Recognition: no theorem link
SELFDOUBT: Uncertainty Quantification for Reasoning LLMs via the Hedge-to-Verify Ratio
Pith reviewed 2026-05-10 18:45 UTC · model grok-4.3
The pith
Traces without any hedging markers are correct 96 percent of the time in reasoning language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
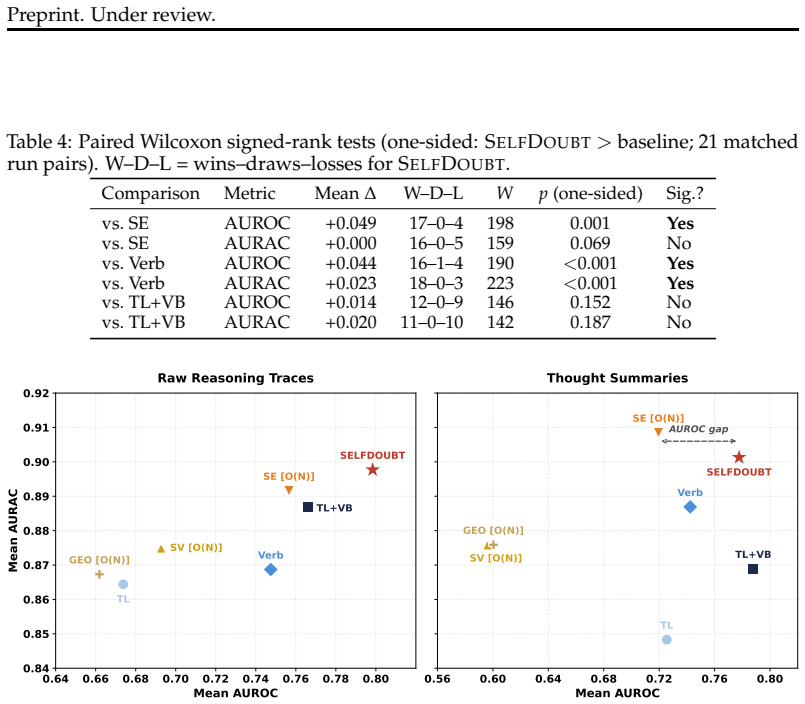
The Hedge-to-Verify Ratio extracted from a single reasoning trace detects uncertainty by counting hedging markers and checking whether they are balanced by self-verification behavior; traces containing zero hedging markers are correct 96 percent of the time, and the full ratio score significantly outperforms sampling-based semantic entropy at roughly one-tenth the inference cost across seven models and three benchmarks.
What carries the argument
The Hedge-to-Verify Ratio (HVR), which tallies uncertainty expressions such as 'maybe' or 'perhaps' against explicit self-checking statements within the same trace and produces a scalar uncertainty signal.
If this is right
- Zero-hedge traces can be accepted immediately at no added cost.
- The full SELFDOUBT score supplies a usable uncertainty signal for the remaining traces at far lower cost than repeated sampling.
- A simple cascade of the zero-hedge gate followed by the ratio score reaches 90 percent accuracy at 71 percent coverage without labels.
- The method works on any proprietary API because it uses only the final text output.
- Performance holds across BBH, GPQA-Diamond, and MMLU-Pro for seven different models.
Where Pith is reading between the lines
- If hedging patterns prove stable under prompt changes, the same gate could serve as a lightweight safety filter before expensive downstream actions.
- The ratio might be combined with token-level entropy when logits become available to tighten the signal further.
- Extending the same behavioral analysis to multi-turn conversations could flag when a model begins to doubt its own earlier steps.
Load-bearing premise
Hedging markers and self-verification steps in the trace consistently reflect genuine uncertainty rather than stylistic habits that vary by model or prompt.
What would settle it
Prompt a model to insert hedging language on questions it would otherwise answer correctly and check whether the no-hedge accuracy falls well below 96 percent.
Figures




read the original abstract
Uncertainty estimation for reasoning language models remains difficult to deploy in practice: sampling-based methods are computationally expensive, while common single-pass proxies such as verbalized confidence or trace length are often inconsistent across models. This problem is compounded for proprietary reasoning APIs that expose neither logits nor intermediate token probabilities, leaving practitioners with no reliable uncertainty signal at inference time. We propose SELFDOUBT, a single-pass uncertainty framework that resolves this impasse by extracting behavioral signals directly from the reasoning trace itself. Our key signal, the Hedge-to-Verify Ratio (HVR), detects whether a reasoning trace contains uncertainty markers and, if so, whether they are offset by explicit selfchecking behavior. Unlike methods that require multiple sampled traces or model internals, SELFDOUBT operates on a single observed reasoning trajectory, making it suitable for latency- and cost-constrained deployment over any proprietary API. We evaluate SELFDOUBT across seven models and three multi-step reasoning benchmarks (BBH, GPQA-Diamond, and MMLU-Pro). Most notably, traces containing no hedging markers are correct 96% of the time, revealing an emergent high-precision confidence gate at zero additional cost. For the remaining cases, the full SELFDOUBT score significantly outperforms sampling-based semantic entropy at 10x lower inference cost. A deployment cascade combining both stages attains 90% accuracy at 71% coverage without any task-specific labels. These results establish SELFDOUBT as a scalable, production-ready foundation for uncertainty estimation over proprietary reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SELFDOUBT, a single-pass uncertainty quantification method for reasoning LLMs that extracts the Hedge-to-Verify Ratio (HVR) directly from a model's reasoning trace. It claims that traces without hedging markers are correct 96% of the time (providing a zero-cost high-precision gate), that the full HVR score outperforms sampling-based semantic entropy at 10x lower cost on the remaining cases, and that a two-stage cascade achieves 90% accuracy at 71% coverage across seven models on BBH, GPQA-Diamond, and MMLU-Pro without task-specific labels.
Significance. If the empirical results hold under scrutiny, the work would be significant for practical deployment: it offers a label-free, inference-cost-free uncertainty signal usable with proprietary reasoning APIs that expose no logits or internals. The evaluation across seven models and three multi-step reasoning benchmarks, together with the reported cost-accuracy trade-off, provides a concrete foundation for production use cases where sampling-based methods are prohibitive.
major comments (3)
- [Abstract] Abstract: the headline claim that 'traces containing no hedging markers are correct 96% of the time' is presented without error bars, confidence intervals, or per-benchmark breakdowns. Because this statistic is the sole support for the 'emergent high-precision confidence gate at zero additional cost,' the absence of statistical characterization makes it impossible to assess whether the result is robust or sensitive to the particular data splits and model mix.
- [Abstract and §3] Abstract and §3 (method): the hedging-marker detector is described as a fixed, model-agnostic component, yet the manuscript supplies neither the lexicon/regex nor any evidence that the marker set was derived or validated independently of the seven evaluation models and three benchmarks. If marker selection correlates with model-specific stylistic habits on these datasets, the 96% figure and the subsequent HVR cascade become partly artifactual and do not support the generalization claim.
- [Abstract] Abstract: the statement that 'the full SELFDOUBT score significantly outperforms sampling-based semantic entropy at 10x lower inference cost' is given without the precise definition of the semantic-entropy baseline, the number of samples used, or any ablation that isolates the contribution of the verify component of HVR. These omissions are load-bearing for the cost-accuracy superiority claim.
minor comments (2)
- [§3] The notation for HVR is introduced without an explicit equation; a short formal definition (e.g., HVR = #hedge-markers / #verify-statements) would remove ambiguity when the ratio is later used in the cascade rule.
- [§4] Coverage and accuracy figures for the cascade (90% at 71%) are reported as point estimates; adding the corresponding coverage-accuracy curve or threshold-sensitivity plot would clarify the operating range.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the presentation of our results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'traces containing no hedging markers are correct 96% of the time' is presented without error bars, confidence intervals, or per-benchmark breakdowns. Because this statistic is the sole support for the 'emergent high-precision confidence gate at zero additional cost,' the absence of statistical characterization makes it impossible to assess whether the result is robust or sensitive to the particular data splits and model mix.
Authors: We agree that the abstract would benefit from additional statistical context for the 96% figure. This aggregate is computed across all seven models and three benchmarks; per-benchmark values range from 94% to 98%. In the revised manuscript we will add bootstrap confidence intervals to the main results tables and include a concise parenthetical note in the abstract (e.g., “96% [94–98% across benchmarks]”) to allow readers to evaluate robustness directly. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (method): the hedging-marker detector is described as a fixed, model-agnostic component, yet the manuscript supplies neither the lexicon/regex nor any evidence that the marker set was derived or validated independently of the seven evaluation models and three benchmarks. If marker selection correlates with model-specific stylistic habits on these datasets, the 96% figure and the subsequent HVR cascade become partly artifactual and do not support the generalization claim.
Authors: The marker set consists of a fixed list of common English hedging expressions drawn from prior linguistic studies of uncertainty (e.g., “perhaps”, “I think”, “likely”, “not sure”). It was not tuned or selected on the evaluation data. To resolve the reproducibility concern we will append the complete lexicon and the exact regex implementation. We will also add a short out-of-distribution validation on an additional model not used in the main experiments to demonstrate that detection performance does not rely on dataset-specific stylistic artifacts. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'the full SELFDOUBT score significantly outperforms sampling-based semantic entropy at 10x lower inference cost' is given without the precise definition of the semantic-entropy baseline, the number of samples used, or any ablation that isolates the contribution of the verify component of HVR. These omissions are load-bearing for the cost-accuracy superiority claim.
Authors: We will expand the experimental section to give the exact semantic-entropy implementation (following the original formulation with 5 sampled traces per query), report the precise inference-cost multiplier, and include an ablation that compares HVR variants with and without the verify component. These additions will isolate the contribution of each element and make the cost-accuracy comparison fully reproducible. revision: yes
Circularity Check
No circularity: empirical metric with direct benchmark measurements
full rationale
The paper defines SELFDOUBT and the Hedge-to-Verify Ratio as a behavioral extraction method from single reasoning traces, then reports observed statistics (e.g., 96% correctness on no-hedging traces) across fixed benchmarks and models. These are direct empirical counts, not predictions or derivations that reduce to the input definitions by construction. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The marker lexicon is a fixed definitional choice for the metric, not a self-referential loop that forces the reported performance figures.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hedging markers and explicit self-checking in the reasoning trace correlate with actual correctness across models and tasks
invented entities (1)
-
Hedge-to-Verify Ratio (HVR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Trace length is a simple uncertainty signal in reasoning models
URLhttps://arxiv.org/abs/2510.10409. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucina- tions in large language models using semantic entropy.Nature, 630(8017):625–630, Jun
-
[2]
ISSN 1476-4687. doi: 10.1038/s41586-024-07421-0. URL https://doi.org/10.1038/ s41586-024-07421-0. Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. 2025. URL https://arxiv.org/ abs/2507.06261. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, E...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-024-07421-0 2025
-
[3]
URLhttps://arxiv.org/abs/2305.14975. 11 Preprint. Under review. Arne Vanhoyweghen, Brecht Verbeken, Andres Algaba, and Vincent Ginis. Lexical hints of accuracy in llm reasoning chains. 2025. URLhttps://arxiv.org/abs/2508.15842. Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. Latent space chain-of-embedding enables output-free llm self-e...
-
[4]
This includes exact-match formatting mismatches (e.g., false vs
Grading or answer-key issue.The model answer is semantically correct, or at least as defensible as the key, but is scored as incorrect because of a benchmark artifact. This includes exact-match formatting mismatches (e.g., false vs. False), option-letter vs. full-option-text mismatches, duplicate or semantically equivalent answer options, and 14 Preprint....
-
[5]
Ambiguous question or ambiguous label.The prompt admits multiple defensible inter- pretations, or the benchmark label draws a boundary that is not uniquely determined by the problem statement.Decision rule:if a reasonable expert could defend both the model answer and the benchmark answer, assign this category
-
[6]
Confidence: [0-100]%
Genuinely wrong confident prediction.The model answer is clearly inconsistent with the problem or gold option, and no grading artifact or ambiguity explains the discrepancy.Decision rule:assign this category only after (1) and (2) are ruled out. This is the residual category. Headline audit result.Table 10 shows the pooled result. Of the 54 apparent HVR =...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.