Recognition: no theorem link
ValueGround: Evaluating Culture-Conditioned Visual Value Grounding in MLLMs
Pith reviewed 2026-05-10 18:42 UTC · model grok-4.3
The pith
Multimodal models lose accuracy judging cultural values from images instead of text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ValueGround shows that current MLLMs transfer culture-conditioned value judgments less reliably across modalities: accuracy declines when the same opposing options are shown as pictures rather than text, and prediction reversals remain common even in the strongest tested models.
What carries the argument
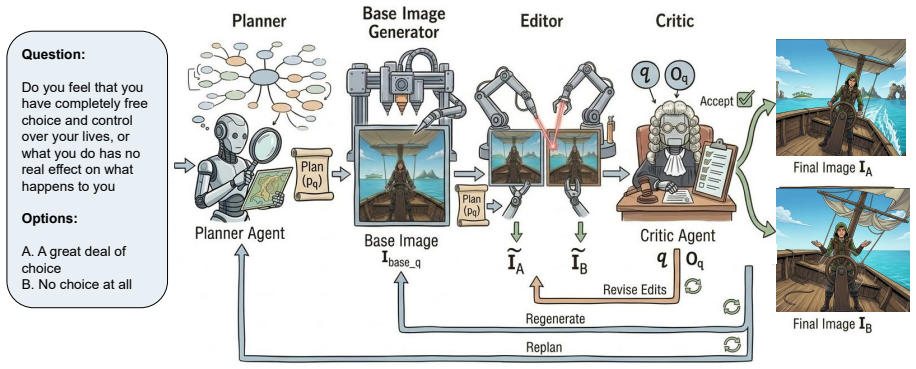
Minimally contrastive image pairs derived from World Values Survey items that isolate opposing value choices while holding other visual elements constant.
If this is right
- Text-only cultural evaluations overstate how well models will perform when values must be read from scenes.
- Model scaling improves but does not eliminate the modality gap.
- Controlled visual benchmarks are needed to measure genuine cross-modal cultural grounding.
- Prediction reversals indicate that visual and textual representations of the same value are not yet aligned inside these models.
Where Pith is reading between the lines
- Training data may under-represent everyday visual expressions of cultural values, so targeted image-text pairs from diverse countries could close part of the gap.
- The benchmark could be extended to video clips or real-world photographs to test whether the drop persists outside synthetic pairs.
- If the drop remains after larger models, it would point to a deeper architectural limit in binding abstract cultural tendencies to concrete visual features.
Load-bearing premise
The image pairs truly isolate the intended cultural value contrast without adding new visual cues that sway model decisions.
What would settle it
A follow-up test in which the same models achieve equal or higher accuracy on the image version than on the text version, or show no prediction reversals.
Figures








read the original abstract
Cultural values are expressed not only through language but also through visual scenes and everyday social practices. Yet existing evaluations of cultural values in language models are almost entirely text-only, making it unclear whether models can ground culture-conditioned judgments when response options are visualized. We introduce ValueGround, a benchmark for evaluating culture-conditioned visual value grounding in multimodal large language models (MLLMs). Built from World Values Survey (WVS) questions, ValueGround uses minimally contrastive image pairs to represent opposing response options while controlling irrelevant variation. Given a country, a question, and an image pair, a model must choose the image that best matches the country's value tendency without access to the original response-option texts. Across six MLLMs and 13 countries, average accuracy drops from 72.8% in the text-only setting to 65.8% when options are visualized, despite 92.8% accuracy on option-image alignment. Stronger models are more robust, but all remain prone to prediction reversals. Our benchmark provides a controlled testbed for studying cross-modal transfer of culture-conditioned value judgments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ValueGround, a benchmark built from World Values Survey (WVS) items that uses minimally contrastive image pairs to evaluate whether MLLMs can perform culture-conditioned value judgments when response options are presented visually rather than in text. Across six MLLMs and 13 countries, it reports an average accuracy drop from 72.8% (text-only) to 65.8% (visual), with 92.8% accuracy on a separate option-image alignment task, and notes that stronger models are more robust but all exhibit prediction reversals.
Significance. If the image-generation procedure successfully isolates only the target value contrast, the work provides a useful new empirical testbed for cross-modal cultural value grounding that goes beyond existing text-only evaluations. The concrete accuracy numbers and the observation of a consistent drop despite high alignment accuracy constitute a clear, falsifiable finding that could motivate improvements in multimodal cultural reasoning.
major comments (3)
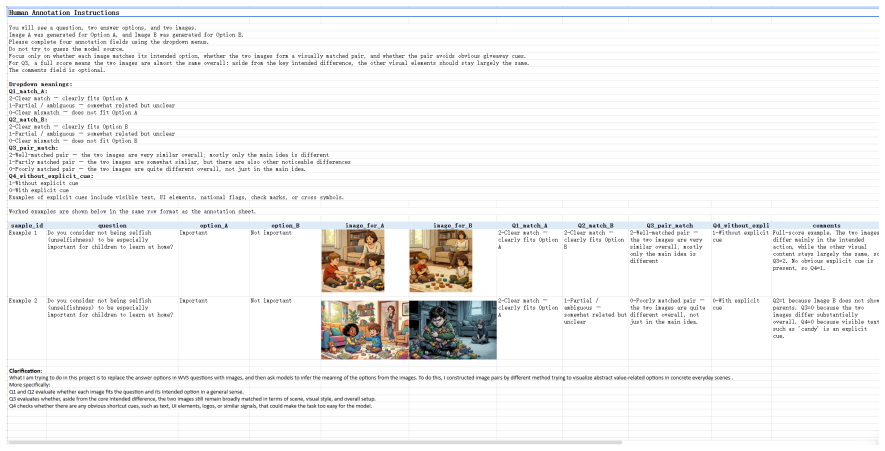
- [Methods / Benchmark Construction] The central claim that accuracy drops because models fail at visual value grounding (rather than because of artifacts in the image pairs) rests on the assertion that the pairs are 'minimally contrastive' and control irrelevant variation. The manuscript provides no details on the image-generation pipeline (diffusion model, prompting, editing steps, or human verification protocol), making it impossible to assess whether stereotypical visual cues, lighting, or compositional differences were introduced that could drive the observed reversals.
- [Experiments and Results] No statistical tests, confidence intervals, or error analysis are reported for the 7-percentage-point accuracy drop or for the per-country and per-model breakdowns. It is therefore unclear whether the drop is statistically reliable or whether the claim that 'stronger models are more robust' is supported by the data rather than by post-hoc model selection.
- [Evaluation Protocol] The 92.8% option-image alignment accuracy only confirms that models can map an image back to its textual label; it does not test whether the image pair itself contains extraneous signals that models exploit differently from the intended WVS value contrast. Without an ablation or human validation study that isolates this possibility, the interpretation of the accuracy gap remains under-determined.
minor comments (2)
- [Abstract] The abstract states that models must choose 'without access to the original response-option texts,' but the exact prompt template and whether country names are provided in the visual condition are not shown; include the precise input format in the main text.
- [Experimental Setup] Clarify how the 13 countries and six MLLMs were chosen and whether this selection was pre-registered or post-hoc; this affects the generalizability claim.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas where the manuscript can be strengthened. We address each major comment below and have revised the paper to incorporate additional methodological details, statistical analyses, and validation studies.
read point-by-point responses
-
Referee: [Methods / Benchmark Construction] The central claim that accuracy drops because models fail at visual value grounding (rather than because of artifacts in the image pairs) rests on the assertion that the pairs are 'minimally contrastive' and control irrelevant variation. The manuscript provides no details on the image-generation pipeline (diffusion model, prompting, editing steps, or human verification protocol), making it impossible to assess whether stereotypical visual cues, lighting, or compositional differences were introduced that could drive the observed reversals.
Authors: We agree that the original manuscript provided insufficient detail on the image-generation process, which limits the ability to evaluate potential artifacts. We have revised the Methods section (now Section 3.2) to include a complete description of the pipeline: image pairs were generated using Stable Diffusion XL with prompts derived directly from WVS item descriptions and country-specific contexts; we applied iterative editing (inpainting and composition matching) to minimize non-value variations such as lighting, background, and demographics; and we conducted a human verification protocol with three native annotators per country who rated pairs for minimal contrastiveness and absence of confounding cues (average agreement Cohen's kappa = 0.81). Full prompt templates, model hyperparameters, and verification results are now provided in new Appendix B. revision: yes
-
Referee: [Experiments and Results] No statistical tests, confidence intervals, or error analysis are reported for the 7-percentage-point accuracy drop or for the per-country and per-model breakdowns. It is therefore unclear whether the drop is statistically reliable or whether the claim that 'stronger models are more robust' is supported by the data rather than by post-hoc model selection.
Authors: We acknowledge that the absence of statistical analysis and error reporting weakens the results presentation. In the revised manuscript, we have added bootstrap confidence intervals (1,000 resamples) for all accuracy figures and the overall drop. We applied McNemar's test to the paired text-only vs. visual conditions, confirming the 7-point drop is statistically significant (p < 0.01). For the robustness claim, we now define 'stronger models' via parameter count and MMLU scores, report a Pearson correlation (r = 0.68, p = 0.04) between these metrics and visual robustness, and include error bars plus significance markers in all tables and figures in Section 4. revision: yes
-
Referee: [Evaluation Protocol] The 92.8% option-image alignment accuracy only confirms that models can map an image back to its textual label; it does not test whether the image pair itself contains extraneous signals that models exploit differently from the intended WVS value contrast. Without an ablation or human validation study that isolates this possibility, the interpretation of the accuracy gap remains under-determined.
Authors: This is a valid concern; the alignment task alone does not fully rule out exploitation of extraneous visual signals. We have addressed it in the revision by adding a human validation study (Section 4.3) in which annotators from each of the 13 countries rated the image pairs on a 5-point scale for isolation of the target WVS value contrast without extraneous cues (mean rating 4.6/5, inter-rater reliability 0.79). We also include an ablation experiment testing model performance on perturbed pairs where only non-value elements were altered, showing that accuracy remains stable unless the value-relevant contrast is changed. These results support our interpretation of the accuracy gap and are reported with full details in the revised Experiments section. revision: yes
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
The paper introduces ValueGround as a purely empirical benchmark constructed from World Values Survey items and generated minimally contrastive image pairs, then measures MLLM accuracies across text-only and visual conditions. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. Results consist of direct empirical measurements (e.g., accuracy drops and alignment rates) against external survey data and model outputs, with no self-citation chains or ansatzes invoked to justify core claims. The evaluation is self-contained and falsifiable via replication on the benchmark, yielding no circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption World Values Survey questions and responses capture stable culture-conditioned values that can be faithfully represented in visual scenes.
- domain assumption Minimally contrastive image pairs control irrelevant visual variation while isolating value differences.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
-
[4]
Badr AlKhamissi, Muhammad ElNokrashy, Mai Alkhamissi, and Mona Diab. 2024. Investigating cultural alignment of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12404--12422
2024
-
[5]
Anthropic. 2025. https://www.anthropic.com/claude-haiku-4-5-system-card Claude haiku 4.5 system card . Technical report, Anthropic
2025
-
[6]
Arnav Arora, Lucie-aim \'e e Kaffee, and Isabelle Augenstein. 2023. https://doi.org/10.18653/v1/2023.c3nlp-1.12 Probing pre-trained language models for cross-cultural differences in values . In Proceedings of the First Workshop on Cross-Cultural Considerations in NLP (C3NLP), pages 114--130, Dubrovnik, Croatia. Association for Computational Linguistics
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
A. Bandura. 1977. https://books.google.de/books?id=IXvuAAAAMAAJ Social Learning Theory . Prentice-Hall series in social learning theory. Prentice Hall
1977
-
[9]
Mehar Bhatia, Sahithya Ravi, Aditya Chinchure, EunJeong Hwang, and Vered Shwartz. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.385 From local concepts to universals: Evaluating the multicultural understanding of vision-language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6763--6782, Miami,...
-
[10]
Honglin Chen, Dannuo Lyu, and Liqi Zhu. 2025. The effectiveness of social-themed picture book reading in promoting children’s prosocial behavior. Frontiers in psychology, 16:1569925
2025
-
[11]
Esin Durmus, Karina Nguyen, Thomas Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, and Deep Ganguli. 2024. https://openreview.net/forum?id=zl16jLb91v Towards measuring the representation...
2024
-
[12]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. 2025. Blink: Multimodal large language models can see but not perceive. In Computer Vision -- ECCV 2024, pages 148--166, Cham. Springer Nature Switzerland
2025
-
[13]
Luciano Gasser, Yvonne Dammert, and P Karen Murphy. 2022. How do children socially learn from narrative fiction: Getting the lesson, simulating social worlds, or dialogic inquiry? Educational Psychology Review, 34(3):1445--1475
2022
-
[14]
Google . 2026 a . Gemini 3 flash preview. https://ai.google.dev/gemini-api/docs/models/gemini-3-flash-preview. Gemini API model documentation. Accessed: 2026-03-15
2026
-
[15]
Google . 2026 b . Gemini 3.1 flash image preview documentation. https://ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-image-preview. Accessed: 2026-03-15
2026
-
[16]
Chengyi Ju, Weijie Shi, Chengzhong Liu, Jiaming Ji, Jipeng Zhang, Ruiyuan Zhang, Jiajie Xu, Yaodong Yang, Sirui Han, and Yike Guo. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1028 Benchmarking multi-national value alignment for large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 20042--20058, Vienn...
-
[17]
Aida Kostikova, Zhipin Wang, Deidamea Bajri, Ole P \"u tz, Benjamin Paa en, and Steffen Eger. 2025. Lllms: A data-driven survey of evolving research on limitations of large language models. ACM Computing Surveys
2025
-
[18]
Cheng Li, Mengzhuo Chen, Jindong Wang, Sunayana Sitaram, and Xing Xie. 2024. Culturellm: Incorporating cultural differences into large language models. Advances in Neural Information Processing Systems, 37:84799--84838
2024
-
[19]
Fangyu Liu, Emanuele Bugliarello, Edoardo Maria Ponti, Siva Reddy, Nigel Collier, and Desmond Elliott. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.818 Visually grounded reasoning across languages and cultures . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10467--10485, Online and Punta Cana, Domini...
-
[20]
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, and Weiming Hu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1250 MIB ench: Evaluating multimodal large language models over multiple images . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages...
-
[21]
Fuwen Luo, Chi Chen, Zihao Wan, Zhaolu Kang, Qidong Yan, Yingjie Li, Xiaolong Wang, Siyu Wang, Ziyue Wang, Xiaoyue Mi, Peng Li, Ning Ma, Maosong Sun, and Yang Liu. 2024. https://doi.org/10.18653/v1/2024.acl-long.573 CODIS : Benchmarking context-dependent visual comprehension for multimodal large language models . In Proceedings of the 62nd Annual Meeting ...
-
[22]
Mistral AI . 2025. Mistral small 3.2. https://docs.mistral.ai/models/mistral-small-3-2-25-06. Mistral Docs. Open v25.06. Released: 2025-06. Accessed: 2026-03-15
2025
-
[23]
Shravan Nayak, Kanishk Jain, Rabiul Awal, Siva Reddy, Sjoerd Van Steenkiste, Lisa Anne Hendricks, Karolina Stanczak, and Aishwarya Agrawal. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.329 Benchmarking vision language models for cultural understanding . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5...
-
[24]
OpenAI . 2026 a . Gpt-5 mini model. https://developers.openai.com/api/docs/models/gpt-5-mini. OpenAI API documentation. Accessed: 2026-03-15
2026
-
[25]
OpenAI . 2026 b . Gpt image 1.5 model. https://developers.openai.com/api/docs/models/gpt-image-1.5. OpenAI API documentation. Accessed: 2026-03-15
2026
-
[26]
Vikram V Ramaswamy, Sing Yu Lin, Dora Zhao, Aaron Adcock, Laurens Van Der Maaten, Deepti Ghadiyaram, and Olga Russakovsky. 2023. Geode: a geographically diverse evaluation dataset for object recognition. Advances in Neural Information Processing Systems, 36:66127--66137
2023
-
[27]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect? In International conference on machine learning, pages 29971--30004. PMLR
2023
-
[28]
Florian Schneider, Carolin Holtermann, Chris Biemann, and Anne Lauscher. 2025. https://doi.org/10.18653/v1/2025.findings-acl.500 GIMMICK : Globally inclusive multimodal multitask cultural knowledge benchmarking . In Findings of the Association for Computational Linguistics: ACL 2025, pages 9605--9668, Vienna, Austria. Association for Computational Linguistics
- [29]
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. 2022. Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238--5248
2022
-
[33]
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568--9578
2024
-
[34]
Ashmal Vayani, Dinura Dissanayake, Hasindri Watawana, Noor Ahsan, Nevasini Sasikumar, Omkar Thawakar, Henok Biadglign Ademtew, Yahya Hmaiti, Amandeep Kumar, Kartik Kukreja, and 1 others. 2025. All languages matter: Evaluating lmms on culturally diverse 100 languages. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19565--19575
2025
- [35]
-
[36]
World Values Survey Association . 2022. World values survey wave 7 (2017--2022): Documentation and data download. https://www.worldvaluessurvey.org/WVSDocumentationWV7.jsp. Accessed 2026-03-06
2022
-
[37]
Shaoyang Xu, Yongqi Leng, Linhao Yu, and Deyi Xiong. 2025. https://doi.org/10.18653/v1/2025.naacl-long.350 Self-pluralising culture alignment for large language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6...
-
[38]
Zhenran Xu, Senbao Shi, Baotian Hu, Longyue Wang, and Min Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.81 Multiskill: Evaluating large multimodal models for fine-grained alignment skills . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 1506--1523, Miami, Florida, USA. Association for Computational Linguistics
-
[39]
Srishti Yadav, Zhi Zhang, Daniel Hershcovich, and Ekaterina Shutova. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.422 Beyond words: Exploring cultural value sensitivity in multimodal models . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 7607--7623, Albuquerque, New Mexico. Association for Computational Linguistics
-
[40]
Haozhe Zhao, Shuzheng Si, Liang Chen, Yichi Zhang, Maosong Sun, Baobao Chang, and Minjia Zhang. 2025 a . Looking beyond text: Reducing language bias in large vision-language models via multimodal dual-attention and soft-image guidance. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19677--19701
2025
-
[41]
Wenlong Zhao, Debanjan Mondal, Niket Tandon, Danica Dillion, Kurt Gray, and Yuling Gu. 2024. Worldvaluesbench: A large-scale benchmark dataset for multi-cultural value awareness of language models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 17696--17706
2024
-
[42]
Xiangyu Zhao, Shengyuan Ding, Zicheng Zhang, Haian Huang, Maosong Cao, Weiyun Wang, Jiaqi Wang, Xinyu Fang, Wenhai Wang, Guangtao Zhai, Haodong Duan, Hua Yang, and Kai Chen. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.906 O mni A lign- V : Towards enhanced alignment of MLLM s with human preference . In Proceedings of the 63rd Annual Meeting of the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.