Recognition: 2 theorem links
· Lean TheoremHaloProbe: Bayesian Detection and Mitigation of Object Hallucinations in Vision-Language Models
Pith reviewed 2026-05-10 18:52 UTC · model grok-4.3
The pith
Vision-language models hallucinate fewer objects when their decoding is guided by HaloProbe's Bayesian estimates of token probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
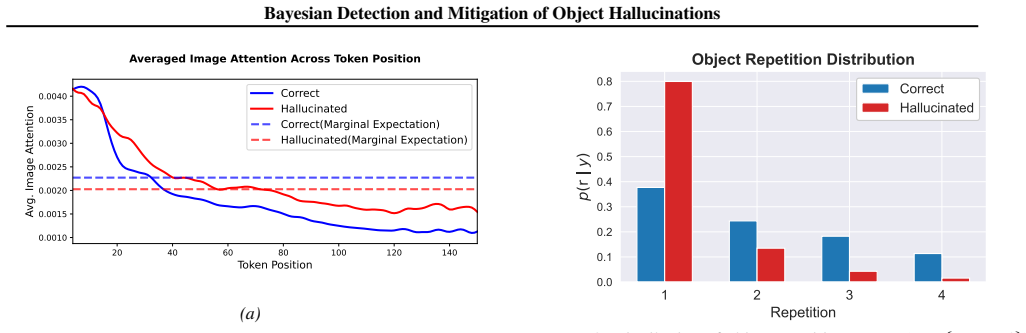
We reveal that coarse-grained attention-based analysis is unreliable due to hidden confounders, specifically token position and object repetition in a description. This leads to Simpson's paradox: the attention trends reverse or disappear when statistics are aggregated. Based on this observation, we introduce HaloProbe, a Bayesian framework that factorizes external description statistics and internal decoding signals to estimate token-level hallucination probabilities. HaloProbe uses balanced training to isolate internal evidence and combines it with a learned prior over external features to recover the true posterior. While intervention-based mitigation methods often degrade utility or flu
What carries the argument
HaloProbe, a Bayesian framework that factorizes external description statistics and internal decoding signals to estimate token-level hallucination probabilities using balanced training to isolate internal evidence and a learned prior over external features.
If this is right
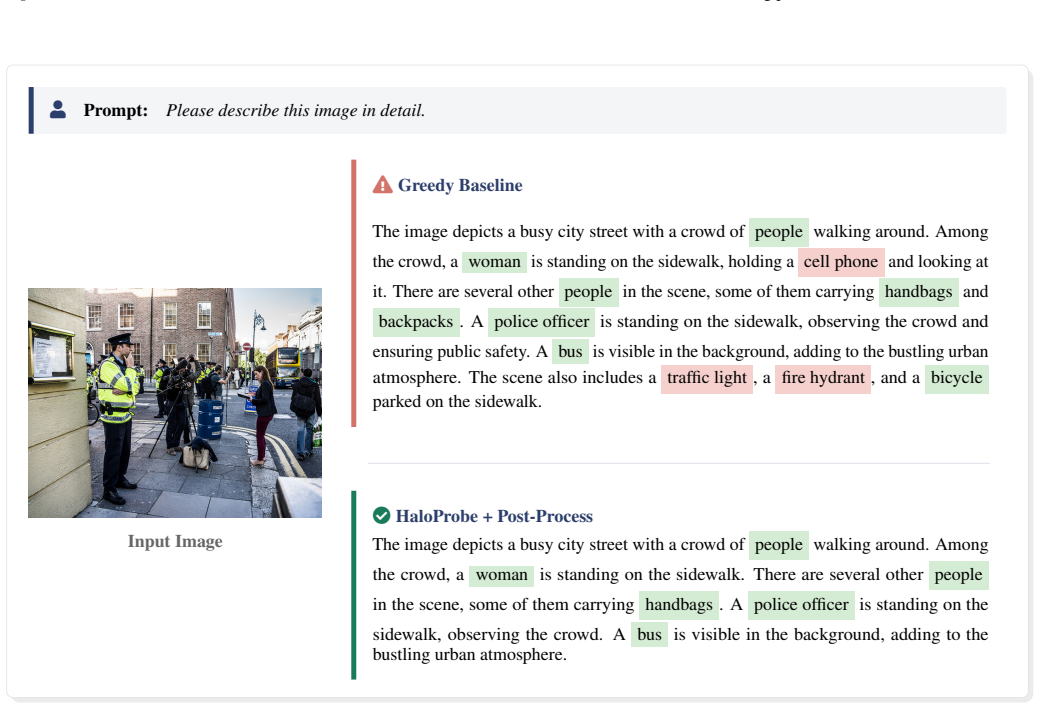
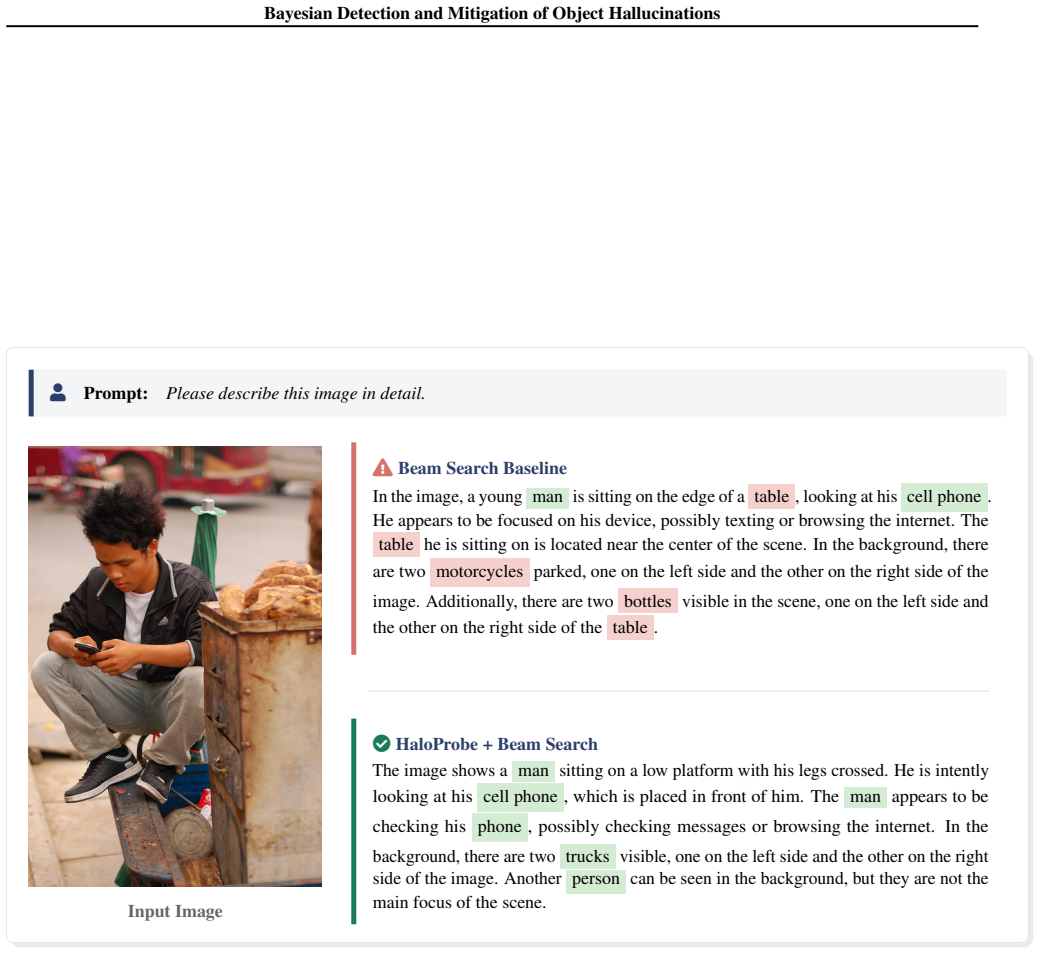
- HaloProbe-guided decoding reduces object hallucinations more effectively than existing intervention methods.
- Utility and fluency are preserved because mitigation happens externally without altering the model.
- Token-level hallucination probabilities allow precise, non-invasive intervention during text generation.
- The Bayesian factorization avoids the pitfalls of aggregated attention statistics.
Where Pith is reading between the lines
- HaloProbe could be adapted to mitigate other hallucination types like incorrect attributes or relations in descriptions.
- The approach might improve reliability in downstream applications such as visual question answering or image-based storytelling.
- Similar confounder issues could be investigated in attention mechanisms of other multimodal AI systems.
- Testable extension: apply HaloProbe to newer vision-language models to verify if the performance gains hold.
Load-bearing premise
Coarse-grained attention-based analysis is unreliable due to hidden confounders like token position and object repetition that produce Simpson's paradox when statistics are aggregated.
What would settle it
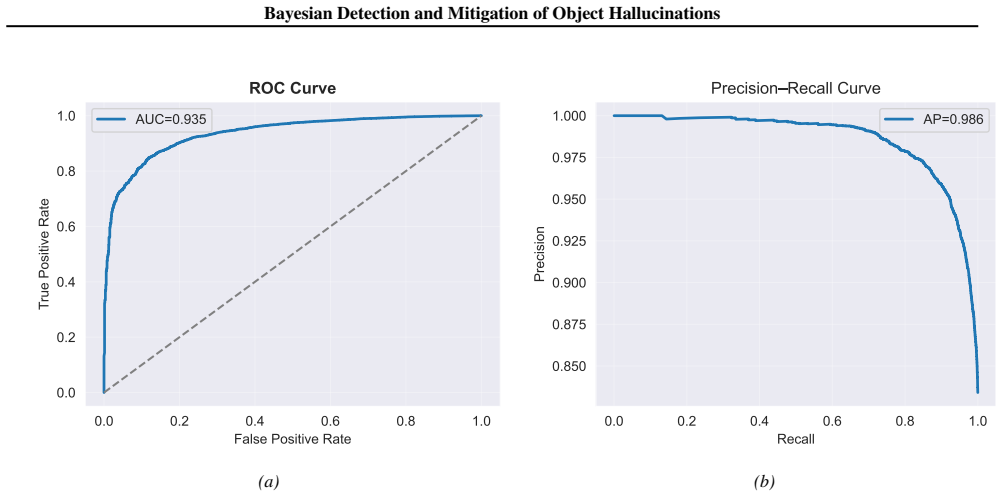
An experiment that measures hallucination rates using HaloProbe-guided decoding versus standard decoding on a held-out set of images with known ground-truth objects, checking if hallucination frequency drops significantly without utility loss.
Figures












read the original abstract
Large vision-language models can produce object hallucinations in image descriptions, highlighting the need for effective detection and mitigation strategies. Prior work commonly relies on the model's attention weights on visual tokens as a detection signal. We reveal that coarse-grained attention-based analysis is unreliable due to hidden confounders, specifically token position and object repetition in a description. This leads to Simpson's paradox: the attention trends reverse or disappear when statistics are aggregated. Based on this observation, we introduce HaloProbe, a Bayesian framework that factorizes external description statistics and internal decoding signals to estimate token-level hallucination probabilities. HaloProbe uses balanced training to isolate internal evidence and combines it with a learned prior over external features to recover the true posterior. While intervention-based mitigation methods often degrade utility or fluency by modifying models' internals, we use HaloProbe as an external scoring signal for non-invasive mitigation. Our experiments show that HaloProbe-guided decoding reduces hallucinations more effectively than state-of-the-art intervention-based methods while preserving utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that coarse-grained attention weights are unreliable for detecting object hallucinations in VLMs because token position and object repetition act as hidden confounders, producing Simpson's paradox when statistics are aggregated. It introduces HaloProbe, a Bayesian framework that factorizes external description statistics from internal decoding signals via balanced training plus a learned prior over external features, yielding token-level hallucination posteriors. These posteriors are then used as an external scoring signal for non-invasive guided decoding that reduces hallucinations more effectively than intervention-based methods while preserving utility.
Significance. If the central experimental claim holds, HaloProbe would provide a practical, non-invasive alternative to internal intervention methods that often trade off fluency or utility. The identification of Simpson's paradox in attention-based analysis is a useful methodological caution for the field. The Bayesian factorization approach is conceptually clean and could generalize if the balancing step is shown to be robust.
major comments (2)
- [Methods / Balanced Training] The section describing the balanced training procedure (and any associated ablations) does not specify how training examples are matched or stratified on token position and object repetition. Without these details or an ablation isolating the balancing step's contribution, it is unclear whether the claimed isolation of internal signals from confounders is achieved; this is load-bearing for the assertion that HaloProbe recovers a true posterior superior to attention baselines and for the experimental superiority claim.
- [Experiments] The experimental results section reports that HaloProbe-guided decoding outperforms SOTA intervention methods, but the provided abstract and summary contain no quantitative metrics, confidence intervals, or statistical tests. A load-bearing comparison requires explicit numbers (e.g., hallucination rate reduction and utility preservation scores) with controls for the same confounders identified in the attention analysis.
minor comments (2)
- [Methods] Notation for the learned prior and the factorization of external vs. internal factors should be introduced with an explicit equation early in the methods to improve readability.
- [Abstract] The abstract would be strengthened by including one or two key quantitative results (e.g., percentage reduction in hallucinations) rather than a purely qualitative claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below, providing clarifications on our methodology and committing to specific revisions that strengthen the presentation of both the balanced training procedure and the experimental results.
read point-by-point responses
-
Referee: [Methods / Balanced Training] The section describing the balanced training procedure (and any associated ablations) does not specify how training examples are matched or stratified on token position and object repetition. Without these details or an ablation isolating the balancing step's contribution, it is unclear whether the claimed isolation of internal signals from confounders is achieved; this is load-bearing for the assertion that HaloProbe recovers a true posterior superior to attention baselines and for the experimental superiority claim.
Authors: We agree that the manuscript's description of the balanced training procedure lacks sufficient detail on the matching and stratification process with respect to token position and object repetition. This information is necessary to fully validate the isolation of internal decoding signals from the confounders identified in our attention analysis. In the revised version, we will expand the Methods section with a precise account of the stratification criteria, the matching algorithm employed, and the resulting dataset composition. We will also add a dedicated ablation that directly compares HaloProbe performance with and without the balancing step, thereby isolating its contribution and supporting the claim that the Bayesian factorization yields a superior posterior. revision: yes
-
Referee: [Experiments] The experimental results section reports that HaloProbe-guided decoding outperforms SOTA intervention methods, but the provided abstract and summary contain no quantitative metrics, confidence intervals, or statistical tests. A load-bearing comparison requires explicit numbers (e.g., hallucination rate reduction and utility preservation scores) with controls for the same confounders identified in the attention analysis.
Authors: We acknowledge that the abstract and summary in the submitted version are concise and omit explicit quantitative metrics, confidence intervals, and statistical tests. Although the experimental results section of the full manuscript presents comparative outcomes, we agree that greater transparency is warranted given the load-bearing nature of the superiority claim. In the revision, we will update the abstract to include key quantitative results (hallucination rate reductions and utility preservation scores) together with confidence intervals. We will further augment the experiments section with statistical significance tests and explicitly report results stratified by token position and object repetition, thereby applying the same controls identified in the attention analysis. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper first empirically demonstrates that attention-based hallucination detection suffers from Simpson's paradox due to confounders (token position, object repetition). It then proposes HaloProbe as an external Bayesian scoring method that applies balanced training to separate internal decoding signals from external statistics, combines this with a learned prior, and uses the resulting token-level probabilities for non-invasive guided decoding. This chain does not reduce any claimed prediction or posterior to its inputs by construction: the balancing step is a data-preprocessing choice whose contribution is assessed via ablation-style experiments, the prior is fitted on held-out external features, and the superiority claim rests on direct comparison against intervention baselines on utility and hallucination metrics. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are load-bearing; the framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learned prior over external features
axioms (1)
- domain assumption Hallucination probability can be factorized into external description statistics and internal decoding signals
invented entities (1)
-
HaloProbe
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HaloProbe uses balanced training to isolate internal evidence and combines it with a learned prior over external features to recover the true posterior.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We reveal that coarse-grained attention-based analysis is unreliable due to hidden confounders... This leads to Simpson’s paradox
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L
URLhttps://arxiv.org/abs/2405.05256. Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L. Mitigating object hallucinations in large vision-language mod- els through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pp. 13872–13882, 2024. 11 Bayesian Detection and Mitigation...
-
[2]
Evaluating Object Hallucination in Large Vision-Language Models
URLhttps://arxiv.org/abs/2305.10355. Lin, T.-Y ., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ar, P., and Zitnick, C. L. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pp. 740–755. Springer, 2014. Liu, H., Li, C., Li, Y ., and Lee, Y . J. Improved baselines with visual instruction tuning. InProcee...
work page internal anchor Pith review arXiv 2014
-
[3]
doi: 10.18653/v1/2025.emnlp-main.273. URL https:// aclanthology.org/2025.emnlp-main.273/. Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 13 Bayesian Detection and Mitigation of Object Hallucinations A. Detailed Experimental...
-
[4]
The image shows a spacious studio apartment kitchen with wooden cabinets and $refrigerator
**Remove Only Hallucinated Objects:** - The objects marked with`$`are hallucinated, and you need to **remove only those hallucinated objects** from the caption. For example: - "The image shows a spacious studio apartment kitchen with wooden cabinets and $refrigerator."→"The image shows a spacious studio apartment kitchen with wooden cabinets." - Do **not*...
-
[5]
For example: - **Do not delete** entire sentence structures unless absolutely necessary to maintain clarity
**Minimal Changes:** - If removing a hallucinated object causes awkward phrasing, make minimal edits to improve the fluency of the sentence. For example: - **Do not delete** entire sentence structures unless absolutely necessary to maintain clarity
-
[6]
Do not introduce new details, objects, or replace hallucinated objects with new ones (e.g., don't replace`$refrigerator`with another new object `microwave`)
**Faithfulness to the Original Caption:** - Ensure that the edited caption remains **faithful** to the original context. Do not introduce new details, objects, or replace hallucinated objects with new ones (e.g., don't replace`$refrigerator`with another new object `microwave`). - The resulting text should **not lose any original meaning** or introduce new...
-
[7]
Do not over-edit the original content
**Clarity and Brevity:** - The edited caption should be clear and concise without being overly terse. Do not over-edit the original content. Make sure that the edited text does not contain objects that are marked with $ in the input text
-
[8]
"`), without any additional text or explanations. The input caption is:
**Output Format:** - Provide only the final, edited caption inside **double quotes** (`""`), without any additional text or explanations. The input caption is: """ E. Effect of Attention Intervention on Decoding Stability While attention intervention has been proposed as a mechanism to improve grounding and reduce hallucination, directly manipu- lating at...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.