Recognition: no theorem link
Context-Aware Dialectal Arabic Machine Translation with Interactive Region and Register Selection
Pith reviewed 2026-05-10 18:58 UTC · model grok-4.3
The pith
A rule-based data augmentation pipeline enables machine translation models to target specific Arabic dialects and registers rather than defaulting to standard Arabic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
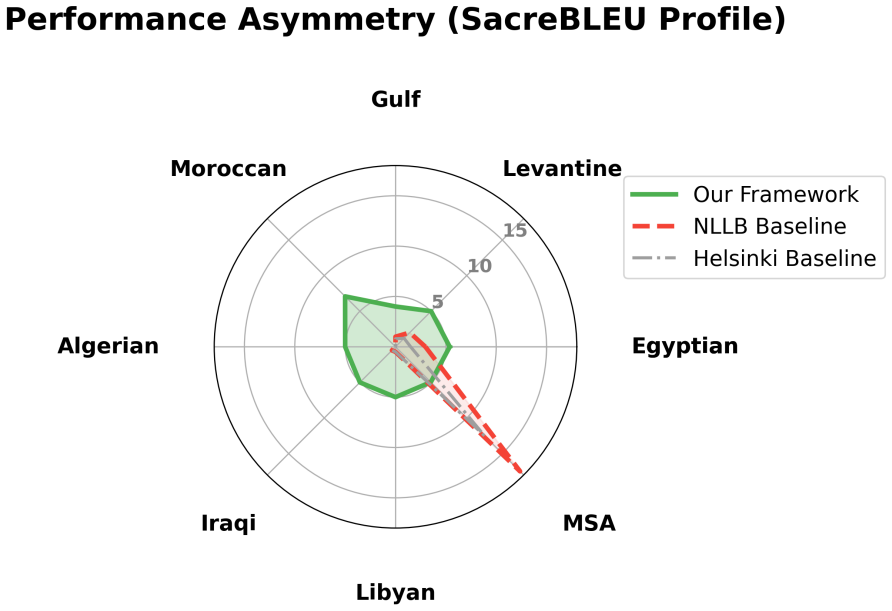
Our model achieves lower BLEU scores (8.19) than high-resource baselines such as NLLB (13.75) yet produces outputs that align more closely with the intended regional varieties, as measured by LLM-assisted cultural authenticity analysis (4.80/5 versus 1.0/5).
What carries the argument
The Rule-Based Data Augmentation (RBDA) pipeline, which expands a 3,000-sentence seed corpus into a balanced 57,000-sentence parallel dataset covering eight regional varieties and multiple sociolinguistic registers, then conditions an mT5-base model on lightweight metadata tags for controllable generation.
If this is right
- Standard MT systems tend to homogenize dialectal inputs into Modern Standard Arabic even when the source is clearly non-standard.
- Lightweight metadata tags can steer generation across dialects and registers without requiring architectural changes to the base model.
- Aggregate BLEU scores are a poor indicator of success on dialect-sensitive tasks because they favor the majority MSA mean.
- Qualitative and LLM-assisted cultural authenticity checks can reveal fidelity improvements invisible to automatic metrics.
Where Pith is reading between the lines
- The same augmentation-plus-tagging pattern could be tested on other high-variation language pairs where parallel data is scarce.
- Interactive region and register selection interfaces built on this model might reduce post-editing effort for users who need specific vernaculars.
- If the rule-based augmentation introduces subtle artifacts, they would most likely appear in low-frequency syntactic constructions rather than in lexical choice.
Load-bearing premise
The rule-based data augmentation accurately generates authentic dialectal and register variation without introducing systematic artifacts or biases that the qualitative evaluation fails to detect.
What would settle it
A blind side-by-side rating by native speakers of each target dialect measuring how often the augmented model's output is preferred over baseline output for naturalness and regional authenticity on held-out sentences.
Figures




read the original abstract
Current Machine Translation (MT) systems for Arabic often struggle to account for dialectal diversity, frequently homogenizing dialectal inputs into Modern Standard Arabic (MSA) and offering limited user control over the target vernacular. In this work, we propose a context-aware and steerable framework for dialectal Arabic MT that explicitly models regional and sociolinguistic variation. Our primary technical contribution is a Rule-Based Data Augmentation (RBDA) pipeline that expands a 3,000-sentence seed corpus into a balanced 57,000-sentence parallel dataset, covering eight regional varieties eg., Egyptian, Levantine, Gulf, etc. By fine-tuning an mT5-base model conditioned on lightweight metadata tags, our approach enables controllable generation across dialects and social registers in the translation output. Through a combination of automatic evaluation and qualitative analysis, we observe an apparent accuracy-fidelity trade-off: high-resource baselines such as NLLB (No Language Left Behind) achieve higher aggregate BLEU scores (13.75) by defaulting toward the MSA mean, while exhibiting limited dialectal specificity. In contrast, our model achieves lower BLEU scores (8.19) but produces outputs that align more closely with the intended regional varieties. Supporting qualitative evaluation, including an LLM-assisted cultural authenticity analysis, suggests improved dialectal alignment compared to baseline systems (4.80/5 vs. 1.0/5). These findings highlight the limitations of standard MT metrics for dialect-sensitive tasks and motivate the need for evaluation practices that better reflect linguistic diversity in Arabic MT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Rule-Based Data Augmentation (RBDA) pipeline that expands a 3,000-sentence seed corpus into a balanced 57,000-sentence parallel dataset covering eight Arabic regional varieties. It fine-tunes an mT5-base model conditioned on lightweight metadata tags for region and register to enable controllable, context-aware dialectal machine translation. The authors report an accuracy-fidelity trade-off: their model achieves lower aggregate BLEU (8.19) than high-resource baselines such as NLLB (13.75) but higher dialectal alignment according to LLM-assisted cultural authenticity analysis (4.80/5 versus 1.0/5), arguing that standard MT metrics are inadequate for dialect-sensitive tasks.
Significance. If the RBDA outputs prove to be linguistically authentic, the work supplies a practical steerable framework for Arabic dialect MT and usefully illustrates the limitations of BLEU when target varieties diverge from MSA. The concrete BLEU numbers and the metadata-conditioning approach constitute clear empirical contributions.
major comments (3)
- [§3] §3 (Rule-Based Data Augmentation pipeline): The claim that the 3k-to-57k expansion produces 'balanced, authentic' data across eight varieties rests on unvalidated rule transformations; no section compares the generated sentences to gold dialectal references, measures lexical/morphological fidelity against external corpora, or reports linguist validation of the augmented data itself. This is load-bearing for the central fidelity claim because the 4.80/5 score may simply reward consistency with the same rules rather than genuine regional authenticity.
- [Evaluation section] Evaluation section (qualitative analysis): The LLM-assisted cultural authenticity score of 4.80/5 versus 1.0/5 is reported without specifying the LLM model, prompt template, scoring rubric, or any human inter-annotator agreement; this makes it impossible to determine whether the metric captures real dialectal alignment or artifacts introduced by the augmentation rules.
- [Results section] Results section (BLEU comparison): The reported BLEU scores (8.19 vs. 13.75) are given as single point estimates without statistical significance testing, variance across runs, or analysis of confounding factors such as domain mismatch or register effects, weakening the asserted accuracy-fidelity trade-off.
minor comments (2)
- [Abstract] Abstract: 'eg.,' should be formatted as 'e.g.,'.
- [§4] The manuscript would benefit from an explicit statement of how the interactive region/register selection is realized at inference time (e.g., via prompt tokens or control codes).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We appreciate the recognition of the RBDA pipeline and metadata-conditioning as empirical contributions, as well as the highlighting of BLEU's limitations for dialectal tasks. We address each major comment below, with planned revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Rule-Based Data Augmentation pipeline): The claim that the 3k-to-57k expansion produces 'balanced, authentic' data across eight varieties rests on unvalidated rule transformations; no section compares the generated sentences to gold dialectal references, measures lexical/morphological fidelity against external corpora, or reports linguist validation of the augmented data itself. This is load-bearing for the central fidelity claim because the 4.80/5 score may simply reward consistency with the same rules rather than genuine regional authenticity.
Authors: We agree that the current manuscript insufficiently validates the authenticity of the RBDA outputs, which is central to our fidelity claims. The rules were derived from established linguistic resources on Arabic dialect variation, but no direct comparisons or expert validation were reported. In the revised version, we will expand §3 with: (i) quantitative lexical and morphological fidelity metrics comparing augmented sentences to external gold dialectal corpora (e.g., MADAR and dialect-specific collections); (ii) linguist validation on a stratified sample of 200 sentences (25 per variety), including native-speaker ratings and inter-annotator agreement. These additions will directly test whether outputs reflect genuine regional authenticity beyond rule consistency. revision: yes
-
Referee: [Evaluation section] Evaluation section (qualitative analysis): The LLM-assisted cultural authenticity score of 4.80/5 versus 1.0/5 is reported without specifying the LLM model, prompt template, scoring rubric, or any human inter-annotator agreement; this makes it impossible to determine whether the metric captures real dialectal alignment or artifacts introduced by the augmentation rules.
Authors: We acknowledge that critical implementation details for the LLM-assisted evaluation were omitted, limiting reproducibility and interpretability. In the revised Evaluation section, we will explicitly state the LLM (GPT-4), include the full prompt template in an appendix, detail the 1-5 scoring rubric (focusing on lexical choice, morphology, and cultural idiomaticity), and report any available agreement metrics. Additionally, we will conduct and report a small-scale human validation study with dialect speakers to cross-check the LLM scores and address potential rule artifacts. revision: yes
-
Referee: [Results section] Results section (BLEU comparison): The reported BLEU scores (8.19 vs. 13.75) are given as single point estimates without statistical significance testing, variance across runs, or analysis of confounding factors such as domain mismatch or register effects, weakening the asserted accuracy-fidelity trade-off.
Authors: The BLEU figures were single-run point estimates from our primary setup, which does limit the strength of the comparison. We will revise the Results section to include: multiple random seeds (reporting mean ± std. dev. across 3 runs), statistical significance testing via paired bootstrap resampling, and an explicit analysis of potential confounders (domain and register effects) with breakdowns by variety. These changes will provide a more robust basis for the accuracy-fidelity trade-off without altering the core observation that baselines favor MSA while our model better matches intended dialects. revision: yes
Circularity Check
No significant circularity; results rest on external baselines and standard metrics
full rationale
The paper describes a rule-based data augmentation pipeline that expands a seed corpus, followed by metadata-conditioned fine-tuning of mT5 and evaluation via BLEU against external systems (e.g., NLLB) plus LLM-assisted qualitative scoring. No equations, self-definitional constructs, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The claimed dialectal fidelity improvement is measured against independent baselines rather than quantities defined internally by the augmentation rules themselves. The central chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption mT5-base can be effectively fine-tuned for controllable generation using lightweight metadata tags
- ad hoc to paper Rule-based transformations applied to a 3,000-sentence seed produce balanced, authentic parallel data across eight regional varieties
Reference graph
Works this paper leans on
-
[1]
URLhttps://aclanthology.org/2024.eacl-long.30
doi: 10.18653/v1/2024.eacl-long.30. URLhttps://aclanthology.org/2024.eacl-long.30. Muhammad Abdul-Mageed, Amr Keleg, et al. NADI 2024: The fifth nuanced Arabic dialect identification shared task. InProceedings of the Second Arabic Natural Language Processing Conference, pages 709–728,
-
[2]
URL https://aclanthology.org/ 2024.arabicnlp-1.79
doi: 10.18653/v1/2024.arabicnlp-1.79. URL https://aclanthology.org/ 2024.arabicnlp-1.79. Kathrein Abu Kwaik, Motaz Saad, et al. Shami: A corpus of Levantine Arabic dialects. InProceedings of the Eleventh International Conference on Language Resources and Evaluation,
-
[4]
URL https://arxiv. org/abs/2507.22603. Laila Abdullah Al Suwaiyan. Diglossia in the arabic language.International Journal of Language and Linguistics, 5(3):228–238,
-
[5]
doi: 10.30845/ijll.v5n3p22. URL https://doi.org/10. 30845/ijll.v5n3p22. Abdullah Alabdullah, Lifeng Han, and Chenghua Lin. Advancing dialectal arabic to modern standard arabic machine translation.arXiv preprint arXiv:2507.20301,
-
[6]
Yazeed Alnumay, Alexandre Barbet, Anna Bialas, et al
URL https://arxiv.org/ abs/2507.20301. Yazeed Alnumay, Alexandre Barbet, Anna Bialas, et al. Command r7b arabic: A small, enterprise focused, multilingual, and culturally aware arabic llm.arXiv preprint arXiv:2503.14603,
-
[7]
Arwa Alsindy.Language Variation: Arabic Dialects in Madinah, Saudi Arabia
URL https://arxiv.org/abs/2503.14603. Arwa Alsindy.Language Variation: Arabic Dialects in Madinah, Saudi Arabia. PhD thesis, The University of Mississippi,
- [8]
-
[9]
Unifiedqa: Crossing format boundaries with a single QA system.CoRR, abs/2005.00700, 2020a
doi: 10.18653/v1/2020. autosimultrans-1.4. URLhttps://aclanthology.org/2020.autosimultrans-1.4. Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, et al. No language left behind: Scaling human-centered machine translation.arXiv preprint arXiv:2207.04672,
-
[10]
No Language Left Behind: Scaling Human-Centered Machine Translation
URL https:// arxiv.org/abs/2207.04672. William M. Cotter and Rudolf de Jong. Regional variation. InThe Routledge Handbook of Arabic Sociolinguistics, chapter
work page internal anchor Pith review arXiv
-
[11]
doi: 10.4324/9781315722450-4. URL https://doi. org/10.4324/9781315722450-4. Discover Discomfort. Arabic dialects compared,
-
[13]
arXiv preprint arXiv:2501.13944
URL https://arxiv.org/abs/ 2501.13944. Strommen Inc. Arabic dialects explained: A complete guide for language learners,
-
[15]
Fajri Koto, Haonan Li, Sara Shatnawi, et al
URLhttps://arxiv.org/abs/2310.13747. Fajri Koto, Haonan Li, Sara Shatnawi, et al. ArabicMMLU: Assessing massive multitask language understanding in Arabic. InFindings of the Association for Computational Linguistics: ACL 2024, pages 5622–5640,
-
[16]
doi: 10.18653/v1/2024.findings-acl.334. URL https://aclanthology. org/2024.findings-acl.334. 13 Sangmin-Michelle Lee. A systematic review of context-aware technology use in foreign language learning. Computer Assisted Language Learning, 35(3):294–318,
-
[17]
URLhttps://doi.org/10.1080/09588221.2019.1688836
doi: 10.1080/09588221.2019.1688836. URLhttps://doi.org/10.1080/09588221.2019.1688836. Shafqat Maqsood, Abdul Shahid, Fatima Nazar, Muhammad Asif, Muhammad Ahmad, Manuel Mazzara, and Salvatore Distefano. C-POS: A context-aware adaptive part-of-speech language learning framework. IEEE Access, 8:58320–58334,
-
[18]
doi: 10.1109/ACCESS.2020.2982425. URL https://doi. org/10.1109/ACCESS.2020.2982425. Nina Markl. Language variation and algorithmic bias: understanding algorithmic bias in british english automatic speech recognition. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 521–534,
-
[19]
doi: 10.1145/3531146.3533117. URL https://doi. org/10.1145/3531146.3533117. Sameen Maruf, Fahimeh Saleh, and Gholamreza Haffari. A survey on document-level neural machine translation: Methods and evaluation.ACM Computing Surveys, 54(2):1–36,
-
[20]
URLhttps://doi.org/10.1145/3412844
doi: 10.1145/ 3412844. URLhttps://doi.org/10.1145/3412844. Omar Nassra. Arabic dialects: Different types of arabic language,
-
[21]
org/2022.lrec-1.683
URL https://aclanthology. org/2022.lrec-1.683. Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Abheek Barua, and Colin Raffel. mT5: A massively multilingual pre-trained text-to-text transformer. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human La...
2022
-
[22]
doi: 10.18653/v1/2021.naacl-main.41. URL https://aclanthology.org/2021.naacl-main.41. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.