Recognition: 2 theorem links
· Lean TheoremLearning to Interrupt in Language-based Multi-agent Communication
Pith reviewed 2026-05-10 19:04 UTC · model grok-4.3
The pith
A learned policy lets listener agents interrupt speakers in LLM multi-agent setups to cut communication costs by 32 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Predicting interruption points from estimates of future reward and communication cost produces an effective listener policy that reduces overall message volume by 32.2 percent relative to non-interruptible baselines while preserving or improving task performance across text pictionary, meeting scheduling, and debate scenarios, and that this policy generalizes to new agent combinations and task types.
What carries the argument
HANDRAISER, a learned predictor that selects interruption points by weighing estimated future task reward against the cost of continued speaking.
If this is right
- Multi-agent LLM systems can complete the same tasks with substantially fewer tokens exchanged overall.
- The underlying language models themselves do not need retraining to gain these efficiency improvements.
- The same interruption policy works across agent counts and task domains without modification.
- Listeners gain the ability to request clarification or state partial beliefs at moments that actually help the group.
Where Pith is reading between the lines
- Combining listener-side interruption with existing speaker-side message compression could produce further savings.
- The approach might transfer to single-model settings where an LLM decides when to pause its own generation and query the user.
- Large-scale deployments could see meaningful drops in API token spend once the interruption policy is learned once and reused.
Load-bearing premise
The interruption predictor trained on reward and cost estimates will continue to select useful stopping points when applied to different agents or tasks without retraining or retuning.
What would settle it
Running the trained interruption policy on a new multi-agent task and measuring whether total communication length stays the same or increases while task success falls below the no-interruption baseline.
Figures



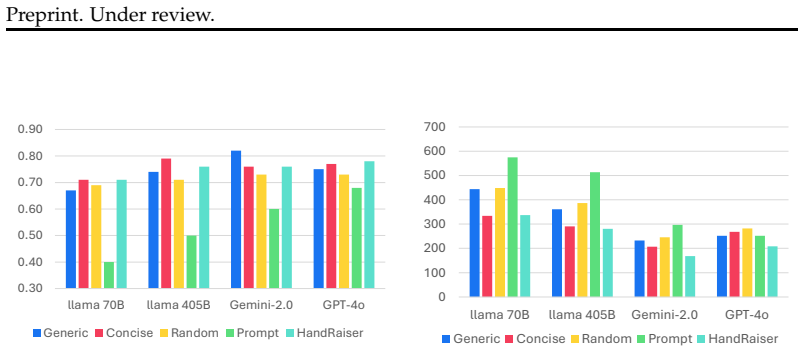

read the original abstract
Multi-agent systems using large language models (LLMs) have demonstrated impressive capabilities across various domains. However, current agent communication suffers from verbose output that overload context and increase computational costs. Although existing approaches focus on compressing the message from the speaker side, they struggle to adapt to different listeners and identify relevant information. An effective way in human communication is to allow the listener to interrupt and express their opinion or ask for clarification. Motivated by this, we propose an interruptible communication framework that allows the agent who is listening to interrupt the current speaker. Through prompting experiments, we find that current LLMs are often overconfident and interrupt before receiving enough information. Therefore, we propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost. We evaluate our framework across various multi-agent scenarios, including 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate. The results of the experiment show that our HANDRAISER can reduce the communication cost by 32.2% compared to the baseline with comparable or superior task performance. This learned interruption behavior can also be generalized to different agents and tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HANDRAISER, an interruptible communication framework for LLM-based multi-agent systems. It motivates the approach via human-like listener interruptions to reduce verbose outputs and context overload, identifies LLM overconfidence through prompting experiments, and proposes a learning method to predict interruption points based on estimated future reward and cost. The framework is evaluated on 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate, claiming a 32.2% communication cost reduction relative to baseline with comparable or superior task performance, along with generalization of the learned interruption behavior to different agents and tasks.
Significance. If the results hold, the work could meaningfully advance efficient multi-agent LLM systems by shifting from speaker-side compression to adaptive listener-initiated interruptions. The reward-cost estimation approach offers a principled, learning-based alternative to heuristic interruption rules and may scale better across scenarios than fixed prompting strategies.
major comments (2)
- [Experiments] Experiments section: The generalization claim (zero-shot transfer of the interruption policy across tasks with differing turn structures, information asymmetry, and reward sparsity) is load-bearing for the central result but rests on the unverified assumption that LLM-derived reward/cost estimates transfer without retraining. The manuscript should report explicit cross-task zero-shot results or clarify retraining details, as failure here would undermine both the 32.2% cost reduction and the generalization statement.
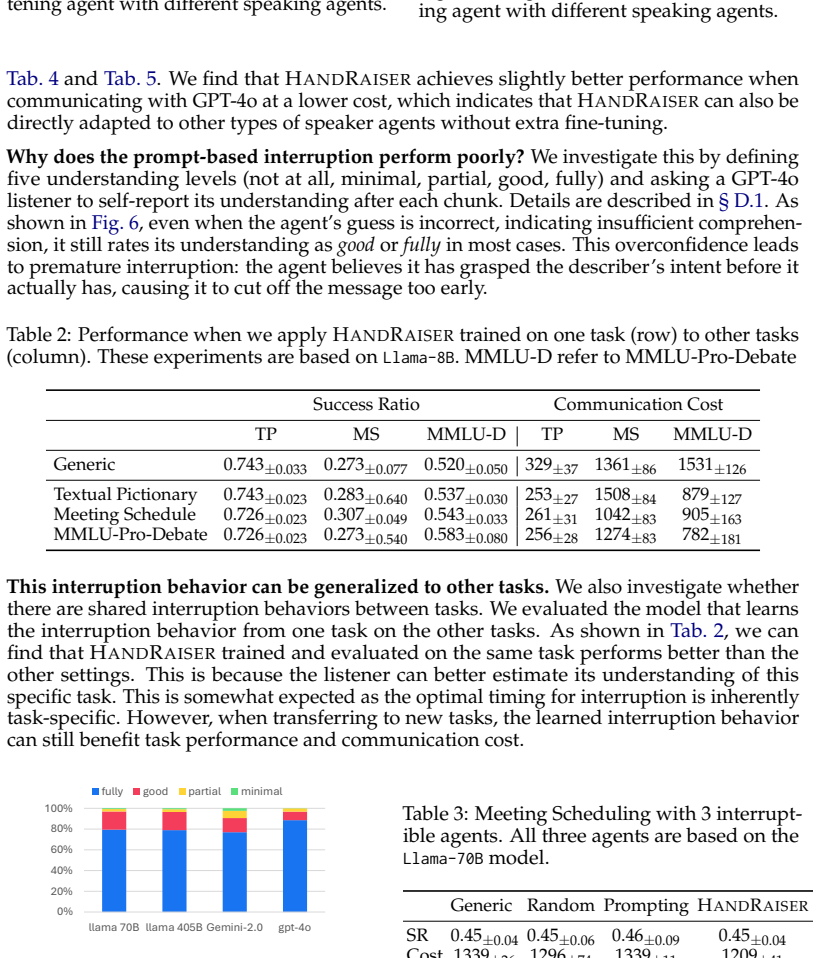
- [Method] Method section: The procedure for estimating future reward and cost (used as the learning objective for interruption prediction) lacks sufficient algorithmic or equation-level detail. Without this, it is impossible to determine whether the estimates avoid inheriting the overconfidence bias shown in the prompting experiments or whether the policy is robust to the task differences noted above.
minor comments (2)
- [Abstract] Abstract: The performance claim of 32.2% cost reduction is stated without reference to baselines, variance, number of runs, or statistical tests; these details should be summarized even in the abstract for immediate verifiability.
- [Experiments] The manuscript would benefit from a table comparing cost and task metrics across all three scenarios with explicit baseline definitions.
Simulated Author's Rebuttal
We appreciate the referee's thoughtful and constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the clarity and rigor of the presentation.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The generalization claim (zero-shot transfer of the interruption policy across tasks with differing turn structures, information asymmetry, and reward sparsity) is load-bearing for the central result but rests on the unverified assumption that LLM-derived reward/cost estimates transfer without retraining. The manuscript should report explicit cross-task zero-shot results or clarify retraining details, as failure here would undermine both the 32.2% cost reduction and the generalization statement.
Authors: We thank the referee for highlighting the importance of making the generalization evidence explicit. The manuscript reports results across multiple tasks (text pictionary, scheduling, and debate) and demonstrates that the learned interruption policy transfers to different agents and tasks. To directly address the concern, we will add a new subsection in the Experiments section with explicit zero-shot cross-task transfer results, including tables showing performance when the policy trained on one task is applied without retraining to others with differing turn structures, information asymmetry, and reward sparsity. This will confirm the transfer of the reward/cost estimates and support the reported cost reductions. revision: yes
-
Referee: [Method] Method section: The procedure for estimating future reward and cost (used as the learning objective for interruption prediction) lacks sufficient algorithmic or equation-level detail. Without this, it is impossible to determine whether the estimates avoid inheriting the overconfidence bias shown in the prompting experiments or whether the policy is robust to the task differences noted above.
Authors: We agree that the Method section requires more precise description of the estimation procedure. In the revised version, we will expand this section with algorithmic details, pseudocode, and equations detailing how future reward (derived from expected task success) and cost (derived from projected communication overhead) are estimated via LLM-based simulation of trajectories. We will clarify that these learned estimates serve as the training objective for the interruption predictor, distinguishing them from direct LLM prompting and thereby avoiding the overconfidence bias shown in our prompting experiments. We will also add discussion of robustness to the noted task differences. revision: yes
Circularity Check
No significant circularity; learning objective tied to external task outcomes
full rationale
The paper presents a learning method for predicting interruption points from estimated future reward and cost, evaluated empirically across distinct multi-agent scenarios (pictionary, scheduling, debate) with reported cost reductions. No equations, derivations, or self-citations appear in the provided text that would reduce the interruption policy or its predictions to the training inputs by construction. The reward/cost estimation is described as an objective linked to downstream task performance rather than a tautological fit or renaming. Generalization claims rest on experimental transfer, not on any self-definitional or uniqueness-imported structure. This is the expected non-circular outcome for an empirical learning paper without load-bearing analytic reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward and cost estimation parameters
axioms (1)
- domain assumption Current LLMs are overconfident and interrupt too early when prompted
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearwe propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost... HANDRAISER can reduce the communication cost by 32.2%
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEstimating with tree sampling... label the point with positive delta for both cost and performance
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
https://www.anthropic.com/engineering/multi-agent-research-system
Anthropic . https://www.anthropic.com/engineering/multi-agent-research-system. https://www.anthropic.com/engineering/multi-agent-research-system, 2025
2025
-
[3]
Interruptions and the interpretation of conversation
Adrian Bennett. Interruptions and the interpretation of conversation. In Annual Meeting of the Berkeley Linguistics Society, pp.\ 557--575, 1978
1978
-
[4]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi-agent llm systems fail? arXiv preprint arXiv:2503.13657, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Chateval: Towards better LLM -based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better LLM -based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=FQepisCUWu
2024
-
[6]
Autoagents: A framework for automatic agent generation
Guangyao Chen, Siwei Dong, Yu Shu, Ge Zhang, Jaward Sesay, Börje Karlsson, Jie Fu, and Yemin Shi. Autoagents: A framework for automatic agent generation. In IJCAI, pp.\ 22--30, 2024. URL https://www.ijcai.org/proceedings/2024/3
2024
-
[7]
Steffi Chern, Ethan Chern, Graham Neubig, and Pengfei Liu. Can large language models be trusted for evaluation? scalable meta-evaluation of llms as evaluators via agent debate. arXiv preprint arXiv:2401.16788, 2024
-
[8]
Mechanism design for multi-agent meeting scheduling
Elisabeth Crawford and Manuela Veloso. Mechanism design for multi-agent meeting scheduling. Web Intelligence and Agent Systems, 4 0 (2): 0 209--220, 2006
2006
-
[9]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Alpacafarm: A simulation framework for methods that learn from human feedback
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems, 36: 0 30039--30069, 2023
2023
-
[11]
Thinkless: Llm learns when to think.arXiv preprint arXiv:2505.13379,
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Thinkless: Llm learns when to think. arXiv preprint arXiv:2505.13379, 2025
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Large language model based multi-agents: A survey of progress and challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. In IJCAI, 2024
2024
-
[14]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=Itxz7S4Ip3
2025
-
[15]
Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead
Junda He, Christoph Treude, and David Lo. Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead. ACM Transactions on Software Engineering and Methodology, 34 0 (5): 0 1--30, 2025
2025
-
[16]
Self-evolving multi-agent collaboration networks for software development
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4R71pdPBZp
2025
-
[17]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
C3ot: Generating shorter chain-of-thought without compromising effectiveness
Yu Kang, Xianghui Sun, Liangyu Chen, and Wei Zou. C3ot: Generating shorter chain-of-thought without compromising effectiveness. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 24312--24320, 2025
2025
-
[19]
Debating with more persuasive llms leads to more truthful answers
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R Bowman, Tim Rockt \"a schel, and Ethan Perez. Debating with more persuasive llms leads to more truthful answers. Proceedings of Machine Learning Research, 235: 0 23662--23733, 2024
2024
-
[20]
Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis
Chaejeong Lee, Jayoung Kim, and Noseong Park. Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis. In International Conference on Machine Learning, pp.\ 18940--18956. PMLR, 2023
2023
-
[21]
Improving Multi-Agent Debate with Sparse Communication Topology , booktitle =
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi-agent debate with sparse communication topology. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 7281--7294, Miami, Florida, USA, November 2024. Association for Co...
-
[22]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. Encouraging divergent thinking in large language models through multi-agent debate. arXiv preprint arXiv:2305.19118, 2023
work page internal anchor Pith review arXiv 2023
-
[23]
Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization. In COLM, 2024
2024
-
[24]
Conversation, politeness, and interruption
William G Lycan. Conversation, politeness, and interruption. Paper in Linguistics, 10 0 (1-2): 0 23--53, 1977
1977
-
[25]
Interruption and influence in discussion groups
Sik Hung Ng, Mark Brooke, and Michael Dunne. Interruption and influence in discussion groups. Journal of Language and Social Psychology, 14 0 (4): 0 369--381, 1995
1995
-
[26]
Openclaw
OpenClaw . Openclaw. https://github.com/openclaw/openclaw, 2026
2026
-
[27]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pp.\ 1--22, 2023
2023
-
[28]
Scaling large language model-based multi-agent collaboration
Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model-based multi-agent collaboration. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=K3n5jPkrU6
2025
-
[29]
Concise: Confidence-guided compression in step-by-step efficient reasoning
Ziqing Qiao, Yongheng Deng, Jiali Zeng, Dong Wang, Lai Wei, Fandong Meng, Jie Zhou, Ju Ren, and Yaoxue Zhang. Concise: Confidence-guided compression in step-by-step efficient reasoning. arXiv preprint arXiv:2505.04881, 2025
-
[30]
Multi-agent meeting scheduling: A negotiation perspective
Bram M Renting, Holger Hoos, and Catholijn M Jonker. Multi-agent meeting scheduling: A negotiation perspective. In The Sixteenth Workshop on Adaptive and Learning Agents, 2024
2024
-
[31]
Coding theorems for a discrete source with a fidelity criterion
Claude E Shannon et al. Coding theorems for a discrete source with a fidelity criterion. IRE Nat. Conv. Rec, 4 0 (142-163): 0 1, 1959
1959
-
[32]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O'Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms. arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Beyond turn-based interfaces: Synchronous llms as full-duplex dialogue agents
Bandhav Veluri, Benjamin N Peloquin, Bokai Yu, Hongyu Gong, and Shyamnath Gollakota. Beyond turn-based interfaces: Synchronous llms as full-duplex dialogue agents. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 21390--21402, 2024
2024
-
[36]
Avalon’s game of thoughts: Battle against deception through recursive contemplation
Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Avalon's game of thoughts: Battle against deception through recursive contemplation. ArXiv, abs/2310.01320, 2023. URL https://api.semanticscholar.org/CorpusID:263605971
-
[37]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37: 0 95266--95290, 2024
2024
-
[38]
Zhexuan Wang, Yutong Wang, Xuebo Liu, Liang Ding, Miao Zhang, Jie Liu, and Min Zhang. A gent D ropout: Dynamic agent elimination for token-efficient and high-performance LLM -based multi-agent collaboration. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for ...
-
[39]
Tokenskip: Controllable chain-of-thought compression in llms
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. Tokenskip: Controllable chain-of-thought compression in llms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 3351--3363, 2025
2025
-
[40]
Ex- ploring large language models for communica- tion games: An empirical study on werewolf
Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, and Yang Liu. Exploring large language models for communication games: An empirical study on werewolf. arXiv preprint arXiv:2309.04658, 2023
-
[41]
Bingyu Yan, Zhibo Zhou, Litian Zhang, Lian Zhang, Ziyi Zhou, Dezhuang Miao, Zhoujun Li, Chaozhuo Li, and Xiaoming Zhang. Beyond self-talk: A communication-centric survey of llm-based multi-agent systems. arXiv preprint arXiv:2502.14321, 2025
-
[42]
Exchange-of-thought: Enhancing large language model capabilities through cross-model communication
Zhangyue Yin, Qiushi Sun, Cheng Chang, Qipeng Guo, Junqi Dai, Xuan-Jing Huang, and Xipeng Qiu. Exchange-of-thought: Enhancing large language model capabilities through cross-model communication. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 15135--15153, 2023
2023
-
[43]
Cut the crap: An economical communication pipeline for LLM -based multi-agent systems
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for LLM -based multi-agent systems. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=LkzuPorQ5L
2025
-
[44]
Beyond the turn-based game: Enabling real-time conversations with duplex models
Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, and Zhiyuan Liu. Beyond the turn-based game: Enabling real-time conversations with duplex models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 11543--11557, 2024 a
2024
-
[45]
Chain of agents: Large language models collaborating on long-context tasks
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan \"O Ar k. Chain of agents: Large language models collaborating on long-context tasks. Advances in Neural Information Processing Systems, 37: 0 132208--132237, 2024 b
2024
-
[46]
arXiv preprint arXiv:2406.04520 , year=
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V Le, Ed H Chi, et al. Natural plan: Benchmarking llms on natural language planning. arXiv preprint arXiv:2406.04520, 2024
-
[47]
arXiv preprint arXiv:2502.02533 , year=
Han Zhou, Xingchen Wan, Ruoxi Sun, Hamid Palangi, Shariq Iqbal, Ivan Vuli \'c , Anna Korhonen, and Sercan \"O Ar k. Multi-agent design: Optimizing agents with better prompts and topologies. arXiv preprint arXiv:2502.02533, 2025
-
[48]
Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and J \"u rgen Schmidhuber. Language agents as optimizable graphs. arXiv preprint arXiv:2402.16823, 2024
-
[49]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[50]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[51]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.