Recognition: no theorem link
From Hallucination to Structure Snowballing: The Alignment Tax of Constrained Decoding in LLM Reflection
Pith reviewed 2026-05-10 18:59 UTC · model grok-4.3
The pith
Imposing structural constraints on LLM self-reflection triggers a new failure mode called structure snowballing instead of reducing hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Enforcing structured reflection purely through Outlines-based constrained decoding does not disrupt hallucination snowballing. The cognitive load of satisfying strict formatting rules instead produces structure snowballing, in which the model achieves near-perfect syntactic alignment yet fails to detect or resolve deeper semantic errors.
What carries the argument
Structure snowballing, the process in which the effort to meet formatting constraints causes recursive justification of format compliance rather than correction of reasoning errors.
If this is right
- Structured decoding by itself cannot substitute for external critics or tools in autonomous LLM workflows.
- High syntactic compliance in agent outputs does not indicate reliable semantic reasoning.
- Autonomous self-correction systems incur an alignment tax when strict format constraints are added without additional training.
- Error propagation can shift from content hallucinations to format-driven recursive justifications.
Where Pith is reading between the lines
- Hybrid systems that apply lighter constraints while preserving model capacity for content might reduce the observed tradeoff.
- The same tension between format and content could appear in other constrained generation settings beyond reflection.
- Testing whether larger models or coarser constraint levels weaken structure snowballing would clarify the role of capacity limits.
Load-bearing premise
The formatting demands themselves cause the drop in semantic error correction, rather than other factors like model size, prompt wording, or the specific method used to identify errors.
What would settle it
An experiment in which the same reflection prompt is used without the constrained decoding rules and the model then succeeds at detecting and fixing semantic errors would show that structure snowballing is not the main cause.
Figures

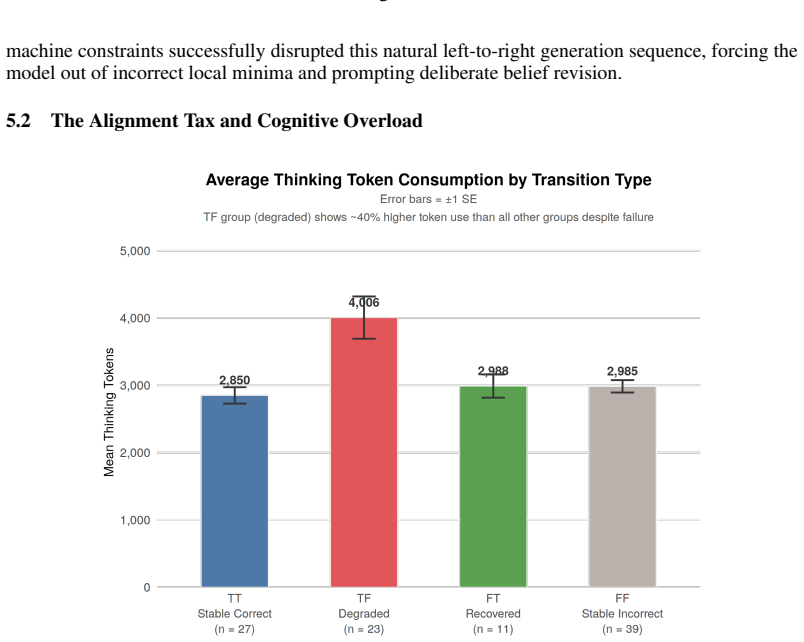
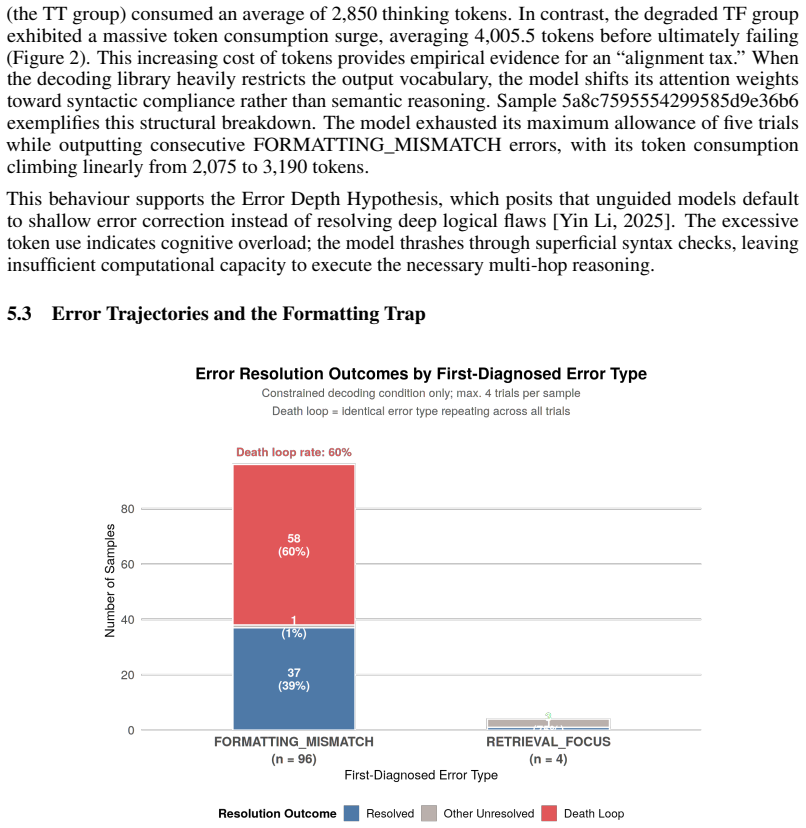
read the original abstract
Intrinsic self-correction in Large Language Models (LLMs) frequently fails in open-ended reasoning tasks due to ``hallucination snowballing,'' a phenomenon in which models recursively justify early errors during free-text reflection. While structured feedback can mitigate this issue, existing approaches often rely on externally trained critics or symbolic tools, reducing agent autonomy. This study investigates whether enforcing structured reflection purely through Outlines-based constrained decoding can disrupt error propagation without additional training. Evaluating an 8-billion-parameter model (Qwen3-8B), we show that simply imposing structural constraints does not improve self-correction performance. Instead, it triggers a new failure mode termed ``structure snowballing.'' We find that the cognitive load required to satisfy strict formatting rules pushes the model into formatting traps. This observation helps explain why the agent achieves near-perfect superficial syntactic alignment yet fails to detect or resolve deeper semantic errors. These findings expose an ``alignment tax'' inherent to constrained decoding, highlighting a tension between structural granularity and internal model capacity in autonomous workflows. Code and raw logs are available in the GitHub repository: https://github.com/hongxuzhou/agentic_llm_structured_self_critique.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that enforcing structured reflection in LLMs via Outlines-based constrained decoding fails to improve self-correction on an 8B model (Qwen3-8B) and instead induces a new failure mode called 'structure snowballing,' in which the cognitive load of satisfying strict formatting rules causes models to achieve near-perfect syntactic compliance while failing to detect or resolve semantic errors, revealing an 'alignment tax' of constrained decoding.
Significance. If substantiated with rigorous metrics and controls, the identification of structure snowballing as a distinct failure mode would be significant for autonomous LLM agent design, as it highlights a tension between syntactic constraints and semantic reasoning capacity that could inform more effective hybrid approaches to structured self-critique without external critics.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim of 'no performance gain' and 'near-perfect superficial syntactic alignment' is unsupported by any reported quantitative metrics, success rates, error counts, or baseline comparisons for the Qwen3-8B experiments, which is load-bearing for asserting that constrained decoding triggers structure snowballing rather than improving reflection.
- [Abstract] Abstract: the explanatory mechanism that 'cognitive load required to satisfy strict formatting rules pushes the model into formatting traps' lacks isolating evidence such as ablations on constraint granularity, prompt variations, or proxies for load (e.g., generation entropy), making the causal link to persistent semantic errors speculative and central to the alignment-tax conclusion.
- [Results / Discussion] Results/Discussion: without details on how semantic versus syntactic errors were identified or measured, or any tables/figures showing pre- and post-reflection performance, the distinction between syntactic compliance and semantic failure cannot be assessed, undermining the claim that structure snowballing is a new, distinct phenomenon from hallucination snowballing.
minor comments (2)
- [Abstract] The GitHub link for code and raw logs is provided but the manuscript does not describe the exact prompts, grammar definitions used in Outlines, or the task distribution, which would aid reproducibility.
- [Introduction] The term 'structure snowballing' is introduced without a formal definition or comparison to related concepts like hallucination snowballing in the introduction, which could be clarified for readers.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments identify key areas where additional quantitative detail and methodological transparency will strengthen the manuscript. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim of 'no performance gain' and 'near-perfect superficial syntactic alignment' is unsupported by any reported quantitative metrics, success rates, error counts, or baseline comparisons for the Qwen3-8B experiments, which is load-bearing for asserting that constrained decoding triggers structure snowballing rather than improving reflection.
Authors: We agree that the claims require explicit quantitative support. The revised manuscript will expand the Evaluation section with success rates, error counts, and direct baseline comparisons (constrained vs. unconstrained) for the Qwen3-8B experiments to substantiate the absence of performance gains and the high rate of syntactic compliance. revision: yes
-
Referee: [Abstract] Abstract: the explanatory mechanism that 'cognitive load required to satisfy strict formatting rules pushes the model into formatting traps' lacks isolating evidence such as ablations on constraint granularity, prompt variations, or proxies for load (e.g., generation entropy), making the causal link to persistent semantic errors speculative and central to the alignment-tax conclusion.
Authors: The proposed mechanism is derived from patterns observed across the generation traces. We acknowledge that stronger isolating evidence would improve the causal argument. In revision we will add targeted ablations varying constraint granularity and prompt phrasing, along with discussion of generation entropy as a load proxy, to better ground the alignment-tax interpretation. revision: partial
-
Referee: [Results / Discussion] Results/Discussion: without details on how semantic versus syntactic errors were identified or measured, or any tables/figures showing pre- and post-reflection performance, the distinction between syntactic compliance and semantic failure cannot be assessed, undermining the claim that structure snowballing is a new, distinct phenomenon from hallucination snowballing.
Authors: We will insert a new subsection describing the annotation protocol used to classify semantic versus syntactic errors, with concrete examples. We will also add tables and figures that report pre- and post-reflection performance broken down by error type, enabling readers to evaluate the claimed distinction between structure snowballing and hallucination snowballing. revision: yes
Circularity Check
No circularity: empirical comparison of constrained vs. unconstrained reflection with no derivations or self-referential reductions
full rationale
The paper reports direct experimental results on an 8B model comparing structured reflection (via Outlines constrained decoding) against free-text reflection. The core observation—that constraints yield near-perfect syntax but no semantic error resolution, labeled 'structure snowballing'—is presented as an empirical outcome rather than a derived quantity. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear in the abstract or described claims. The attribution to 'cognitive load' is interpretive but does not reduce the reported performance metrics to the inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The model's internal capacity is sufficient to handle both strict formatting constraints and semantic reasoning simultaneously during reflection.
invented entities (1)
-
structure snowballing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/2212.07919. arXiv:2212.07919 [cs]. Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large Language Models Cannot Self-Correct Reasoning Yet, March
-
[2]
Large Language Models Cannot Self-Correct Reasoning Yet
URL http://arxiv.org/abs/2310.01798. arXiv:2310.01798 [cs]. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- Refine: Iterative Refinement with S...
work page internal anchor Pith review arXiv
-
[3]
Self-Refine: Iterative Refinement with Self-Feedback
URL http://arxiv.org/abs/ 2303.17651. arXiv:2303.17651 [cs]. Sewon Min, Eric Wallace, Sameer Singh, Matt Gardner, Hannaneh Hajishirzi, and Luke Zettlemoyer. Compositional Questions Do Not Necessitate Multi-hop Reasoning. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4249–4257, Florence, Italy,
work page internal anchor Pith review arXiv
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1416. URL https://aclanthology.org/P19-1416. Deepak Nathani, David Wang, Liangming Pan, and William Wang. MAF: Multi-Aspect Feedback for Improving Reasoning in Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6591–6616, Singapore,
-
[5]
doi: 10.18653/v1/2023.emnlp-main.407
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.407. URL https: //aclanthology.org/2023.emnlp-main.407. Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. REFINER: Reasoning Feedback on Intermediate Representations,
-
[6]
Refiner: Reasoning feedback on intermediate representations
URL https://arxiv.org/abs/2304.01904. Version Number:
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
URL http://arxiv.org/abs/2303.11366. arXiv:2303.11366 [cs]. Gladys Tyen, Hassan Mansoor, Victor C ˘arbune, Peter Chen, and Tony Mak. LLMs cannot find reasoning errors, but can correct them given the error location, June
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL http://arxiv. org/abs/2311.08516. arXiv:2311.08516 [cs]. Brandon T. Willard and Rémi Louf. Efficient Guided Generation for Large Language Models, August
-
[9]
Efficient Guided Generation for Large Language Models
URLhttp://arxiv.org/abs/2307.09702. arXiv:2307.09702 [cs]. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, J...
work page internal anchor Pith review arXiv
-
[10]
URL http://arxiv.org/abs/2505.09388. arXiv:2505.09388 [cs]. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–238...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URLhttp://aclweb.org/anthology/D18-1259. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models, December
-
[12]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
URLhttp://arxiv.org/abs/2305.10601. arXiv:2305.10601 [cs]. 14 Yin Li. Decomposing LLM Self-Correction: The Accuracy-Correction Paradox and Error Depth Hypothesis, December
work page internal anchor Pith review arXiv
-
[13]
URL http://arxiv.org/abs/2601.00828. arXiv:2601.00828 [cs]. Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A. Smith. How Language Model Hallucinations Can Snowball, May
-
[14]
How language model hallucinations can snowball
URL http://arxiv.org/abs/2305.13534. arXiv:2305.13534 [cs]. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, December
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
URL http: //arxiv.org/abs/2306.05685. arXiv:2306.05685 [cs]. 15
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.