Recognition: 2 theorem links
· Lean TheoremART: Attention Replacement Technique to Improve Factuality in LLMs
Pith reviewed 2026-05-10 19:44 UTC · model grok-4.3
The pith
Replacing uniform attention in shallow LLM layers with local patterns reduces hallucinations without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
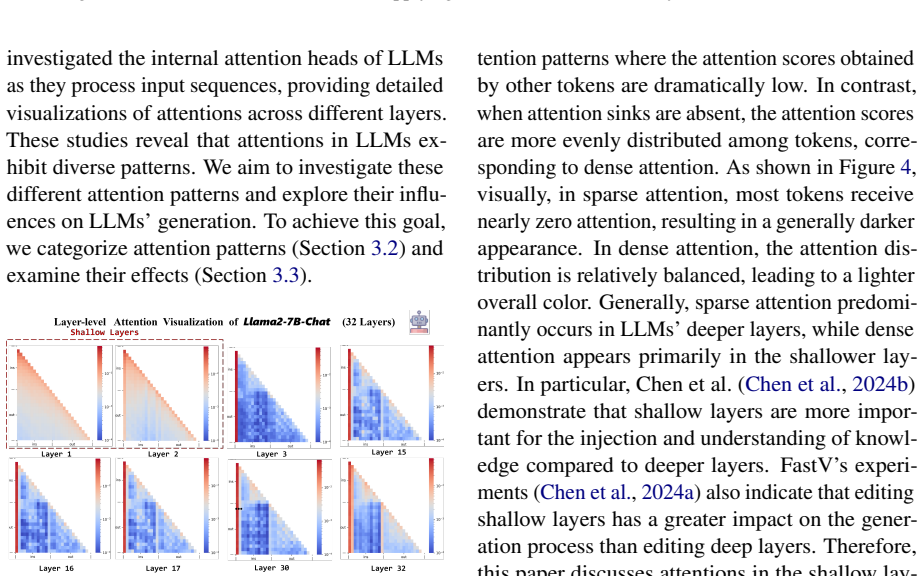
Shallow layers of LLMs primarily rely on uniform attention patterns that distribute attention evenly across the sequence, causing the model to fail to focus on the most relevant information and thereby producing hallucinations. The Attention Replacement Technique replaces these uniform patterns with local attention patterns in the shallow layers, which directs the model to focus more on relevant contexts and reduces hallucinations.
What carries the argument
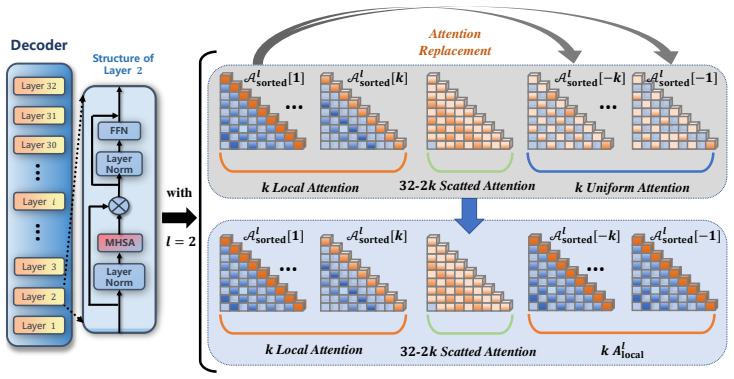
Attention Replacement Technique (ART) that identifies and replaces uniform attention patterns in shallow layers with local attention patterns.
Load-bearing premise
Uniform attention patterns in shallow layers directly cause hallucinations by preventing focus on relevant information, and local replacement will fix this without side effects.
What would settle it
Running the same evaluation benchmarks on models with and without the attention replacement and finding no decrease or an increase in hallucination rates.
Figures



read the original abstract
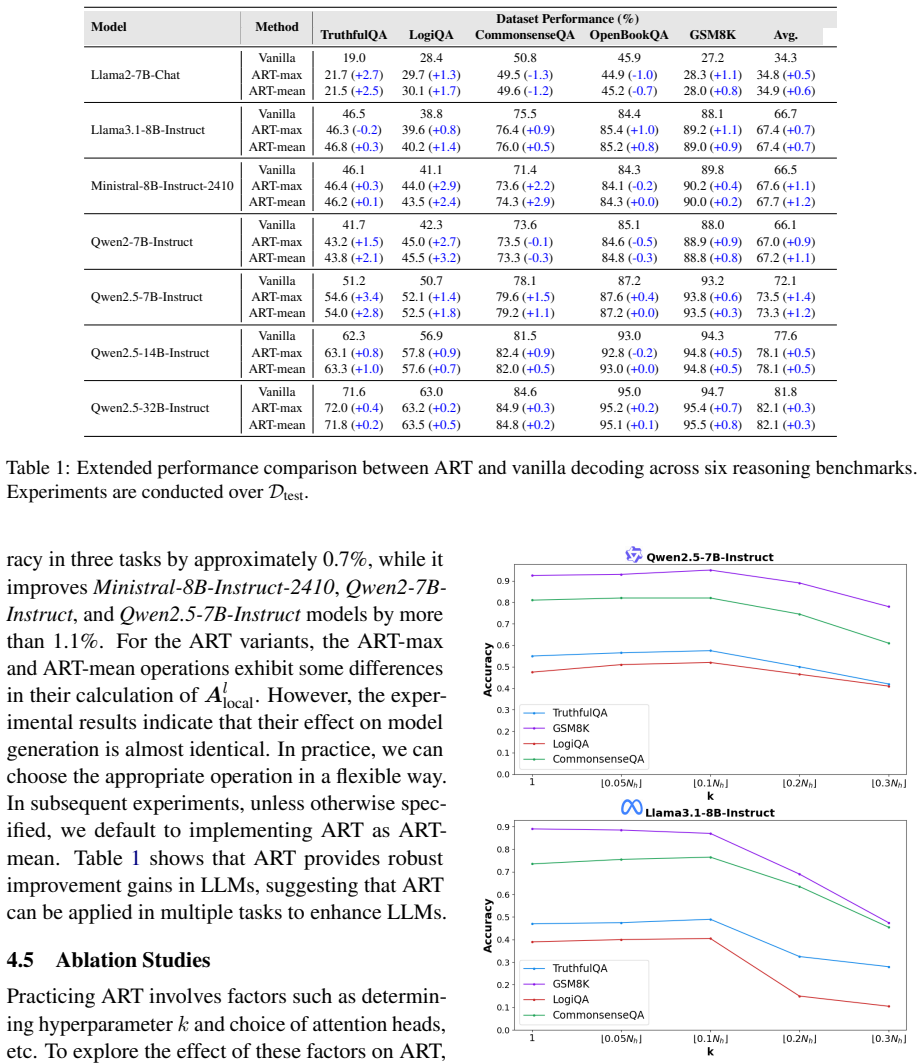
Hallucination in large language models (LLMs) continues to be a significant issue, particularly in tasks like question answering, where models often generate plausible yet incorrect or irrelevant information. Although various methods have been proposed to mitigate hallucinations, the relationship between attention patterns and hallucinations has not been fully explored. In this paper, we analyze the distribution of attention scores across each layer and attention head of LLMs, revealing a common and intriguing phenomenon: shallow layers of LLMs primarily rely on uniform attention patterns, where the model distributes its attention evenly across the entire sequence. This uniform attention pattern can lead to hallucinations, as the model fails to focus on the most relevant information. To mitigate this issue, we propose a training-free method called Attention Replacement Technique (ART), which replaces these uniform attention patterns in the shallow layers with local attention patterns. This change directs the model to focus more on the relevant contexts, thus reducing hallucinations. Through extensive experiments, ART demonstrates significant reductions in hallucinations across multiple LLM architectures, proving its effectiveness and generalizability without requiring fine-tuning or additional training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that shallow layers of LLMs exhibit uniform attention patterns that cause hallucinations by failing to focus on relevant information. It proposes the training-free Attention Replacement Technique (ART) to replace these uniform patterns with local attention patterns in shallow layers, thereby directing attention to relevant contexts and reducing hallucinations. The paper asserts that extensive experiments demonstrate significant reductions in hallucinations across multiple LLM architectures without requiring fine-tuning or additional training data.
Significance. If the central claims hold, ART offers a lightweight, training-free intervention applicable to existing LLMs that could meaningfully improve factuality in tasks such as question answering. The approach is notable for its generality across architectures and lack of retraining requirements, which would make it practical for deployment.
major comments (2)
- [Abstract] Abstract: The abstract states that 'extensive experiments' show 'significant reductions in hallucinations' but supplies no metrics, baselines, statistical details, ablation results, or quantitative values, preventing assessment of whether the data support the headline claim.
- [Method/Experiments] Method and Experiments sections: The causal claim that uniform shallow-layer attention produces hallucinations (rather than being a downstream correlate) rests on observation plus post-intervention improvement. The manuscript does not report controls that substitute non-local but still non-uniform patterns, nor does it measure whether attention mass on ground-truth relevant spans increases after replacement; without these, the reduction could arise from any disruptive change to early-layer attention.
minor comments (1)
- [Abstract] Abstract: Adding at least one concrete quantitative result (e.g., hallucination rate reduction on a named benchmark) would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each of the major comments below in a point-by-point manner and indicate the changes we will make to the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that 'extensive experiments' show 'significant reductions in hallucinations' but supplies no metrics, baselines, statistical details, ablation results, or quantitative values, preventing assessment of whether the data support the headline claim.
Authors: We concur that the abstract lacks specific quantitative details, which limits the ability to evaluate the strength of the claims. To address this, we will revise the abstract in the next version of the manuscript to incorporate key results, including average hallucination reduction percentages across models and tasks, comparisons with baseline methods, and references to the statistical significance of the improvements. This revision will maintain the abstract's conciseness while providing essential evidence. revision: yes
-
Referee: [Method/Experiments] Method and Experiments sections: The causal claim that uniform shallow-layer attention produces hallucinations (rather than being a downstream correlate) rests on observation plus post-intervention improvement. The manuscript does not report controls that substitute non-local but still non-uniform patterns, nor does it measure whether attention mass on ground-truth relevant spans increases after replacement; without these, the reduction could arise from any disruptive change to early-layer attention.
Authors: We appreciate this critique on establishing causality. The manuscript presents observational evidence of uniform attention in shallow layers and demonstrates that targeted replacement with local patterns reduces hallucinations. However, we acknowledge the absence of the suggested controls. In the revised manuscript, we will include additional experiments: an ablation study replacing shallow-layer attention with non-uniform but non-local patterns (such as randomly perturbed attention) to show that not all disruptions improve performance, and we will quantify the change in attention mass allocated to ground-truth relevant context spans before and after applying ART. These additions will help isolate the effect of the local pattern specifically. revision: yes
Circularity Check
No circularity: empirical observation plus heuristic intervention
full rationale
The paper reports an empirical analysis of attention score distributions across layers and heads, notes the prevalence of uniform patterns in shallow layers, posits that these patterns hinder focus on relevant tokens, and introduces the ART replacement rule as a direct, training-free fix. No equations, fitted parameters, or derived predictions appear; the central claim rests on the observed distribution and the measured post-intervention hallucination drop rather than any self-referential definition or statistical forcing. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The chain is therefore self-contained observational work plus intervention testing and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uniform attention patterns in shallow layers cause hallucinations by failing to focus on the most relevant information.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearshallow layers of LLMs primarily rely on uniform attention patterns... replaces these uniform attention patterns in the shallow layers with local attention patterns
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearm-index ml_h ... smaller ml_h ... uniform attention
Reference graph
Works this paper leans on
-
[1]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Jun- yang Lin, Chang Zhou, and Baobao Chang
Count- ing circuits: Mechanistic interpretability of visual reasoning in large vision-language models.arXiv preprint arXiv:2603.18523. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Jun- yang Lin, Chang Zhou, and Baobao Chang. 2024a. An image is worth 1/2 tokens after layer 2: Plug-and- play inference acceleration for large vision-language models. InProc...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, and Zhongyuan Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Not all layers of LLMs are necessary during inference.arXiv preprint arXiv:2403.02181, 2024
Not all layers of llms are necessary during inference.arXiv preprint arXiv:2403.02181. Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu
-
[4]
Zeru Shi, Kai Mei, Yihao Quan, Dimitris N Metaxas, and Ruixiang Tang
Reinforcing consistency in video mllms with structured rewards.arXiv preprint arXiv:2604.01460. Zeru Shi, Kai Mei, Yihao Quan, Dimitris N Metaxas, and Ruixiang Tang
-
[5]
Improving visual reason- ing with iterative evidence refinement.arXiv preprint arXiv:2603.14117. Zeru Shi, Yingjia Wan, Zhenting Wang, Qifan Wang, Fan Yang, Elisa Kreiss, and Ruixiang Tang
-
[6]
Meaningless tokens, meaningful gains: How activa- tion shifts enhance llm reasoning.arXiv preprint arXiv:2510.01032. Qi Sun, Marc Pickett, Aakash Kumar Nain, and Llion Jones
-
[7]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant
Transformer layers as painters.arXiv preprint arXiv:2407.09298. Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat mod- els.arXiv preprint arXiv:2307.09288. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
InAd- vances in Neural Information Processing Systems 35 (NIPS)
Chain-of-thought prompting elicits reasoning in large language models. InAd- vances in Neural Information Processing Systems 35 (NIPS). Jinfeng Wei and Xiaofeng Zhang. 2024a. Dopra: Decoding over-accumulation penalization and re- allocation in specific weighting layer.Proceedings of the 32nd ACM International Conference on Multi- media. Jinfeng Wei and Xi...
-
[10]
Retrieval head mechanisti- cally explains long-context factuality.arXiv preprint arXiv:2404.15574. Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. 2024a. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819. Guangxuan Xiao, Yuandong Tia...
-
[11]
Qwen2 technical report. arXiv preprint arXiv:2407.10671. Fangcong Yin, Xi Ye, and Greg Durrett
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Lofit: Localized fine-tuning on llm representations.arXiv preprint arXiv:2406.01563. Zhongzhi Yu, Zheng Wang, Yonggan Fu, Huihong Shi, Khalid Shaikh, and Yingyan Celine Lin
-
[13]
Boxuan Zhang, Yi Yu, Jiaxuan Guo, and Jing Shao
Instance-adaptive zero-shot chain-of-thought prompting.arXiv preprint arXiv:2409.20441. Boxuan Zhang, Yi Yu, Jiaxuan Guo, and Jing Shao. 2025a. Dive into the agent matrix: A realistic eval- uation of self-replication risk in llm agents.arXiv preprint arXiv:2509.25302. Boxuan Zhang and Ruqi Zhang
-
[14]
InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 26114–26133
Cot-uq: Improv- ing response-wise uncertainty quantification in llms with chain-of-thought. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 26114–26133. Xiaofeng Zhang, Yihao Quan, Chaochen Gu, Chen Shen, Xiaosong Yuan, Shaotian Yan, Hao Cheng, Kaijie Wu, and Jieping Ye
2025
-
[15]
Seeing clearly by layer two: Enhancing attention heads to al- leviate hallucination in lvlms.arXiv preprint arXiv:2411.09968. Xiaofeng Zhang, Yihao Quan, Chen Shen, Chaochen Gu, Xiaosong Yuan, Shaotian Yan, Jiawei Cao, Hao Cheng, Kaijie Wu, and Jieping Ye. 2025b. Shal- low focus, deep fixes: Enhancing shallow layers vi- sion attention sinks to alleviate h...
-
[16]
Attention heads of large language models: A survey.arXiv preprint arXiv:2409.03752,
Attention heads of large language models: A survey.arXiv preprint arXiv:2409.03752. Guanyu Zhou, Yibo Yan, Xin Zou, Kun Wang, Aiwei Liu, and Xuming Hu
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.