Recognition: 2 theorem links
· Lean TheoremTalkLoRA: Communication-Aware Mixture of Low-Rank Adaptation for Large Language Models
Pith reviewed 2026-05-10 20:13 UTC · model grok-4.3
The pith
TalkLoRA adds expert communication before routing to stabilize MoELoRA and improve LLM fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
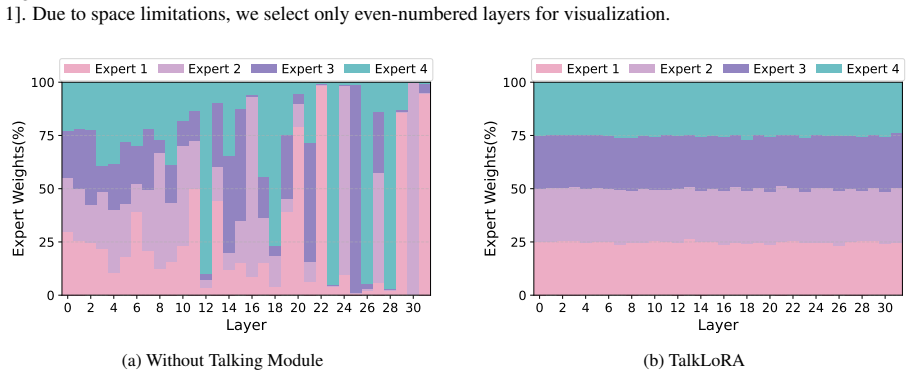
TalkLoRA equips low-rank experts with a lightweight Talking Module that enables controlled information exchange across expert subspaces prior to routing, thereby producing a more robust global signal. Theoretically, this communication smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures. Empirically, the method delivers higher performance than both vanilla LoRA and prior MoELoRA variants across language understanding and generation tasks, together with improved parameter efficiency and more balanced expert utilization under comparable budgets.
What carries the argument
The Talking Module, a lightweight component attached to each low-rank expert that performs controlled inter-expert communication to produce a global signal used for routing.
If this is right
- Expert communication mitigates perturbation amplification during routing.
- TalkLoRA strictly generalizes all existing MoELoRA architectures.
- Routing becomes more balanced and expert dominance is reduced.
- Performance gains appear on both understanding and generation tasks without extra parameters.
Where Pith is reading between the lines
- The same communication-before-routing pattern could be tested in mixture-of-experts versions of other adapters such as prefix tuning.
- Global signals generated by expert exchange may help prevent collapse when scaling to larger numbers of experts.
- Alternative designs for the Talking Module, such as learned message passing, could be compared while keeping the overhead constraint fixed.
Load-bearing premise
A lightweight Talking Module can be added with negligible overhead and the resulting global signal improves routing without introducing new instabilities or overfitting risks.
What would settle it
Direct head-to-head experiments on the same tasks and budgets where TalkLoRA shows no gain in accuracy or routing balance relative to standard MoELoRA would falsify the claimed benefit of expert communication.
Figures




read the original abstract
Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of Large Language Models (LLMs), and recent Mixture-of-Experts (MoE) extensions further enhance flexibility by dynamically combining multiple LoRA experts. However, existing MoE-augmented LoRA methods assume that experts operate independently, often leading to unstable routing, expert dominance. In this paper, we propose \textbf{TalkLoRA}, a communication-aware MoELoRA framework that relaxes this independence assumption by introducing expert-level communication prior to routing. TalkLoRA equips low-rank experts with a lightweight Talking Module that enables controlled information exchange across expert subspaces, producing a more robust global signal for routing. Theoretically, we show that expert communication smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures. Empirically, TalkLoRA consistently outperforms vanilla LoRA and MoELoRA across diverse language understanding and generation tasks, achieving higher parameter efficiency and more balanced expert routing under comparable parameter budgets. These results highlight structured expert communication as a principled and effective enhancement for MoE-based parameter-efficient adaptation. Code is available at https://github.com/why0129/TalkLoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TalkLoRA, a communication-aware MoELoRA framework for parameter-efficient fine-tuning of LLMs. It equips low-rank experts with a lightweight Talking Module for controlled information exchange prior to routing, theoretically showing that this smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures. Empirically, it reports consistent outperformance over vanilla LoRA and MoELoRA on language understanding and generation tasks, with improved parameter efficiency and more balanced expert routing under comparable budgets. Public code is released.
Significance. If the generalization and smoothing claims hold with the stated construction, TalkLoRA provides a principled extension to MoE-based PEFT by relaxing expert independence, which could improve routing stability in large-model adaptation. The public code release at https://github.com/why0129/TalkLoRA strengthens reproducibility and allows direct verification of the perturbation analysis and empirical protocols.
major comments (3)
- [Theoretical Analysis] Theoretical section (derivation of generalization and perturbation smoothing): the claim that expert communication 'strictly generalizes existing MoELoRA architectures' and 'mitigates perturbation amplification' requires an explicit step showing that the Talking Module term can be exactly zeroed (e.g., by setting communication dimension or module weights to zero) to recover the independent-expert routing function without residual changes; this is load-bearing for the central theoretical result.
- [Experiments] Experimental results and setup: the reported gains in performance, parameter efficiency, and routing balance need full details on data splits, exact baseline reproductions (including MoELoRA variants), number of random seeds, statistical significance tests, and precise accounting of added parameters from the Talking Module (communication dimension size) to confirm the claims are not affected by post-hoc fitting or unequal budgets.
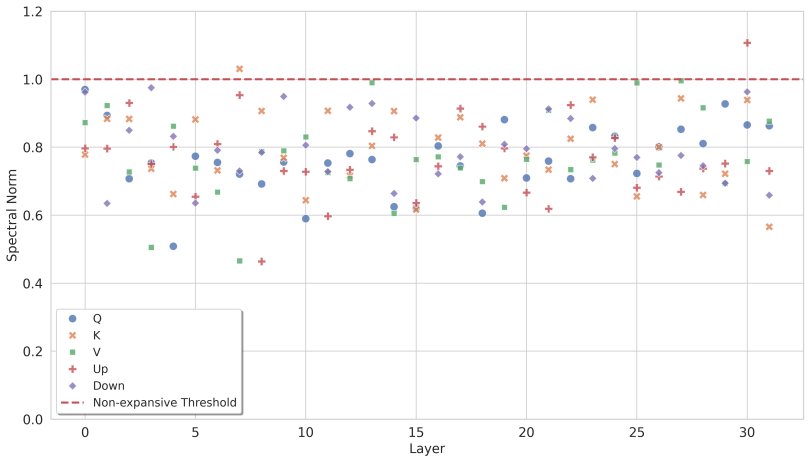
- [Method / Talking Module] Talking Module design: the assumption that the module adds negligible overhead and the resulting global signal is always beneficial requires an ablation or stability analysis showing no new instabilities or overfitting risks across the tested communication dimensions and expert counts; this directly addresses the weakest assumption in the framework.
minor comments (2)
- [Abstract] Abstract: while concise, it could briefly name the specific tasks or benchmarks (e.g., GLUE subsets or generation datasets) to contextualize the empirical claims immediately.
- [Preliminaries / Notation] Notation: ensure the routing function, perturbation term, and communication signal are defined with consistent symbols across the theoretical derivation and pseudocode to prevent ambiguity in the smoothing argument.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions. Below, we provide point-by-point responses to the major comments and describe the changes we intend to implement in the revised manuscript.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical section (derivation of generalization and perturbation smoothing): the claim that expert communication 'strictly generalizes existing MoELoRA architectures' and 'mitigates perturbation amplification' requires an explicit step showing that the Talking Module term can be exactly zeroed (e.g., by setting communication dimension or module weights to zero) to recover the independent-expert routing function without residual changes; this is load-bearing for the central theoretical result.
Authors: We agree that an explicit demonstration is required to substantiate the strict generalization claim. In the revised manuscript, we will add a dedicated paragraph in the theoretical analysis section that explicitly shows how setting the communication dimension (or equivalently the Talking Module weights) to zero recovers the independent-expert MoELoRA routing function with no residual terms or modifications. This step will be placed immediately after the definition of the Talking Module to make the construction transparent. revision: yes
-
Referee: [Experiments] Experimental results and setup: the reported gains in performance, parameter efficiency, and routing balance need full details on data splits, exact baseline reproductions (including MoELoRA variants), number of random seeds, statistical significance tests, and precise accounting of added parameters from the Talking Module (communication dimension size) to confirm the claims are not affected by post-hoc fitting or unequal budgets.
Authors: We acknowledge the need for greater experimental transparency. The revised version will expand the experimental section with: complete descriptions of all data splits, exact reproduction protocols and hyperparameter settings for every baseline (including all MoELoRA variants), the number of random seeds used (three seeds), results of statistical significance tests (paired t-tests with p-values), and a precise parameter-count breakdown that isolates the contribution of the Talking Module for each communication dimension. These additions will confirm that all comparisons respect equivalent parameter budgets. revision: yes
-
Referee: [Method / Talking Module] Talking Module design: the assumption that the module adds negligible overhead and the resulting global signal is always beneficial requires an ablation or stability analysis showing no new instabilities or overfitting risks across the tested communication dimensions and expert counts; this directly addresses the weakest assumption in the framework.
Authors: We thank the referee for identifying this key assumption. In the revision we will incorporate additional ablation studies that vary communication dimension and expert count. These studies will report training/validation curves, routing balance metrics, and any observed instabilities or overfitting indicators to demonstrate that the Talking Module introduces no new risks and that the global signal remains beneficial across the tested configurations. revision: yes
Circularity Check
No significant circularity; derivation self-contained via explicit generalization
full rationale
The paper's theoretical claim states that expert communication smooths routing by mitigating perturbation amplification while strictly generalizing MoELoRA architectures. This is not circular because the generalization property is defined to recover the independent-expert case exactly when the communication term is zeroed, providing an independent mathematical reduction rather than a self-definition or fitted prediction. No equations or sections in the provided text reduce a 'prediction' to a fitted parameter by construction, nor do they rely on load-bearing self-citations for uniqueness or ansatz smuggling. Empirical performance claims are presented separately from the theory and do not collapse to the inputs. The derivation chain remains externally grounded against standard MoELoRA baselines.
Axiom & Free-Parameter Ledger
free parameters (2)
- Talking Module size / communication dimension
- Number of experts and LoRA rank
axioms (1)
- domain assumption Low-rank updates remain valid when a small shared signal is added across expert subspaces.
invented entities (1)
-
Talking Module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theoretically, we show that expert communication smooths routing dynamics by mitigating perturbation amplification while strictly generalizing existing MoELoRA architectures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. 2022. https://doi.org/10.18653/v1/2022.acl-short.1 B it F it: Simple parameter-efficient fine-tuning for transformer-based masked language-models . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1--9, Dublin, Ireland. Association...
-
[2]
Massimo Bini, Leander Girrbach, and Zeynep Akata. 2025. https://openreview.net/forum?id=X1U74IwuxG Decoupling angles and strength in low-rank adaptation . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[3]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. https://doi.org/10.1609/AAAI.V34I05.6239 PIQA: reasoning about physical commonsense in natural language . In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The...
-
[4]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. 2025. https://doi.org/10.1109/TKDE.2025.3554028 A survey on mixture of experts in large language models . IEEE Transactions on Knowledge and Data Engineering, 37(7):3896--3915
-
[5]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1300 B ool Q : Exploring the surprising difficulty of natural yes/no questions . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language...
-
[6]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. https://arxiv.org/abs/1803.05457 Think you have solved question answering? try arc, the AI2 reasoning challenge . CoRR, abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Wei Shen, Limao Xiong, Yuhao Zhou, Xiao Wang, Zhiheng Xi, Xiaoran Fan, Shiliang Pu, Jiang Zhu, Rui Zheng, Tao Gui, Qi Zhang, and Xuanjing Huang. 2024. https://doi.org/10.18653/v1/2024.acl-long.106 L o RAM o E : Alleviating world knowledge forgetting in large language models via M o E -style plugin . In Proceed...
-
[8]
Wenfeng Feng, Chuzhan Hao, Yuewei Zhang, Yu Han, and Hao Wang. 2024. https://aclanthology.org/2024.lrec-main.994 Mixture-of-loras: An efficient multitask tuning method for large language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Tor...
2024
-
[9]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. https://doi.org/10.1109/ICCV.2015.123 Delving deep into rectifiers: Surpassing human-level performance on imagenet classification . In 2015 IEEE International Conference on Computer Vision (ICCV), pages 1026--1034
-
[10]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. http://proceedings.mlr.press/v97/houlsby19a.html Parameter-efficient transfer learning for NLP . In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach...
2019
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lora: Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
-
[12]
Qiushi Huang, Tom Ko, Zhan Zhuang, Lilian Tang, and Yu Zhang. 2025. https://openreview.net/forum?id=TwJrTz9cRS Hira: Parameter-efficient hadamard high-rank adaptation for large language models . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[13]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. 1991. https://doi.org/10.1162/neco.1991.3.1.79 Adaptive mixtures of local experts . Neural Computation, 3(1):79--87
- [14]
-
[15]
Tianwei Lin, Jiang Liu, Wenqiao Zhang, Yang Dai, Haoyuan Li, Zhelun Yu, Wanggui He, Juncheng Li, Jiannan Guo, Hao Jiang, Siliang Tang, and Yueting Zhuang. 2025. https://doi.org/10.18653/v1/2025.acl-long.669 T eam L o RA : Boosting low-rank adaptation with expert collaboration and competition . In Proceedings of the 63rd Annual Meeting of the Association f...
-
[16]
Boan Liu, Liang Ding, Li Shen, Keqin Peng, Yu Cao, Dazhao Cheng, and Dacheng Tao. 2024 a . https://doi.org/10.3233/FAIA240836 Diversifying the mixture-of-experts representation for language models with orthogonal optimizer . In ECAI 2024 - 27th European Conference on Artificial Intelligence, 19-24 October 2024, Santiago de Compostela, Spain - Including 13...
-
[17]
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/0cde695b83bd186c1fd456302888454c-Abstract-Conference.html Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning . In Advances in Neural Information Processing Systems ...
2022
-
[18]
Shih - Yang Liu, Chien - Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu - Chiang Frank Wang, Kwang - Ting Cheng, and Min - Hung Chen. 2024 b . https://openreview.net/forum?id=3d5CIRG1n2 Dora: Weight-decomposed low-rank adaptation . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net
2024
-
[19]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. https://arxiv.org/abs/1907.11692 Roberta: A robustly optimized BERT pretraining approach . CoRR, abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Ilya Loshchilov and Frank Hutter. 2019. https://openreview.net/forum?id=Bkg6RiCqY7 Decoupled weight decay regularization . In International Conference on Learning Representations
2019
-
[21]
Tongxu Luo, Jiahe Lei, Fangyu Lei, Weihao Liu, Shizhu He, Jun Zhao, and Kang Liu. 2024. https://doi.org/10.48550/ARXIV.2402.12851 Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models . CoRR, abs/2402.12851
-
[22]
Yufei Ma, Zihan Liang, Huangyu Dai, Ben Chen, Dehong Gao, Zhuoran Ran, Wang Zihan, Linbo Jin, Wen Jiang, Guannan Zhang, Xiaoyan Cai, and Libin Yang. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.161 M o DULA : Mixture of domain-specific and universal L o RA for multi-task learning . In Proceedings of the 2024 Conference on Empirical Methods in Natural...
-
[23]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. https://doi.org/10.18653/v1/D18-1260 Can a suit of armor conduct electricity? a new dataset for open book question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381--2391, Brussels, Belgium. Association for Computational Li...
-
[24]
Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Martial Hebert. 2016. https://doi.org/10.1109/CVPR.2016.433 Cross-stitch networks for multi-task learning . In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3994--4003
-
[25]
Lin Mu, Xiaoyu Wang, Li Ni, Yang Li, Zhize Wu, Peiquan Jin, and Yiwen Zhang. 2025. https://doi.org/10.18653/v1/2025.acl-long.503 D ense L o RA : Dense low-rank adaptation of large language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10198--10211, Vienna, Austria. Associ...
-
[26]
Lin Mu, Wenhao Zhang, Yiwen Zhang, and Peiquan Jin. 2024. https://doi.org/10.18653/V1/2024.ACL-SHORT.17 Ddprompt: Differential diversity prompting in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, ACL 2024 - Short Papers, Bangkok, Thailand, August 11-16, 2024 , pages 168--174. Associatio...
-
[27]
OpenAI. 2023. https://doi.org/10.48550/ARXIV.2303.08774 GPT-4 technical report . CoRR, abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[28]
Chengwei Qin, Aston Zhang, Zhuosheng Zhang, Jiaao Chen, Michihiro Yasunaga, and Diyi Yang. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.85 Is C hat GPT a general-purpose natural language processing task solver? In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1339--1384, Singapore. Association for Compu...
-
[29]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. https://doi.org/10.1145/3474381 Winogrande: an adversarial winograd schema challenge at scale . Commun. ACM, 64(9):99–106
-
[30]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. 2019. https://doi.org/10.18653/v1/D19-1454 Social IQ a: Commonsense reasoning about social interactions . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP),...
- [31]
-
[32]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. https://openreview.net/forum?id=B1ckMDqlg Outrageously large neural networks: The sparsely-gated mixture-of-experts layer . In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conferenc...
2017
-
[33]
Llama Team. 2024. https://doi.org/10.48550/ARXIV.2407.21783 The llama 3 herd of models . CoRR, abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[34]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton - Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[35]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. https://openreview.net/forum?id=rJ4km2R5t7 GLUE: A multi-task benchmark and analysis platform for natural language understanding . In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net
2019
-
[36]
Muling Wu, Wenhao Liu, Xiaohua Wang, Tianlong Li, Changze Lv, Zixuan Ling, Zhu JianHao, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. 2024 a . https://doi.org/10.18653/v1/2024.acl-long.726 Advancing parameter efficiency in fine-tuning via representation editing . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguisti...
-
[37]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. 2024 b . http://papers.nips.cc/paper\_files/paper/2024/hash/75008a0fba53bf13b0bb3b7bff986e0e-Abstract-Conference.html Reft: Representation finetuning for language models . In Advances in Neural Information Processing Systems 38: Annual Con...
2024
-
[38]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[39]
Yaming Yang, Dilxat Muhtar, Yelong Shen, Yuefeng Zhan, Jianfeng Liu, Yujing Wang, Hao Sun, Weiwei Deng, Feng Sun, Qi Zhang, Weizhu Chen, and Yunhai Tong. 2025. https://doi.org/10.1609/AAAI.V39I20.35509 Mtl-lora: Low-rank adaptation for multi-task learning . In Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative...
-
[40]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. https://doi.org/10.18653/v1/P19-1472 H ella S wag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791--4800, Florence, Italy. Association for Computational Linguistics
-
[41]
Dacao Zhang, Kun Zhang, Shimao Chu, Le Wu, Xin Li, and Si Wei. 2025. https://doi.org/10.18653/v1/2025.findings-acl.68 M o RE : A mixture of low-rank experts for adaptive multi-task learning . In Findings of the Association for Computational Linguistics: ACL 2025, pages 1311--1324, Vienna, Austria. Association for Computational Linguistics
-
[42]
Lulu Zhao, Weihao Zeng, Shi Xiaofeng, and Hua Zhou. 2025. https://aclanthology.org/2025.coling-main.111/ M o SLD : An extremely parameter-efficient mixture-of-shared L o RA s for multi-task learning . In Proceedings of the 31st International Conference on Computational Linguistics, pages 1647--1659, Abu Dhabi, UAE. Association for Computational Linguistics
2025
-
[43]
Simiao Zuo, Xiaodong Liu, Jian Jiao, Young Jin Kim, Hany Hassan, Ruofei Zhang, Jianfeng Gao, and Tuo Zhao. 2022. https://openreview.net/forum?id=B72HXs80q4 Taming sparsely activated transformer with stochastic experts . In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net
2022
-
[44]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[45]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.