Recognition: 2 theorem links
· Lean TheoremVisual prompting reimagined: The power of the Activation Prompts
Pith reviewed 2026-05-10 18:48 UTC · model grok-4.3
The pith
Activation prompts on intermediate layers outperform input visual prompts in accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
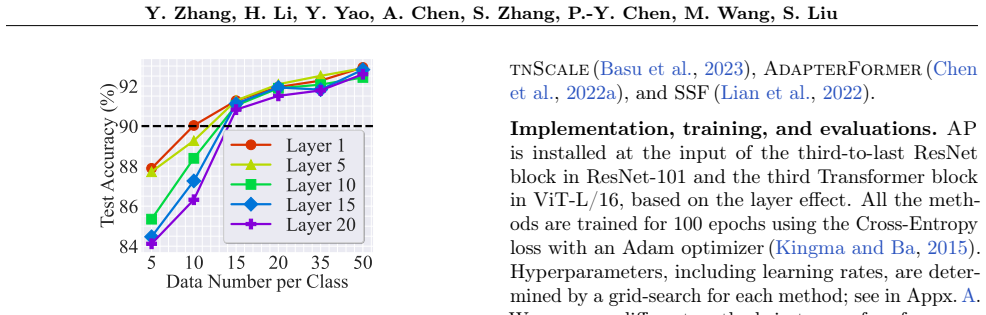
Activation prompts extend visual prompting by permitting universal perturbations on intermediate activation maps instead of the input alone. This formulation exposes the performance and efficiency limits of input-level visual prompting and demonstrates that activation prompts exhibit model-dependent layer preferences, linked to normalization tuning in CNNs and vision transformers. A theoretical analysis of global features across layers accounts for the observed preferences. Comprehensive tests on 29 datasets establish that activation prompts surpass both visual prompting and parameter-efficient baselines in accuracy while improving time, parameter count, memory footprint, and throughput.
What carries the argument
Activation prompt (AP), a universal perturbation applied to activation maps at chosen intermediate layers that enables task adaptation without altering model parameters.
If this is right
- Activation prompts narrow the accuracy gap between prompting methods and full fine-tuning while preserving parameter efficiency.
- Optimal prompt placement differs systematically between convolutional networks and vision transformers.
- Activation prompts connect directly to normalization-tuning techniques already used in both model families.
- The method improves the accuracy-efficiency trade-off relative to input-only visual prompting on diverse tasks.
Where Pith is reading between the lines
- The layer-selection principle derived from global features could be turned into an automatic rule for choosing prompt positions on unseen models.
- Similar intermediate-layer perturbation ideas may transfer to other pretrained models such as language or multimodal transformers.
- Combining activation prompts with existing normalization adaptation methods could yield further gains in efficiency.
Load-bearing premise
The layer preferences observed for activation prompts in the tested models generalize to other architectures, and the global-feature analysis correctly predicts those preferences without post-hoc selection.
What would settle it
On a new model architecture, if input-level visual prompting matches or exceeds activation prompting in both accuracy and efficiency metrics, or if the empirically best layer contradicts the global-feature prediction, the superiority and explanatory claims would be refuted.
Figures





read the original abstract
Visual prompting (VP) has emerged as a popular method to repurpose pretrained vision models for adaptation to downstream tasks. Unlike conventional model fine-tuning techniques, VP introduces a universal perturbation directly into the input data to facilitate task-specific fine-tuning rather than modifying model parameters. However, there exists a noticeable performance gap between VP and conventional fine-tuning methods, highlighting an unexplored realm in theory and practice to understand and advance the input-level VP to reduce its current performance gap. Towards this end, we introduce a generalized concept, termed activation prompt (AP), which extends the scope of the input-level VP by enabling universal perturbations to be applied to activation maps within the intermediate layers of the model. By using AP to revisit the problem of VP and employing it as an analytical tool, we demonstrate the intrinsic limitations of VP in both performance and efficiency, revealing why input-level prompting may lack effectiveness compared to AP, which exhibits a model-dependent layer preference. We show that AP is closely related to normalization tuning in convolutional neural networks and vision transformers, although each model type has distinct layer preferences for prompting. We also theoretically elucidate the rationale behind such a preference by analyzing global features across layers. Through extensive experiments across 29 datasets and various model architectures, we provide a comprehensive performance analysis of AP, comparing it with VP and parameter-efficient fine-tuning baselines. Our results demonstrate AP's superiority in both accuracy and efficiency, considering factors such as time, parameters, memory usage, and throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Activation Prompts (AP) as a generalization of input-level Visual Prompting (VP), allowing universal perturbations on intermediate activation maps. It reports model-dependent layer preferences (distinct for CNNs versus ViTs), supplies a theoretical analysis of global feature statistics across layers to explain these preferences, and claims through experiments on 29 datasets that AP outperforms both VP and parameter-efficient fine-tuning baselines in accuracy while also improving efficiency metrics such as time, parameters, memory usage, and throughput.
Significance. If the superiority claims hold with a non-oracle layer selection procedure, the work would advance efficient adaptation of pretrained vision models by closing the performance gap between prompting and fine-tuning. The broad empirical scope across 29 datasets and the attempt at theoretical explanation of layer preferences are strengths that could inform future prompting research if the analysis yields a predictive rather than post-hoc rule.
major comments (2)
- [Theoretical Analysis and Experiments] The central superiority claim depends on placing the activation prompt at a model-specific layer. The theoretical analysis of global features is invoked to explain the observed CNN versus ViT preferences, yet it is not evident whether this analysis supplies an a priori, parameter-free selection rule for unseen architectures. If layer choice was instead determined by validation performance on the same 29 datasets used for the final reported numbers, the accuracy and efficiency margins over VP become conditional on oracle knowledge unavailable at deployment.
- [Experiments] The abstract states that AP exhibits superiority in both accuracy and efficiency across 29 datasets, but provides no mention of error bars, standard deviations across runs, or ablation tables isolating the contribution of the chosen layer versus the prompting mechanism itself. Without these, it is impossible to determine whether the reported gains are statistically robust or sensitive to the particular layer selections.
minor comments (2)
- [Abstract] The abstract refers to 'distinct layer preferences' and a 'theoretical elucidation' but does not summarize the key derivation steps or name the specific layers preferred by each architecture family.
- Notation for how activation prompts are initialized, optimized, and injected relative to standard VP is not previewed, which would aid readability before the detailed method section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of layer selection and experimental rigor that we address point by point below. We have revised the manuscript accordingly where possible while maintaining the integrity of our claims.
read point-by-point responses
-
Referee: The central superiority claim depends on placing the activation prompt at a model-specific layer. The theoretical analysis of global features is invoked to explain the observed CNN versus ViT preferences, yet it is not evident whether this analysis supplies an a priori, parameter-free selection rule for unseen architectures. If layer choice was instead determined by validation performance on the same 29 datasets used for the final reported numbers, the accuracy and efficiency margins over VP become conditional on oracle knowledge unavailable at deployment.
Authors: We agree that a fully a priori, parameter-free rule would strengthen deployability. Our theoretical analysis of global feature statistics (Section 4) explains the preferences by showing that CNNs benefit from prompting at layers with high global feature variance (typically early layers) while ViTs prefer mid-layers due to attention aggregation. This is not yet a complete predictive formula for arbitrary new models, but it provides a model-type-based heuristic (e.g., layer index proportional to depth for CNNs). Layer selection in experiments combined this heuristic with a small held-out validation split per dataset (not the test sets), using 5-10% of data. We will add a new subsection clarifying this procedure, include a table of selected layers per architecture, and report results using only the heuristic without per-dataset validation to show robustness. This addresses the oracle concern while preserving the reported gains. revision: partial
-
Referee: The abstract states that AP exhibits superiority in both accuracy and efficiency across 29 datasets, but provides no mention of error bars, standard deviations across runs, or ablation tables isolating the contribution of the chosen layer versus the prompting mechanism itself. Without these, it is impossible to determine whether the reported gains are statistically robust or sensitive to the particular layer selections.
Authors: We acknowledge the abstract's omission of statistical details due to length limits. The full paper reports means and standard deviations over three independent runs in all tables (e.g., Table 2 and supplementary tables) and includes error bars in figures. To isolate layer choice from the AP mechanism, we will add a dedicated ablation section comparing: (i) AP at theoretically guided layers, (ii) AP at fixed suboptimal layers, and (iii) input VP. This demonstrates that gains stem primarily from the activation-level perturbation rather than layer selection alone. We will also update the abstract to state 'results averaged over three runs with standard deviations' and ensure all claims reference these statistics. revision: yes
Circularity Check
No significant circularity; claims rest on independent empirical and theoretical analysis
full rationale
The paper defines activation prompts as a direct extension of input-level visual prompting and supports superiority claims via theoretical analysis of global feature statistics across layers plus empirical comparisons on 29 datasets against VP and PEFT baselines. No equations, fitted parameters, or self-citations are presented that reduce the reported accuracy/efficiency gains or layer preferences to definitions or inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclearAP at layer l: g(z^(l), δ^(l)) = z^(l) + δ^(l); connection to unit-scaling BatchNorm/LayerNorm; layer preference tied to global vs. local features via CKA and average attention distance.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclearTheorem 1: sample complexity N1 = Θ(P) for shallow AP vs. N2 = Θ(P² log P) for deep AP under global-feature attention assumptions.
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Vicuna: An open-source chatbot impressing gpt-4 with 90\ See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90\ See https://vicuna. lmsys. org (accessed 14 April 2023), 2023
2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023 a
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
arXiv preprint arXiv:2301.00774 , year=
Elias Frantar and Dan Alistarh. Massive language models can be accurately pruned in one-shot. arXiv preprint arXiv:2301.00774, 2023
-
[5]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. arXiv preprint arXiv:2203.12119, 2022
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Tinytl: Reduce memory, not parameters for efficient on-device learning
Han Cai, Chuang Gan, Ligeng Zhu, and Song Han. Tinytl: Reduce memory, not parameters for efficient on-device learning. Advances in Neural Information Processing Systems, 33: 0 11285--11297, 2020
2020
-
[8]
Lst: Ladder side-tuning for parameter and memory efficient transfer learning
Yi-Lin Sung, Jaemin Cho, and Mohit Bansal. Lst: Ladder side-tuning for parameter and memory efficient transfer learning. Advances in Neural Information Processing Systems, 35: 0 12991--13005, 2022
2022
-
[9]
Understanding and improving visual prompting: A label-mapping perspective
Aochuan Chen, Yuguang Yao, Pin-Yu Chen, Yihua Zhang, and Sijia Liu. Understanding and improving visual prompting: A label-mapping perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19133--19143, 2023 a
2023
-
[10]
Adaptformer: Adapting vision transformers for scalable visual recognition
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems, 35: 0 16664--16678, 2022 a
2022
-
[11]
Adapterhub: A framework for adapting transformers
Jonas Pfeiffer, Andreas R \"u ckl \'e , Clifton Poth, Aishwarya Kamath, Ivan Vuli \'c , Sebastian Ruder, Kyunghyun Cho, and Iryna Gurevych. Adapterhub: A framework for adapting transformers. arXiv preprint arXiv:2007.07779, 2020
-
[12]
Towards a unified view of parameter-efficient transfer learning,
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2021
-
[13]
Exploring efficient few-shot adaptation for vision transformers
Chengming Xu, Siqian Yang, Yabiao Wang, Zhanxiong Wang, Yanwei Fu, and Xiangyang Xue. Exploring efficient few-shot adaptation for vision transformers. arXiv preprint arXiv:2301.02419, 2023
-
[14]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55 0 (9): 0 1--35, 2023
2023
-
[15]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021
work page internal anchor Pith review arXiv 2021
-
[17]
Adversarial reprogramming of neural networks
Gamaleldin F Elsayed, Ian Goodfellow, and Jascha Sohl-Dickstein. Adversarial reprogramming of neural networks. arXiv preprint arXiv:1806.11146, 2018
-
[18]
Model reprogramming: Resource-efficient cross-domain machine learning
Pin-Yu Chen. Model reprogramming: Resource-efficient cross-domain machine learning. arXiv preprint arXiv:2202.10629, 2022
-
[19]
Cross-modal adversarial reprogramming
Paarth Neekhara, Shehzeen Hussain, Jinglong Du, Shlomo Dubnov, Farinaz Koushanfar, and Julian McAuley. Cross-modal adversarial reprogramming. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2427--2435, 2022
2022
-
[20]
Fairness reprogramming
Guanhua Zhang, Yihua Zhang, Yang Zhang, Wenqi Fan, Qing Li, Sijia Liu, and Shiyu Chang. Fairness reprogramming. Advances in Neural Information Processing Systems, 35: 0 34347--34362, 2022
2022
-
[21]
Visual prompting for adversarial robustness
Aochuan Chen, Peter Lorenz, Yuguang Yao, Pin-Yu Chen, and Sijia Liu. Visual prompting for adversarial robustness. arXiv preprint arXiv:2210.06284, 2022 b
-
[22]
Adversarial reprogramming of pretrained neural networks for fraud detection
Lingwei Chen, Yujie Fan, and Yanfang Ye. Adversarial reprogramming of pretrained neural networks for fraud detection. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 2935--2939, 2021
2021
-
[23]
From visual prompt learning to zero-shot transfer: Mapping is all you need
Ziqing Yang, Zeyang Sha, Michael Backes, and Yang Zhang. From visual prompt learning to zero-shot transfer: Mapping is all you need. arXiv preprint arXiv:2303.05266, 2023
-
[24]
Unleashing the power of visual prompting at the pixel level
Junyang Wu, Xianhang Li, Chen Wei, Huiyu Wang, Alan Yuille, Yuyin Zhou, and Cihang Xie. Unleashing the power of visual prompting at the pixel level. arXiv preprint arXiv:2212.10556, 2022
-
[25]
Visual prompting for adversarial robustness
Aochuan Chen, Peter Lorenz, Yuguang Yao, Pin-Yu Chen, and Sijia Liu. Visual prompting for adversarial robustness. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE, 2023 b
2023
-
[26]
Understanding zero-shot adversarial robustness for large-scale models
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl Vondrick. Understanding zero-shot adversarial robustness for large-scale models. arXiv preprint arXiv:2212.07016, 2022
-
[27]
Diversity-aware meta visual prompting
Qidong Huang, Xiaoyi Dong, Dongdong Chen, Weiming Zhang, Feifei Wang, Gang Hua, and Nenghai Yu. Diversity-aware meta visual prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10878--10887, 2023 a
2023
-
[28]
Self-supervised convolutional visual prompts
Yun-Yun Tsai, Chengzhi Mao, Yow-Kuan Lin, and Junfeng Yang. Self-supervised convolutional visual prompts. arXiv preprint arXiv:2303.00198, 2023
-
[29]
Learning to prompt for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130 0 (9): 0 2337--2348, 2022
2022
-
[30]
Why do pretrained language models help in downstream tasks? an analysis of head and prompt tuning
Colin Wei, Sang Michael Xie, and Tengyu Ma. Why do pretrained language models help in downstream tasks? an analysis of head and prompt tuning. Advances in Neural Information Processing Systems, 34: 0 16158--16170, 2021
2021
-
[31]
Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. arXiv preprint arXiv:2306.04637, 2023 b
-
[32]
What learning algorithm is in-context learning? investigations with linear models
Ekin Aky \"u rek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. In The Eleventh International Conference on Learning Representations, 2022
2022
-
[33]
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models. arXiv preprint arXiv:2203.06904, 2022
-
[34]
Transformers learn in-context by gradient descent
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo \ a o Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pages 35151--35174. PMLR, 2023
2023
-
[35]
An explanation of in-context learning as implicit bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. In International Conference on Learning Representations, 2021
2021
-
[36]
On the role of attention in prompt-tuning
Samet Oymak, Ankit Singh Rawat, Mahdi Soltanolkotabi, and Christos Thrampoulidis. On the role of attention in prompt-tuning. arXiv preprint arXiv:2306.03435, 2023
-
[37]
Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-context. arXiv preprint arXiv:2306.09927, 2023
-
[38]
Transformers as algorithms: Generalization and stability in in-context learning
Yingcong Li, Muhammed Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. Transformers as algorithms: Generalization and stability in in-context learning. In International Conference on Machine Learning, 2023 a
2023
-
[40]
Hongkang Li, Meng Wang, Songtao Lu, Xiaodong Cui, and Pin-Yu Chen. Training nonlinear transformers for efficient in-context learning: A theoretical learning and generalization analysis. arXiv preprint arXiv:2402.15607, 2024 a
-
[41]
Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis
Hongkang Li, Songtao Lu, Pin-Yu Chen, Xiaodong Cui, and Meng Wang. Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis. In The Thirteenth International Conference on Learning Representations, 2025 a
2025
-
[42]
How do nonlinear transformers acquire generalization-guaranteed cot ability? In High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning, 2024 b
Hongkang Li, Meng Wang, Songtao Lu, Xiaodong Cui, and Pin-Yu Chen. How do nonlinear transformers acquire generalization-guaranteed cot ability? In High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning, 2024 b
2024
-
[43]
Understanding mamba in in-context learning with outliers: A theoretical generalization analysis
Hongkang Li, Songtao Lu, Xiaodong Cui, Pin-Yu Chen, and Meng Wang. Understanding mamba in in-context learning with outliers: A theoretical generalization analysis. In High-dimensional Learning Dynamics 2025, 2025 b . URL https://openreview.net/forum?id=DHyGZHBZci
2025
-
[44]
Strong baselines for parameter efficient few-shot fine-tuning
Samyadeep Basu, Daniela Massiceti, Shell Xu Hu, and Soheil Feizi. Strong baselines for parameter efficient few-shot fine-tuning. arXiv preprint arXiv:2304.01917, 2023
-
[45]
Compacter: Efficient low-rank hypercomplex adapter layers
Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing Systems, 34: 0 1022--1035, 2021
2021
-
[46]
Scaling & shifting your features: A new baseline for efficient model tuning
Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: A new baseline for efficient model tuning. Advances in Neural Information Processing Systems, 35: 0 109--123, 2022
2022
-
[47]
Towards efficient visual adaption via structural re-parameterization,
Gen Luo, Minglang Huang, Yiyi Zhou, Xiaoshuai Sun, Guannan Jiang, Zhiyu Wang, and Rongrong Ji. Towards efficient visual adaption via structural re-parameterization. arXiv preprint arXiv:2302.08106, 2023
-
[48]
Learning on transformers is provable low-rank and sparse: A one-layer analysis
Hongkang Li, Meng Wang, Shuai Zhang, Sijia Liu, and Pin-Yu Chen. Learning on transformers is provable low-rank and sparse: A one-layer analysis. arXiv preprint arXiv:2406.17167, 2024 c
-
[49]
Fact: Factor-tuning for lightweight adaptation on vision transformer
Shibo Jie and Zhi-Hong Deng. Fact: Factor-tuning for lightweight adaptation on vision transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 1060--1068, 2023
2023
-
[50]
Exploring visual prompts for adapting large- scale models
Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Exploring visual prompts for adapting large-scale models. arXiv preprint arXiv:2203.17274, 2022 b
-
[51]
Exploiting the complementary strengths of multi-layer cnn features for image retrieval
Wei Yu, Kuiyuan Yang, Hongxun Yao, Xiaoshuai Sun, and Pengfei Xu. Exploiting the complementary strengths of multi-layer cnn features for image retrieval. Neurocomputing, 237: 0 235--241, 2017
2017
-
[52]
Network dissection: Quantifying interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6541--6549, 2017
2017
-
[53]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[54]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248--255. Ieee, 2009
2009
-
[55]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. cs.utoronto.ca, 2009
2009
-
[56]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448--456. pmlr, 2015
2015
-
[57]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[58]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition, pages 3498--3505. IEEE, 2012
2012
-
[59]
Algorithms for learning kernels based on centered alignment
Corinna Cortes, Mehryar Mohri, and Afshin Rostamizadeh. Algorithms for learning kernels based on centered alignment. The Journal of Machine Learning Research, 13 0 (1): 0 795--828, 2012
2012
-
[60]
Do vision transformers see like convolutional neural networks? Advances in Neural Information Processing Systems, 34: 0 12116--12128, 2021
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks? Advances in Neural Information Processing Systems, 34: 0 12116--12128, 2021
2021
-
[61]
Teaching matters: Investigating the role of supervision in vision transformers
Matthew Walmer, Saksham Suri, Kamal Gupta, and Abhinav Shrivastava. Teaching matters: Investigating the role of supervision in vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7486--7496, 2023
2023
-
[62]
arXiv preprint arXiv:2302.06015 , year=
Hongkang Li, Meng Wang, Sijia Liu, and Pin-Yu Chen. A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity. arXiv preprint arXiv:2302.06015, 2023 b
-
[63]
In-context convergence of transformers.arXiv preprint arXiv:2310.05249,
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. arXiv preprint arXiv:2310.05249, 2023 c
-
[64]
How transformers learn causal structure with gradient descent
Eshaan Nichani, Alex Damian, and Jason D Lee. How transformers learn causal structure with gradient descent. arXiv preprint arXiv:2402.14735, 2024
-
[65]
A theoretical analysis on feature learning in neural networks: Emergence from inputs and advantage over fixed features
Zhenmei Shi, Junyi Wei, and Yingyu Liang. A theoretical analysis on feature learning in neural networks: Emergence from inputs and advantage over fixed features. In International Conference on Learning Representations, 2022
2022
-
[66]
Toward understanding the feature learning process of self-supervised contrastive learning
Zixin Wen and Yuanzhi Li. Toward understanding the feature learning process of self-supervised contrastive learning. In International Conference on Machine Learning, pages 11112--11122. PMLR, 2021
2021
-
[67]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[68]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115: 0 211--252, 2015
2015
-
[69]
S. Maji, J. Kannala, E. Rahtu, M. Blaschko, and A. Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review arXiv 2013
-
[70]
A large-scale study of representation learning with the visual task adaptation benchmark
Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv preprint arXiv:1910.04867, 2019
-
[71]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[72]
Detection of traffic signs in real-world images: The G erman T raffic S ign D etection B enchmark
Sebastian Houben, Johannes Stallkamp, Jan Salmen, Marc Schlipsing, and Christian Igel. Detection of traffic signs in real-world images: The G erman T raffic S ign D etection B enchmark. In International Joint Conference on Neural Networks, 2013
2013
-
[73]
Food-101--mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101--mining discriminative components with random forests. In European conference on computer vision, pages 446--461. Springer, 2014
2014
-
[74]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731, 2019
work page internal anchor Pith review arXiv 1911
-
[75]
Improving visual prompt tuning for self-supervised vision transformers
Seungryong Yoo, Eunji Kim, Dahuin Jung, Jungbeom Lee, and Sungroh Yoon. Improving visual prompt tuning for self-supervised vision transformers. In International Conference on Machine Learning, pages 40075--40092. PMLR, 2023
2023
-
[76]
E\^ 2vpt: An effective and efficient approach for visual prompt tuning
Cheng Han, Qifan Wang, Yiming Cui, Zhiwen Cao, Wenguan Wang, Siyuan Qi, and Dongfang Liu. E\^ 2vpt: An effective and efficient approach for visual prompt tuning. arXiv preprint arXiv:2307.13770, 2023
-
[77]
Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021
-
[78]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. 2015 ICLR, arXiv preprint arXiv:1412.6980, 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[79]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748--8763. PMLR, 2021
2021
-
[80]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012--10022, 2021
2021
-
[81]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, pages 722--729. IEEE, 2008
2008
-
[82]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606--3613, 2014
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.