Recognition: 2 theorem links
· Lean TheoremHiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning
Pith reviewed 2026-05-10 18:23 UTC · model grok-4.3
The pith
HiPolicy resolves the trade-off in robotic imitation learning by jointly predicting action chunks at multiple frequencies and adapting execution via uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
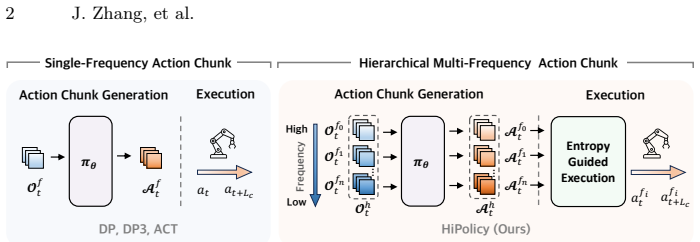
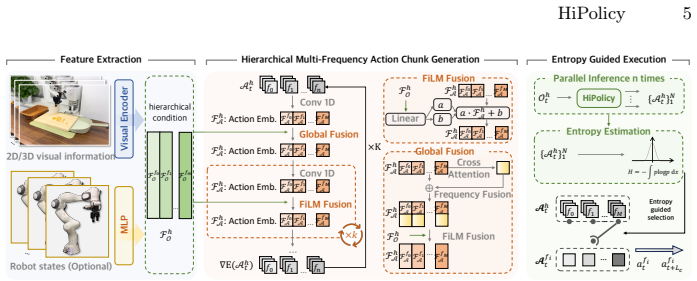
The paper establishes that jointly predicting and fusing hierarchical action chunks at multiple frequencies, combined with entropy-guided execution that balances long-horizon planning against fine control based on uncertainty, overcomes the limitations of fixed-frequency approaches in imitation learning. By aligning historical observations to each frequency for feature extraction and generation, the framework maintains coarse high-level plans alongside precise reactive motions. This enables consistent performance gains and efficiency improvements when integrated into 2D and 3D generative policies on diverse simulated and real-world tasks.
What carries the argument
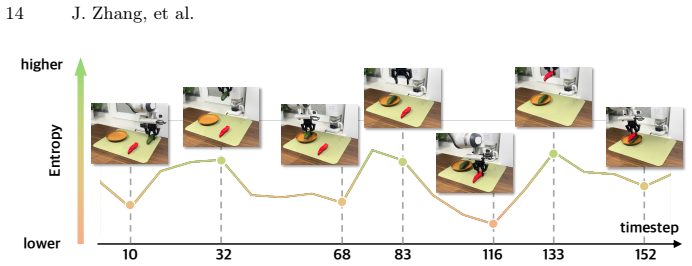
The hierarchical multi-frequency action chunking framework that jointly generates chunks at varying frequencies, fuses aligned historical features, and uses entropy to adaptively select execution horizon.
If this is right
- Consistent performance improvements when integrated into existing 2D and 3D generative policies.
- Significant gains in execution efficiency across tasks.
- Better handling of both coarse long-horizon plans and precise reactive motions.
- Adaptive balancing of planning depth and control reactivity driven by action uncertainty.
Where Pith is reading between the lines
- The multi-frequency fusion idea could extend to other sequential control domains where actions occur at mismatched time scales, such as navigation or assembly planning.
- Entropy guidance offers a lightweight alternative to manual horizon tuning that might simplify deployment on new robot hardware.
- The approach suggests that uncertainty signals can serve as a general mechanism for switching between open-loop planning and closed-loop correction in policy learning.
Load-bearing premise
That jointly predicting and fusing multi-frequency action chunks plus entropy-guided execution will reliably balance long-horizon dependencies with fine-grained control without introducing instability or requiring extensive per-task tuning.
What would settle it
A direct comparison on the same simulated benchmarks and real manipulation tasks where the HiPolicy version shows no gain or a drop in success rate and execution speed relative to the fixed-frequency baseline policies.
Figures



read the original abstract
Robotic imitation learning faces a fundamental trade-off between modeling long-horizon dependencies and enabling fine-grained closed-loop control. Existing fixed-frequency action chunking approaches struggle to achieve both. Building on this insight, we propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies to capture both coarse high-level plans and precise reactive motions. We extract and fuse hierarchical features from history observations aligned to each frequency for multi-frequency chunk generation, and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. Experiments on diverse simulated benchmarks and real-world manipulation tasks show that HiPolicy can be seamlessly integrated into existing 2D and 3D generative policies, delivering consistent improvements in performance while significantly enhancing execution efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HiPolicy, a hierarchical multi-frequency action chunking framework for robotic imitation learning. It jointly predicts action sequences at different frequencies to capture coarse high-level plans and precise reactive motions, extracts and fuses hierarchical features from history observations aligned to each frequency, and introduces an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. The method is designed to integrate into existing 2D and 3D generative policies, with experiments on simulated benchmarks and real-world manipulation tasks claimed to show consistent performance improvements and enhanced execution efficiency.
Significance. If the results hold, this work could meaningfully advance imitation learning by addressing the core trade-off between long-horizon modeling and closed-loop reactivity through a hierarchical, multi-frequency approach. The entropy-guided adaptation offers a potentially general mechanism for dynamic chunk selection, and the seamless integration claim, if supported by strong ablations, would be a practical strength for the field.
major comments (2)
- [Method (entropy-guided execution)] The entropy-guided execution mechanism (described in the method) relies on the entropy signal from the generative policy's output distribution as a faithful uncertainty indicator that generalizes across sim-to-real gaps and task variations without per-task retuning. However, the manuscript provides no analysis or experiments demonstrating that the entropy threshold remains stable under distribution shift or that long chunks are not executed inappropriately when short corrections are needed, which directly undermines the central claim of reliable adaptive balancing and seamless integration.
- [Experiments] The experimental claims of 'consistent improvements' and 'significantly enhancing execution efficiency' on diverse benchmarks and real-world tasks lack reported quantitative metrics, error bars, ablation studies isolating the multi-frequency prediction and entropy components, or details on whether the entropy threshold was held fixed. This makes it impossible to evaluate the magnitude, statistical reliability, or generality of the gains relative to baselines.
minor comments (2)
- [Abstract] The abstract would be strengthened by naming specific tasks, baselines, and at least one key quantitative result to ground the performance claims.
- [Method] Notation for action frequencies and the entropy threshold should be defined explicitly with equations in the method section to clarify the free parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of HiPolicy to address the long-horizon versus reactivity trade-off in imitation learning. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting the current results.
read point-by-point responses
-
Referee: [Method (entropy-guided execution)] The entropy-guided execution mechanism (described in the method) relies on the entropy signal from the generative policy's output distribution as a faithful uncertainty indicator that generalizes across sim-to-real gaps and task variations without per-task retuning. However, the manuscript provides no analysis or experiments demonstrating that the entropy threshold remains stable under distribution shift or that long chunks are not executed inappropriately when short corrections are needed, which directly undermines the central claim of reliable adaptive balancing and seamless integration.
Authors: We acknowledge that the manuscript does not contain dedicated experiments analyzing entropy threshold stability under distribution shifts or explicit checks against inappropriate long-chunk execution during needed corrections. The entropy-guided mechanism is motivated by the observation that high entropy correlates with the need for reactive control, and our real-world results used a single fixed threshold after validation. However, we agree that stronger evidence is required to support the claim of reliable generalization. In the revised version we will add (i) plots of entropy trajectories across tasks and sim-to-real transfers, (ii) controlled tests where short corrective actions are required, and (iii) sensitivity analysis of the threshold value. These additions will directly address the concern. revision: yes
-
Referee: [Experiments] The experimental claims of 'consistent improvements' and 'significantly enhancing execution efficiency' on diverse benchmarks and real-world tasks lack reported quantitative metrics, error bars, ablation studies isolating the multi-frequency prediction and entropy components, or details on whether the entropy threshold was held fixed. This makes it impossible to evaluate the magnitude, statistical reliability, or generality of the gains relative to baselines.
Authors: We agree that the current presentation of results is insufficient for rigorous evaluation. While the manuscript reports performance on multiple simulated benchmarks and real-world tasks, it does not include full tables with means and standard deviations, error bars on all figures, or ablations that isolate the multi-frequency prediction from the entropy-guided execution. The entropy threshold was held fixed after a single validation pass, but this detail is not clearly stated. In the revision we will (i) expand all result tables to report mean ± std over at least three random seeds, (ii) add error bars to figures, (iii) provide new ablation studies that separately disable multi-frequency chunking and entropy guidance, and (iv) explicitly document the threshold selection procedure and its fixed use across all experiments. revision: yes
Circularity Check
No circularity: HiPolicy is an empirical architectural proposal without self-referential derivations
full rationale
The paper proposes a new hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies, fuses hierarchical features from observations, and uses entropy-guided execution to balance planning and reactivity. No equations, fitted parameters, or predictions are presented that reduce to their own inputs by construction. There are no self-citations invoked as load-bearing uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as novel derivations. The central claims rest on experimental validation across simulated and real-world tasks rather than any closed logical loop, making the work self-contained as an engineering contribution.
Axiom & Free-Parameter Ledger
free parameters (2)
- action frequencies
- entropy threshold
invented entities (1)
-
entropy-guided execution mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies... and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclearlow-frequency chunks capture long-horizon dependencies but lack the temporal resolution... high-frequency chunks offer fine-grained adjustments
Reference graph
Works this paper leans on
-
[1]
Andrychowicz, M., Raichuk, A., Stanek, P., Shipley, T., Debiak, H., Chociej, S., Durkaya, M., Sherborne, R., Trzciński, B., Tabaka, M., et al.: Learning dexterous in-hand manipulation. arXiv preprint arXiv:1808.00177 (2018)
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L.X., Tanner, J., Vuong, Q., Walling, A., Wang, H., Zhilinsky, U.:π0: A vision-language-action flow model for general robot control. ArXivabs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
The International Journal of Robotics Research44, 1684 – 1704 (2023),https://api.semanticscholar
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44, 1684 – 1704 (2023),https://api.semanticscholar. org/CorpusID:257378658
2023
-
[5]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Contributors, I.M.: Internvla-m1: A spatially guided vision-language-action frame- work for generalist robot policy. arXiv preprint arXiv:2510.13778 (2025)
work page internal anchor Pith review arXiv 2025
-
[6]
In: North American Chap- ter of the Association for Computational Linguistics (2019),https : / / api
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: North American Chap- ter of the Association for Computational Linguistics (2019),https : / / api . semanticscholar.org/CorpusID:52967399
2019
-
[7]
In: Conference on Robot Learning (CoRL)
Finn, C., Levine, S.: Learning to see, seeing to act: Emergent visual skills for robot manipulation. In: Conference on Robot Learning (CoRL). pp. 1–13 (2017)
2017
-
[8]
Current Opinion in Neurobiology16, 650–659 (2006),https: //api.semanticscholar.org/CorpusID:14748404
Flanagan, J.R., Bowman, M.C., Johansson, R.S.: Control strategies in object ma- nipulation tasks. Current Opinion in Neurobiology16, 650–659 (2006),https: //api.semanticscholar.org/CorpusID:14748404
2006
-
[9]
ArXivabs/2412.06782(2024),https://api.semanticscholar.org/CorpusID: 274610389
Gong, Z., Ding, P., Lyu, S., Huang, S., Sun, M., Zhao, W., Fan, Z., Wang, D.: Carp: Visuomotor policy learning via coarse-to-fine autoregressive prediction. ArXivabs/2412.06782(2024),https://api.semanticscholar.org/CorpusID: 274610389
-
[10]
ArXivabs/2506.05064(2025), https://api.semanticscholar.org/CorpusID:279244338
Guo, L., Xue, Z., Xu, Z., Xu, H.: Demospeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration. ArXivabs/2506.05064(2025), https://api.semanticscholar.org/CorpusID:279244338
-
[11]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachow...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: Proceedings of Robotics: Conference on Robot Learn- ing(CoRL) (2024) 16 J
Ke, T.W., Gkanatsios, N., Fragkiadaki, K.: 3d diffuser actor: Policy diffusion with 3d scene representations. In: Proceedings of Robotics: Conference on Robot Learn- ing(CoRL) (2024) 16 J. Zhang, et al
2024
-
[14]
In: 2019 International Conference on Robotics and Automation (ICRA)
Kelly, M., Sidrane, C., Driggs-Campbell, K., Kochenderfer, M.J.: Hg-dagger: Inter- active imitation learning with human experts. In: 2019 International Conference on Robotics and Automation (ICRA). pp. 8077–8083. IEEE (2019)
2019
-
[15]
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., Fagan, P.D., Hejna, J., Itkina, M., Lepert, M., Ma, Y.J., Miller, P.T., Wu, J., Belkhale, S., Dass, S., Ha, H., Jain, A., Lee, A., Lee, Y., Memmel, M., Park, S., Radosavovic, I., Wang, K., Zhan, A., Black, K., Chi, C., Ha...
2024
-
[16]
In: International Conference on Machine Learning
Kim, J., Kong, J., Son, J.: Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In: International Conference on Machine Learning. pp. 5530–5540. PMLR (2021)
2021
-
[17]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: Openvla: An open-source vision- language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: Conference on robot learning
Laskey, M., Lee, J., Fox, R., Dragan, A., Goldberg, K.: Dart: Noise injection for robust imitation learning. In: Conference on robot learning. pp. 143–156. PMLR (2017)
2017
-
[19]
Li, W., Zhang, R., Shao, R., He, J., Nie, L.: Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification. ArXivabs/2508.21046(2025),https://api.semanticscholar.org/CorpusID: 280949804
-
[20]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
ArXivabs/2505.07819 (2025),https://api.semanticscholar.org/CorpusID:278534675
Lu, Y., Tian, Y., Yuan, Z., Wang, X., Hua, P., Xue, Z., Xu, H.: H3dp: Triply- hierarchical diffusion policy for visuomotor learning. ArXivabs/2505.07819 (2025),https://api.semanticscholar.org/CorpusID:278534675
-
[22]
Nature Reviews Neuroscience25, 597–610 (2024).https://doi.org/10.1038/s41583- 024-00836-8
Miller, J.A., Constantinidis, C.: Timescales of learning in prefrontal cortex. Nature Reviews Neuroscience25, 597–610 (2024).https://doi.org/10.1038/s41583- 024-00836-8
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Mu, Y., Chen, T., Chen, Z., Peng, S., Lan, Z., Gao, Z., Liang, Z., Yu, Q., Zou, Y., Xu, M., Lin, L., Xie, Z., Ding, M., Luo, P.: Robotwin: Dual-arm robot benchmark with generative digital twins. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 27649–27660 (June 2025)
2025
-
[24]
In: Proceedings of the AAAI conference on artificial intelligence
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[25]
Advances in neural information processing systems29(2016) HiPolicy 17
Pu, Y., Gan, Z., Henao, R., Yuan, X., Li, C., Stevens, A., Carin, L.: Variational autoencoder for deep learning of images, labels and captions. Advances in neural information processing systems29(2016) HiPolicy 17
2016
-
[26]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[27]
In: Proceedings of the fourteenth in- ternational conference on artificial intelligence and statistics
Ross, S., Gordon, G., Bagnell, D.: A reduction of imitation learning and struc- tured prediction to no-regret online learning. In: Proceedings of the fourteenth in- ternational conference on artificial intelligence and statistics. pp. 627–635. JMLR Workshop and Conference Proceedings (2011)
2011
-
[28]
Shannon, C.E.: A mathematical theory of communication. The Bell System Tech- nical Journal27(3), 379–423 (Jul 1948).https://doi.org/10.1002/j.1538- 7305.1948.tb01338.x, part I of two parts
-
[29]
net/forum?id=St1giarCHLP
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conference on Learning Representations (ICLR) (2021),https://openreview. net/forum?id=St1giarCHLP
2021
-
[30]
Advances in neural information processing systems33, 12438–12448 (2020)
Song, Y., Ermon, S.: Improved techniques for training score-based generative mod- els. Advances in neural information processing systems33, 12438–12448 (2020)
2020
-
[31]
ArXivabs/2503.13217 (2025),https://api.semanticscholar.org/CorpusID:277103820
Su, Y., Zhan, X., Fang, H., Xue, H., Fang, H., Li, Y.L., Lu, C., Yang, L.: Dense policy: Bidirectional autoregressive learning of actions. ArXivabs/2503.13217 (2025),https://api.semanticscholar.org/CorpusID:277103820
-
[32]
ArXivabs/2503.06138(2025),https://api.semanticscholar.org/ CorpusID:276903370
Taniguchi, T., Hirai, Y., Suzuki, M., Murata, S., Horii, T., Tanaka, K.: System 0/1/2/3: Quad-process theory for multi-timescale embodied collective cognitive systems. ArXivabs/2503.06138(2025),https://api.semanticscholar.org/ CorpusID:276903370
-
[33]
Tian, Y., Yang, S., Zeng, J., Wang, P., Lin, D., Dong, H., Pang, J.: Predictive inverse dynamics models are scalable learners for robotic manipulation. arXiv preprint arXiv:2412.15109 (2024)
-
[34]
Advances in neural information processing systems34, 11287–11302 (2021)
Vahdat, A., Kreis, K., Kautz, J.: Score-based generative modeling in latent space. Advances in neural information processing systems34, 11287–11302 (2021)
2021
-
[35]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[36]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp
Wang, C., Fang, H., Fang, H., Lu, C.: Rise: 3d perception makes real-world robot imitation simple and effective. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) pp. 2870–2877 (2024),https://api. semanticscholar.org/CorpusID:269214333
2024
-
[37]
In: Proceedings of Robotics: Science and Systems (RSS) (2025)
Xue, H., Ren, J., Chen, W., Zhang, G., Fang, Y., Gu, G., Xu, H., Lu, C.: Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipula- tion. In: Proceedings of Robotics: Science and Systems (RSS) (2025)
2025
-
[38]
In: Proceedings of Robotics: Science and Systems (RSS) (2024)
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Gener- alizable visuomotor policy learning via simple 3d representations. In: Proceedings of Robotics: Science and Systems (RSS) (2024)
2024
-
[39]
ArXivabs/2506.09990(2025),https://api.semanticscholar.org/ CorpusID:279306263
Zhang, W., Hu, T., Qiao, Y., Zhang, H., Qin, Y., Li, Y., Liu, J., Kong, T., Liu, L., Ma, X.: Chain-of-action: Trajectory autoregressive modeling for robotic ma- nipulation. ArXivabs/2506.09990(2025),https://api.semanticscholar.org/ CorpusID:279306263
-
[40]
Zhao, T., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual manip- ulation with low-cost hardware. In: Proceedings of Robotics: Science and Systems (RSS) (2023) Appendix to HiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning Jiyao Zhang1,2, Zimu Han3, Junhan Wang1, Xionghao Wu4, Shihong Lin5, Jinzhou Li1, Hongwei Fan1,...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.