Recognition: 2 theorem links
· Lean TheoremBiScale-GTR: Fragment-Aware Graph Transformers for Multi-Scale Molecular Representation Learning
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
BiScale-GTR fuses improved molecular fragment tokens with pooled GNN atom features inside a Transformer to enable multi-scale reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that chemically grounded fragment tokenization via improved graph BPE, followed by pooling GNN atom features into fragment embeddings and fusing them with fragment token embeddings, lets the Transformer jointly model local chemical environments, substructure-level motifs, and long-range dependencies, yielding state-of-the-art results on MoleculeNet, PharmaBench, and the Long Range Graph Benchmark across classification and regression tasks while producing attributions that align with known functional motifs.
What carries the argument
The fusion of GNN-pooled fragment embeddings with learned fragment token embeddings before Transformer reasoning in the parallel GNN-Transformer architecture.
Load-bearing premise
That the improved graph BPE tokenization reliably produces consistent, chemically valid, high-coverage fragments whose fusion with GNN atom features creates multi-scale reasoning that single-granularity models cannot achieve.
What would settle it
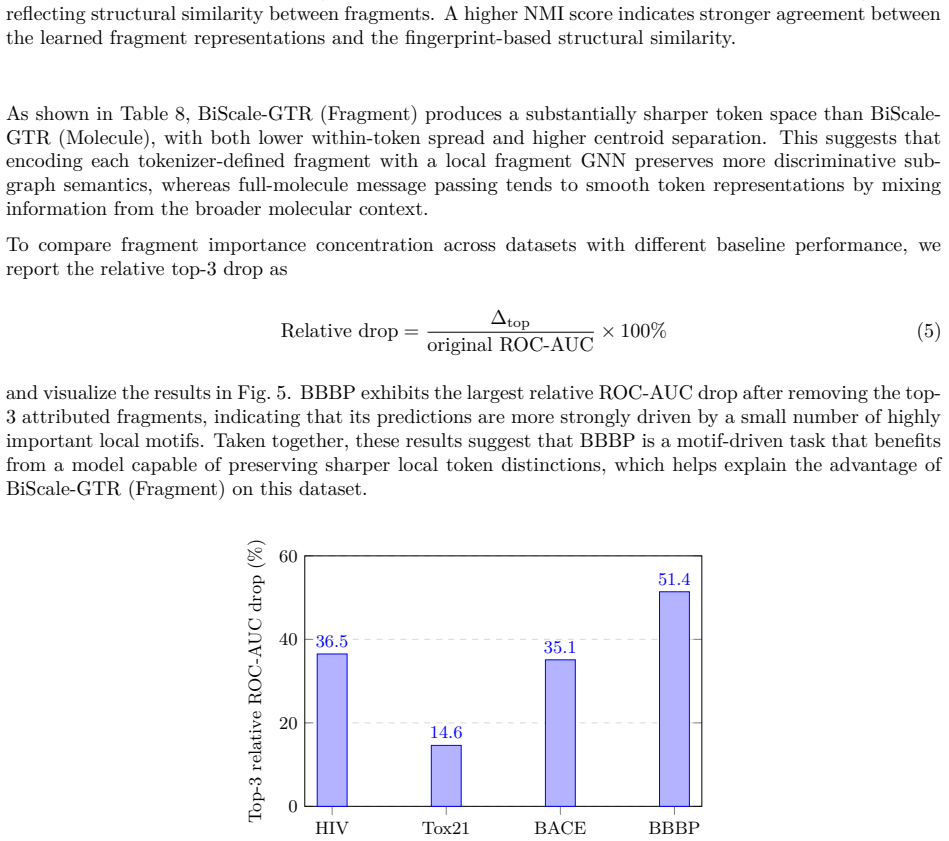
An ablation that removes the fragment fusion step or reverts to standard graph BPE tokenization and measures whether performance on MoleculeNet, PharmaBench, and LRGB falls below the reported levels, or whether the attribution maps no longer highlight chemically recognized functional groups.
Figures





read the original abstract
Graph Transformers have recently attracted attention for molecular property prediction by combining the inductive biases of graph neural networks (GNNs) with the global receptive field of Transformers. However, many existing hybrid architectures remain GNN-dominated, causing the resulting representations to remain heavily shaped by local message passing. Moreover, most existing methods operate at only a single structural granularity, limiting their ability to capture molecular patterns that span multiple molecular scales. We introduce BiScale-GTR, a unified framework for self-supervised molecular representation learning that combines chemically grounded fragment tokenization with adaptive multi-scale reasoning. Our method improves graph Byte Pair Encoding (BPE) tokenization to produce consistent, chemically valid, and high-coverage fragment tokens, which are used as fragment-level inputs to a parallel GNN-Transformer architecture. Architecturally, atom-level representations learned by a GNN are pooled into fragment-level embeddings and fused with fragment token embeddings before Transformer reasoning, enabling the model to jointly capture local chemical environments, substructure-level motifs, and long-range molecular dependencies. Experiments on MoleculeNet, PharmaBench, and the Long Range Graph Benchmark (LRGB) demonstrate state-of-the-art performance across both classification and regression tasks. Attribution analysis further shows that BiScale-GTR highlights chemically meaningful functional motifs, providing interpretable links between molecular structure and predicted properties. Code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BiScale-GTR, a self-supervised framework for molecular representation learning. It improves graph BPE tokenization to produce consistent, chemically valid, high-coverage fragment tokens, pools atom-level GNN representations into fragment embeddings, fuses them with fragment token embeddings, and feeds the result into a Transformer for joint local, substructure, and long-range reasoning. The paper claims state-of-the-art performance on MoleculeNet, PharmaBench, and LRGB across classification and regression tasks, plus attribution maps that highlight chemically meaningful functional motifs.
Significance. If the performance claims and attribution results hold under rigorous controls, the work would advance hybrid GNN-Transformer models by explicitly enabling multi-scale reasoning that single-granularity baselines cannot achieve. The chemically grounded fragment tokenization and interpretability analysis are positive contributions to molecular ML.
major comments (1)
- [Abstract] Abstract: The central claim of state-of-the-art performance and the superiority of the multi-scale fusion is unsupported by any quantitative tables, error bars, ablation studies, or experimental protocol details. Without these, it is impossible to verify whether the reported gains are attributable to the fragment-aware architecture or to other uncontrolled factors, directly undermining evaluation of the weakest assumption that improved BPE fragments plus fusion enable genuinely multi-scale reasoning.
minor comments (2)
- The fusion operator between pooled GNN atom features and fragment token embeddings is described only at a high level; a precise equation or pseudocode would clarify how the multi-scale integration is implemented.
- No implementation specifics (e.g., BPE vocabulary size, pooling method, or baseline reproduction details) are supplied, which are required for reproducibility in this domain.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the need for stronger support of the performance claims. We address the single major comment below and will incorporate revisions to improve verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of state-of-the-art performance and the superiority of the multi-scale fusion is unsupported by any quantitative tables, error bars, ablation studies, or experimental protocol details. Without these, it is impossible to verify whether the reported gains are attributable to the fragment-aware architecture or to other uncontrolled factors, directly undermining evaluation of the weakest assumption that improved BPE fragments plus fusion enable genuinely multi-scale reasoning.
Authors: We agree that the abstract, as a concise summary, does not itself contain quantitative tables, error bars, or protocol details, which can make the SOTA claims appear unsupported when read in isolation. The full manuscript addresses this through: (1) comprehensive result tables on MoleculeNet, PharmaBench, and LRGB with mean performance and standard deviations over multiple seeds; (2) ablation studies that isolate the contributions of improved graph BPE tokenization, atom-to-fragment pooling, and the parallel GNN-Transformer fusion versus single-scale baselines; and (3) full experimental protocols, hyperparameters, and training details in the main Experiments section and appendix. These controls demonstrate that the gains arise from the multi-scale architecture rather than uncontrolled factors. To strengthen the abstract, we will revise it to briefly reference the supporting experimental evidence (e.g., “with detailed ablations and comparisons in Section 4”) while preserving brevity. This revision will make the claims more directly verifiable from the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description frame BiScale-GTR as an empirical architecture that improves graph BPE tokenization, pools GNN atom features into fragment embeddings, fuses them with fragment tokens, and feeds the result to a Transformer for multi-scale reasoning. All performance claims are tied to external benchmarks (MoleculeNet, PharmaBench, LRGB) rather than any internal derivation, prediction, or first-principles result. No equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the supplied text. The method is therefore self-contained against external evaluation and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Improved graph BPE produces consistent, chemically valid, high-coverage fragment tokens
- domain assumption Pooling atom-level GNN features into fragment embeddings preserves chemically relevant information
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce BiScale-GTR, a unified framework ... improves graph Byte Pair Encoding (BPE) tokenization to produce consistent, chemically valid, and high-coverage fragment tokens ... atom-level representations learned by a GNN are pooled into fragment-level embeddings and fused with fragment token embeddings before Transformer reasoning
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on MoleculeNet, PharmaBench, and the Long Range Graph Benchmark (LRGB) demonstrate state-of-the-art performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xavier Bresson and Thomas Laurent. Residual gated graph convnets.arXiv preprint arXiv:1711.07553,
-
[2]
Bert: Pre-trainingofdeepbidirectional transformers for language understanding
JacobDevlin, Ming-WeiChang, KentonLee, andKristinaToutanova. Bert: Pre-trainingofdeepbidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[3]
Shikun Feng, Yuyan Ni, Minghao Li, Yanwen Huang, Zhi-Ming Ma, Wei-Ying Ma, and Yanyan Lan. Unicorn: A unified contrastive learning approach for multi-view molecular representation learning.arXiv preprint arXiv:2405.10343,
-
[4]
Johannes Gasteiger, Janek Groß, and Stephan Günnemann. Directional message passing for molecular graphs.arXiv preprint arXiv:2003.03123,
-
[5]
Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265,
-
[6]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Pengyong Li, Jun Wang, Yixuan Qiao, Hao Chen, Yihuan Yu, Xiaojun Yao, Peng Gao, Guotong Xie, and Sen Song. Learn molecular representations from large-scale unlabeled molecules for drug discovery.arXiv preprint arXiv:2012.11175,
-
[8]
Pre-training molecular graph representation with 3d geometry.arXiv preprint arXiv:2110.07728,
Shengchao Liu, Hanchen Wang, Weiyang Liu, Joan Lasenby, Hongyu Guo, and Jian Tang. Pre-training molecular graph representation with 3d geometry.arXiv preprint arXiv:2110.07728,
-
[9]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
One trans- former can understand both 2d & 3d molecular data.arXiv preprint arXiv:2210.01765,
Shengjie Luo, Tianlang Chen, Yixian Xu, Shuxin Zheng, Tie-Yan Liu, Liwei Wang, and Di He. One trans- former can understand both 2d & 3d molecular data.arXiv preprint arXiv:2210.01765,
-
[11]
Erxue Min, Runfa Chen, Yatao Bian, Tingyang Xu, Kangfei Zhao, Wenbing Huang, Peilin Zhao, Junzhou Huang, Sophia Ananiadou, and Yu Rong. Transformer for graphs: An overview from architecture per- spective.arXiv preprint arXiv:2202.08455,
-
[12]
Ankur Samanta, Rohan Gupta, Aditi Misra, Christian McIntosh Clarke, and Jayakumar Rajadas. Frag- mentnet: Adaptive graph fragmentation for graph-to-sequence molecular representation learning.arXiv preprint arXiv:2502.01184,
-
[13]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.