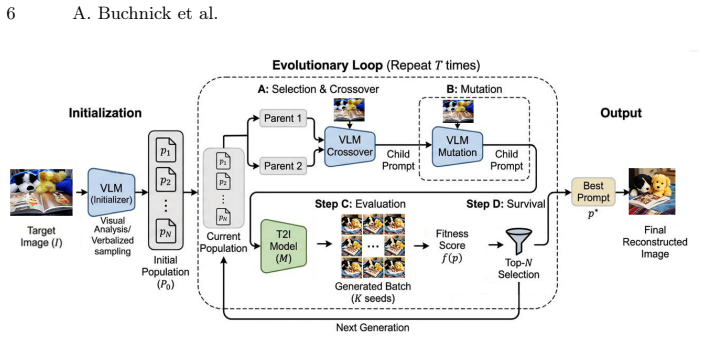
A genetic algorithm that evolves a population of text prompts, using a vision-language model to compute fitness based on image similarity to the target.
Load-bearing premise
The vision-language model must provide reliable, unbiased fitness signals for prompt quality across diverse scenes without the evolutionary search getting stuck in poor solutions.
What would settle it
If evolved prompts on standard benchmarks produce lower image similarity to targets than competing methods when measured by independent metrics such as CLIP score, the performance claim would not hold.
Figures




read the original abstract
Text-to-image generation has progressed rapidly, but faithfully generating complex scenes requires extensive trial-and-error to find the exact prompt. In the prompt inversion task, the goal is to recover a textual prompt that can faithfully reconstruct a given target image. Currently, existing methods frequently yield suboptimal reconstructions and produce unnatural, hard-to-interpret prompts that hinder transparency and controllability. In this work, we present PromptEvolver, a prompt inversion approach that generates natural-language prompts while achieving high-fidelity reconstructions of the target image. Our method uses a genetic algorithm to optimize the prompt, leveraging a strong vision-language model to guide the evolution process. Importantly, it works on black-box generation models by requiring only image outputs. Finally, we evaluate PromptEvolver across multiple prompt inversion benchmarks and show that it consistently outperforms competing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PromptEvolver, a prompt inversion method for text-to-image generation that applies a genetic algorithm to evolve natural-language prompts. A vision-language model supplies fitness signals based on image-to-image similarity from black-box generator outputs, with the goal of recovering high-fidelity, interpretable prompts. The work evaluates the approach on multiple prompt inversion benchmarks and claims consistent outperformance relative to prior methods.
Significance. If the results hold, the method offers a practical black-box technique for prompt inversion that preserves natural language, potentially improving transparency and controllability in generative models. The evolutionary search in discrete text space is a reasonable direction for avoiding the unnatural outputs common in gradient-based inversion. Significance is limited by the absence of detailed validation that the VLM oracle supplies reliable gradients in prompt space for complex scenes.
major comments (3)
- [§3] §3 (Method): The fitness function is defined solely via VLM similarity on generated images, yet no analysis or controls are provided for known VLM biases and shortcut behaviors on intricate scenes; this directly undermines the claim that genetic operators can reliably navigate toward faithful reconstructions rather than VLM-exploiting local optima.
- [§4] §4 (Experiments): The central claim of consistent outperformance is asserted without reported quantitative metrics, baseline implementations, standard deviations, or statistical tests in the benchmark tables; this absence makes it impossible to verify whether the data support the outperformance statement.
- [§4.3] §4.3 (Ablations): No ablation on population size, mutation rate, or VLM choice is presented, leaving unclear whether performance gains derive from the evolutionary framework or from other unexamined factors.
minor comments (2)
- [Abstract] Abstract: Adding one or two concrete performance numbers (e.g., similarity-score deltas) would make the outperformance claim more informative.
- [§5] §5 (Discussion): A brief limitations paragraph addressing VLM dependency and potential degeneracy on out-of-distribution scenes would improve completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will make revisions to improve the rigor of the analysis and experiments.
read point-by-point responses
-
Referee: [§3] §3 (Method): The fitness function is defined solely via VLM similarity on generated images, yet no analysis or controls are provided for known VLM biases and shortcut behaviors on intricate scenes; this directly undermines the claim that genetic operators can reliably navigate toward faithful reconstructions rather than VLM-exploiting local optima.
Authors: We agree that VLM biases represent a potential concern for the fitness signal. In the revised manuscript we will add a new subsection in §3 that discusses documented VLM biases (texture bias, co-occurrence shortcuts) and presents control experiments on synthetic scenes engineered to trigger these behaviors. We will also report the correlation between VLM similarity scores and human preference ratings on a held-out set of reconstructions to quantify oracle reliability. revision: yes
-
Referee: [§4] §4 (Experiments): The central claim of consistent outperformance is asserted without reported quantitative metrics, baseline implementations, standard deviations, or statistical tests in the benchmark tables; this absence makes it impossible to verify whether the data support the outperformance statement.
Authors: The benchmark tables in §4 already contain quantitative metrics (CLIP similarity, LPIPS, human preference rates) and direct comparisons against published baselines. However, we acknowledge that standard deviations and formal statistical tests were not emphasized. In the revision we will augment the tables with standard deviations computed over five independent runs and add paired statistical tests (Wilcoxon signed-rank) with p-values to substantiate the outperformance claims. We will also clarify baseline re-implementations by citing the exact public code versions used. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): No ablation on population size, mutation rate, or VLM choice is presented, leaving unclear whether performance gains derive from the evolutionary framework or from other unexamined factors.
Authors: We will expand §4.3 with the requested ablations. New experiments will vary population size (20, 50, 100), mutation rate (0.05–0.5), and VLM backbone (CLIP, BLIP-2, LLaVA) while keeping all other components fixed. These results will be presented in additional tables and figures to isolate the contribution of the evolutionary operators. revision: yes
Circularity Check
No circularity: empirical search procedure with external oracles
full rationale
The paper presents PromptEvolver as a genetic algorithm that optimizes natural-language prompts by querying external black-box vision-language models and image generators for fitness signals. No derivation chain, equations, fitted parameters, or predictions are described that could reduce to inputs by construction. The central claim is an empirical performance comparison on benchmarks, relying on the standard assumption that the oracles provide usable signals; this is not a self-referential mathematical reduction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The method is self-contained as an algorithmic proposal without internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alaluf, Y., Richardson, E., Metzer, G., Cohen-Or, D.: A neural space-time repre- sentationfortext-to-imagepersonalization.ACMTransactionsonGraphics(TOG) 42(6), 1–10 (2023)
work page 2023
-
[2]
Bermano, A.: Domain-agnostic tuning-encoder for fast personalization of text- to-image models
Arar, M., Gal, R., Atzmon, Y., Chechik, G., Cohen-Or, D., Shamir, A., H. Bermano, A.: Domain-agnostic tuning-encoder for fast personalization of text- to-image models. In: SIGGRAPH Asia 2023 Conference Papers. pp. 1–10 (2023)
work page 2023
-
[3]
Text Reading, and Beyond2(1), 1 (2023)
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization. Text Reading, and Beyond2(1), 1 (2023)
work page 2023
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brack, M., Friedrich, F., Kornmeier, K., Tsaban, L., Schramowski, P., Kersting, K., Passos, A.: Ledits++: Limitless image editing using text-to-image models. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8861–8870 (2024)
work page 2024
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
work page 2021
-
[7]
Croitoru, F.A., Hondru, V., Ionescu, R.T., Shah, M.: Reverse stable diffusion: What prompt was used to generate this image? Computer Vision and Image Un- derstanding249, 104210 (2024)
work page 2024
-
[8]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
work page 2023
-
[9]
Dehouche, N., Dehouche, K.: What’s in a text-to-image prompt? the potential of stable diffusion in visual arts education. Heliyon9(6) (2023)
work page 2023
-
[10]
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023)
-
[11]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. arXiv preprint arXiv:2208.01618 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
In: European Conference on Com- puter Vision
Garibi, D., Patashnik, O., Voynov, A., Averbuch-Elor, H., Cohen-Or, D.: Renoise: Real image inversion through iterative noising. In: European Conference on Com- puter Vision. pp. 395–413. Springer (2024)
work page 2024
-
[13]
Goldberg, D.E., Deb, K.: A comparative analysis of selection schemes used in geneticalgorithms.In:Foundationsofgeneticalgorithms,vol.1,pp.69–93.Elsevier (1991)
work page 1991
-
[14]
Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X., Liu, G., Bian, J., Yang, Y.: Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532 (2023)
-
[15]
arXiv preprint arXiv:2403.19103 2(5) (2024)
He, Y., Robey, A., Murata, N., Jiang, Y., Williams, J., Pappas, G.J., Hassani, H., Mitsufuji, Y., Salakhutdinov, R., Kolter, J.Z.: Automated black-box prompt engi- neering for personalized text-to-image generation. arXiv preprint arXiv:2403.19103 2(5) (2024)
-
[16]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022) PromptEvolver 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Journal of Artificial Intelligence Research47, 853–899 (2013)
Hodosh, M., Young, P., Hockenmaier, J.: Framing image description as a rank- ing task: Data, models and evaluation metrics. Journal of Artificial Intelligence Research47, 853–899 (2013)
work page 2013
-
[18]
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021).https://doi.org/10.5281/zenodo.5143773,https://doi. org/10.5281/zenodo.5143773, if you use this software, please cite it as below
-
[19]
arXiv preprint arXiv:2505.08622 (2025)
Kim, D.,Bae, M.,Shim,K.,Shim,B.:Visuallyguideddecoding:Gradient-freehard prompt inversion with language models. arXiv preprint arXiv:2505.08622 (2025)
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1931–1941 (2023)
work page 1931
-
[21]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Advances in Neural Information Processing Systems36, 30146–30166 (2023)
Li, D., Li, J., Hoi, S.: Blip-diffusion: Pre-trained subject representation for con- trollable text-to-image generation and editing. Advances in Neural Information Processing Systems36, 30146–30166 (2023)
work page 2023
-
[23]
Li, J., Li, D., Savarese, S., Hoi, S.C.H.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International Conference on Machine Learning (2023),https://api.semanticscholar.org/ CorpusID:256390509
work page 2023
-
[24]
arXiv preprint arXiv:2506.03067 (2025)
Li, M., Zhang, G., Wang, Z., Tao, G., Pan, S., Cartwright, R., Zhai, J., Ma, S.: Editor: Effective and interpretable prompt inversion for text-to-image diffusion models. arXiv preprint arXiv:2506.03067 (2025)
-
[25]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li,Z.,Wu,X.,Du,H.,Liu,F.,Nghiem,H.,Shi,G.:Asurveyofstateoftheartlarge vision language models: Benchmark evaluations and challenges. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1587–1606 (2025)
work page 2025
-
[26]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
work page 2014
-
[27]
In: Proceedings of the IEEE international conference on computer vision
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of the IEEE international conference on computer vision. pp. 3730– 3738 (2015)
work page 2015
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mahajan, S., Rahman, T., Yi, K.M., Sigal, L.: Prompting hard or hardly prompt- ing: Prompt inversion for text-to-image diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6808– 6817 (2024)
work page 2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mo, W., Zhang, T., Bai, Y., Su, B., Wen, J.R., Yang, Q.: Dynamic prompt opti- mizing for text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26627–26636 (2024)
work page 2024
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text inver- sion for editing real images using guided diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6038–6047 (2023)
work page 2023
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pan, Z., Gherardi, R., Xie, X., Huang, S.: Effective real image editing with acceler- ated iterative diffusion inversion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15912–15921 (2023) 18 A. Buchnick et al
work page 2023
-
[32]
pharmapsychotic: CLIP interrogator.https://github.com/pharmapsychotic/ clip-interrogator(2022)
work page 2022
-
[33]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qiu, Y., Wang, A., Li, C., Huang, H., Zhou, G., Zhao, Q.: Steps: sequential prob- ability tensor estimation for text-to-image hard prompt search. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28640–28650 (2025)
work page 2025
-
[34]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
work page 2022
-
[36]
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth:Finetuningtext-to-imagediffusionmodelsforsubject-drivengeneration.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22500–22510 (2023)
work page 2023
-
[37]
Adversarial diffusion dis- tillation
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. arXiv preprint arXiv:2311.17042 (2023)
-
[38]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes,T.,Jitsev,J.,Komatsuzaki,A.:Laion-400m:Opendatasetofclip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
In: USENIX Security Symposium (USENIX Security)
Shen, X., Qu, Y., Backes, M., Zhang, Y.: Prompt Stealing Attacks Against Text-to- Image Generation Models. In: USENIX Security Symposium (USENIX Security). USENIX (2024)
work page 2024
-
[40]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Srinivas, M., Patnaik, L.M.: Genetic algorithms: A survey. computer27(6), 17–26 (2002)
work page 2002
-
[42]
IEEE transactions on pattern analysis and machine intelligence45(1), 539–559 (2022)
Stefanini, M., Cornia, M., Baraldi, L., Cascianelli, S., Fiameni, G., Cucchiara, R.: From show to tell: A survey on deep learning-based image captioning. IEEE transactions on pattern analysis and machine intelligence45(1), 539–559 (2022)
work page 2022
-
[43]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 1921–1930 (2023)
work page 1921
-
[44]
P+: Extended textual conditioning in text-to-image generation.arXiv preprint arXiv:2303.09522, 2023
Voynov, A., Chu, Q., Cohen-Or, D., Aberman, K.: p+: Extended textual condi- tioning in text-to-image generation. arXiv preprint arXiv:2303.09522 (2023)
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wallace, B., Gokul, A., Naik, N.: Edict: Exact diffusion inversion via coupled trans- formations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22532–22541 (2023)
work page 2023
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wei, Y., Zhang, Y., Ji, Z., Bai, J., Zhang, L., Zuo, W.: Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 15943–15953 (2023)
work page 2023
-
[47]
Advances in Neural Information Processing Systems36, 51008–51025 (2023)
Wen,Y.,Jain,N.,Kirchenbauer,J.,Goldblum,M.,Geiping,J.,Goldstein,T.:Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. Advances in Neural Information Processing Systems36, 51008–51025 (2023)
work page 2023
-
[48]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., et al.: Sana: Efficient high-resolution image synthesis with linear diffusion transformers. arXiv preprint arXiv:2410.10629 (2024) PromptEvolver 19
work page internal anchor Pith review arXiv 2024
-
[49]
Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., Zou, J.: When and why vision-language models behave like bags-of-words, and what to do about it? In: The Eleventh International Conference on Learning Representations
- [50]
-
[51]
SPRIG: Improving Large Language Model Performance by System Prompt Optimization
Zhang, L., Ergen, T., Logeswaran, L., Lee, M., Jurgens, D.: Sprig: Improving large language model performance by system prompt optimization. arXiv preprint arXiv:2410.14826 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Zhao, J., Wang, Z., Yang, F.: Genetic prompt search via exploiting language model probabilities. In: IJCAI. pp. 5296–5305 (2023) 20 A. Buchnick et al. Supplementary Material A Implementation Details Across the different experiments of PromptEvolver, we use the following de- faults: N (population size) = 10, T (number of generations) = 5, K (number of imag...
work page 2023
-
[58]
0.XX">detailed prompt text here</prompt> <prompt probability=
Add important details - colors, textures, atmosphere, any text visible Combine these observations into a cohesive, detailed prompt. Each prompt should be approximately 50 words - detailed and information-dense. Include all important visual elements - do not omit key subjects, objects, or setting details. Diversity requirements: - Each prompt should emphas...
-
[59]
Identify the main subject(s) - what is the primary focus?
-
[60]
Describe the setting/environment - where is this taking place?
-
[61]
Note the composition - how are elements arranged? What perspective?
-
[62]
Describe the spatial layout - where are subjects positioned (left/right/center, top/bottom, foreground/background)? Include relative positions of objects to each other
-
[63]
Capture the lighting - what is the light source, quality, mood?
-
[64]
Identify the style - is it photorealistic, artistic, rendered, etc.?
-
[65]
0.XX">detailed prompt text here</prompt> <prompt probability=
Add important details - colors, textures, atmosphere, any text visible Combine these observations into a cohesive, detailed prompt. Integrate spatial positioning naturally. Each prompt should be approximately 60 words - detailed and information-dense. Include all important visual elements - do not omit key subjects, objects, or setting details. Diversity ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.