Recognition: 2 theorem links
· Lean TheoremTransformer See, Transformer Do: Copying as an Intermediate Step in Learning Analogical Reasoning
Pith reviewed 2026-05-10 18:38 UTC · model grok-4.3
The pith
Including copying tasks in training lets transformers learn letter-string analogies by attending to the most informative elements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
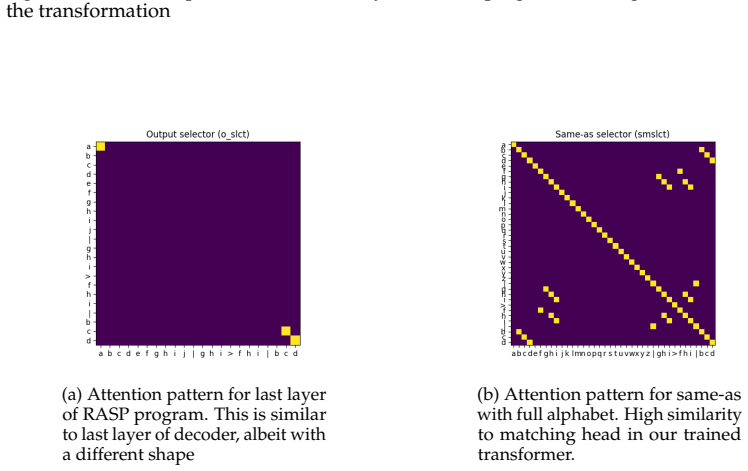
Letter-string analogies become learnable when guiding the models to attend to the most informative problem elements induced by including copying tasks in the training data. Furthermore, generalization to new alphabets becomes better when models are trained with more heterogeneous datasets, where our 3-layer encoder-decoder model outperforms most frontier models. The MLC approach also enables some generalization to compositions of trained transformations, but not to completely novel transformations. To understand how the model operates, we identify an algorithm that approximates the model's computations and verify this using interpretability analyses.
What carries the argument
The addition of copying tasks to the meta-learning training data, which induces attention to the most informative elements of each analogy problem.
If this is right
- Transformers can learn to solve letter-string analogies once copying is included as an intermediate training step.
- Greater heterogeneity in the training alphabets improves generalization to unseen alphabets.
- A compact three-layer encoder-decoder model can exceed the performance of most larger frontier models on this generalization test.
- The trained models transfer to some recombinations of learned transformations but fail on entirely new ones.
- The model's internal computations can be approximated by a simple algorithm that allows precise steering of its behavior.
Where Pith is reading between the lines
- The same copying-based intermediate step might improve analogical reasoning in much larger language models without requiring full retraining.
- Human solvers of letter-string problems may also rely on an implicit copying-like focus on relational structure before mapping.
- Applying the copying pre-training step to other structured reasoning domains could test whether it is a general route to better relational attention.
Load-bearing premise
That the copying tasks are what specifically cause the model to attend to the informative problem elements, as opposed to other features of the data or training procedure.
What would settle it
Train identical models on the letter-string task without any copying examples and check whether accuracy on new alphabets falls to the low levels seen in the original non-copying runs.
Figures











read the original abstract
Analogical reasoning is a hallmark of human intelligence, enabling us to solve new problems by transferring knowledge from one situation to another. Yet, developing artificial intelligence systems capable of robust human-like analogical reasoning has proven difficult. In this work, we train transformers using Meta-Learning for Compositionality (MLC) on an analogical reasoning task (letter-string analogies) and assess their generalization capabilities. We find that letter-string analogies become learnable when guiding the models to attend to the most informative problem elements induced by including copying tasks in the training data. Furthermore, generalization to new alphabets becomes better when models are trained with more heterogeneous datasets, where our 3-layer encoder-decoder model outperforms most frontier models. The MLC approach also enables some generalization to compositions of trained transformations, but not to completely novel transformations. To understand how the model operates, we identify an algorithm that approximates the model's computations. We verify this using interpretability analyses and show that the model can be steered precisely according to expectations derived from the algorithm. Finally, we discuss implications of our findings for generalization capabilities of larger models and parallels to human analogical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains small transformer models using Meta-Learning for Compositionality (MLC) on letter-string analogy tasks. It claims that including copying tasks in the training data guides the models to attend to the most informative problem elements, thereby making analogical reasoning learnable. Generalization to new alphabets improves with more heterogeneous training datasets, and a 3-layer encoder-decoder model outperforms most frontier models on this metric. The approach yields partial generalization to compositions of trained transformations but not to entirely novel ones. Interpretability analyses identify an algorithm approximating the model's computations, which is verified and used to steer model behavior.
Significance. If the empirical findings and causal attribution hold after proper controls, the work would demonstrate that auxiliary copying tasks can serve as an effective intermediate step for inducing structured attention patterns that support analogical reasoning in transformers. The mechanistic interpretability component, including the identified algorithm and steering experiments, strengthens the contribution by providing falsifiable, verifiable insights rather than purely black-box performance claims. This could inform training strategies for compositionality and generalization in larger models and draw parallels to human analogical reasoning.
major comments (2)
- [Abstract / Results] Abstract and Results: The central claim that copying tasks specifically induce attention to the most informative elements (rather than MLC meta-learning, dataset heterogeneity, or total training volume) lacks isolating controls. No experiments are described that hold data size, diversity, and training procedure fixed while toggling only the presence/absence of copying tasks versus other auxiliary objectives, making the causal attribution load-bearing but unsupported.
- [Abstract] Abstract: The statement that the 3-layer encoder-decoder 'outperforms most frontier models' on new-alphabet generalization requires explicit details on the exact frontier models tested, evaluation metrics, number of trials, statistical tests, and error bars to assess whether the comparison is robust and not driven by differences in training regime or evaluation protocol.
minor comments (1)
- [Abstract] The abstract provides high-level findings but omits key methodological details (datasets, statistical tests, baselines, error analysis) that would allow readers to evaluate the strength of the reported generalization results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our causal claims and reporting. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: The central claim that copying tasks specifically induce attention to the most informative elements (rather than MLC meta-learning, dataset heterogeneity, or total training volume) lacks isolating controls. No experiments are described that hold data size, diversity, and training procedure fixed while toggling only the presence/absence of copying tasks versus other auxiliary objectives, making the causal attribution load-bearing but unsupported.
Authors: We agree that stronger isolation of the copying task's role would bolster the causal attribution. Our current experiments compare MLC training with and without copying tasks (while varying dataset heterogeneity), and the mechanistic analyses link copying-induced attention patterns to improved analogy performance. However, we did not test against matched alternative auxiliary objectives. In the revision, we will add new control experiments that hold total data volume, diversity, and training procedure fixed while comparing copying tasks to other auxiliaries (e.g., random masking or repetition tasks). This will allow direct assessment of whether copying specifically drives the observed attention and generalization benefits. revision: yes
-
Referee: [Abstract] Abstract: The statement that the 3-layer encoder-decoder 'outperforms most frontier models' on new-alphabet generalization requires explicit details on the exact frontier models tested, evaluation metrics, number of trials, statistical tests, and error bars to assess whether the comparison is robust and not driven by differences in training regime or evaluation protocol.
Authors: We acknowledge that the abstract statement requires supporting details for proper evaluation. The main text reports comparisons to specific models (including GPT-4, Claude-3, and Gemini) using exact-match accuracy on held-out alphabets, with results averaged over multiple random seeds. In the revised version, we will expand both the abstract and results section to explicitly list the frontier models, the precise metrics and protocols, the number of evaluation trials, any statistical tests applied, and error bars. We will also clarify training and evaluation differences to ensure the comparison is transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical training results on letter-string analogies do not reduce to inputs by construction
full rationale
The paper reports experimental outcomes from training 3-layer encoder-decoder transformers via MLC on letter-string analogy tasks, with and without copying subtasks, and measures generalization to new alphabets and compositions. No equations, derivations, fitted parameters, or first-principles claims appear; the central findings (learnability induced by copying tasks, better generalization with heterogeneous data) are presented as direct results of the reported training regimes and test evaluations rather than any self-referential reduction or renamed fit. Any MLC reference is external methodological context and does not substitute for the empirical isolation or verification steps described.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/0010-0285(88)90014-X
ISSN 0010-0285. doi: 10.1016/0010-0285(88)90014-X. Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. ARC Prize 2024: Technical Report, January
-
[2]
ISSN 2374-3468. doi: 10.1609/aaai.v35i1.16163. Leonidas A. A. Doumas, John E. Hummel, and Catherine M. Sandhofer. A theory of the discovery and predication of relational concepts.Psychological Review, 115(1):1–43,
-
[3]
doi: 10.1037/0033-295X.115.1.1
ISSN 1939-1471. doi: 10.1037/0033-295X.115.1.1. Leonidas A. A. Doumas, Guillermo Puebla, Andrea E. Martin, and John E. Hummel. A theory of relation learning and cross-domain generalization.Psychological Review, 129(5): 999–1041,
-
[4]
ISSN 1939-1471. doi: 10.1037/rev0000346. Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, and Pieter Abbeel. RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning, November
-
[5]
ISSN 0364-0213. doi: 10.1016/S0364-0213(83)80009-3. Dedre Gentner and Christian Hoyos. Analogy and Abstraction.Topics in Cognitive Science, 9 (3):672–693,
-
[6]
ISSN 1756-8765. doi: 10.1111/tops.12278. Damian Hodel and Jevin West. Response: Emergent analogical reasoning in large language models, May
-
[7]
doi: 10.1109/TPAMI.2021.3079209
ISSN 1939-3539. doi: 10.1109/TPAMI.2021.3079209. John E. Hummel and Keith J. Holyoak. Distributed representations of structure: A theory of analogical access and mapping.Psychological Review, 104(3):427–466,
-
[8]
doi: 10.1037/0033-295X.104.3.427
ISSN 1939-1471. doi: 10.1037/0033-295X.104.3.427. Tamar Johnson, Mathilde ter Veen, Rochelle Choenni, Han van der Maas, Ekaterina Shutova, and Claire E Stevenson. Do large language models solve verbal analogies like children do? InProceedings of the 29th Conference on Computational Natural Language Learning, pp. 627–639. Association for Computational Ling...
-
[9]
Youngsung Kim, Jinwoo Shin, Eunho Yang, and Sung Ju Hwang
doi: 10.18653/v1/2025.conll-1.40. Youngsung Kim, Jinwoo Shin, Eunho Yang, and Sung Ju Hwang. Few-shot Visual Reasoning with Meta-Analogical Contrastive Learning. InAdvances in Neural Information Processing Systems, volume 33, pp. 16846–16856. Curran Associates, Inc.,
-
[10]
doi: 10.1038/s41586-023-06668-3
ISSN 1476-4687. doi: 10.1038/s41586-023-06668-3. Jihwan Lee, Woochang Sim, Sejin Kim, and Sundong Kim. Enhancing Analogical Reasoning in the Abstraction and Reasoning Corpus via Model-Based RL, August
-
[11]
doi: 10.1109/ICDM54844.2022.00132. Evan Z. Liu, Aditi Raghunathan, Percy Liang, and Chelsea Finn. Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices. InProceedings of the 38th International Conference on Machine Learning, pp. 6925–6935. PMLR, July
-
[12]
Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L
doi: 10.1073/pnas.2322420121. Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple word2vec-style vector arithmetic. InNorth American Chapter of the Association for Computa- tional Linguistics,
-
[13]
In-context Learning and Induction Heads
URLhttps://api.semanticscholar.org/CorpusID:258887799. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review arXiv
-
[14]
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap
URL https://arxiv.org/ pdf/2509.09381. Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-Learning with Memory-Augmented Neural Networks. InProceedings of The 33rd International Conference on Machine Learning, pp. 1842–1850. PMLR, June
-
[15]
doi: 10.1016/j.cobeha.2021.01.002
ISSN 2352-1546. doi: 10.1016/j.cobeha.2021.01.002. Taylor Webb, Keith J. Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models.Nature Human Behaviour, 7(9):1526–1541, September
-
[16]
doi: 10.1038/s41562-023-01659-w. Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Proceedings of the 2024 Conference o...
-
[17]
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.102. Hattie Zhou, Arwen Bradley, Etai Littwin, Noam Razin, Omid Saremi, Joshua M Susskind, Samy Bengio, and Preetum Nakkiran. What algorithms can transformers learn? a study in length generalization. InThe Twelfth International Conference on Learning Representations,
-
[18]
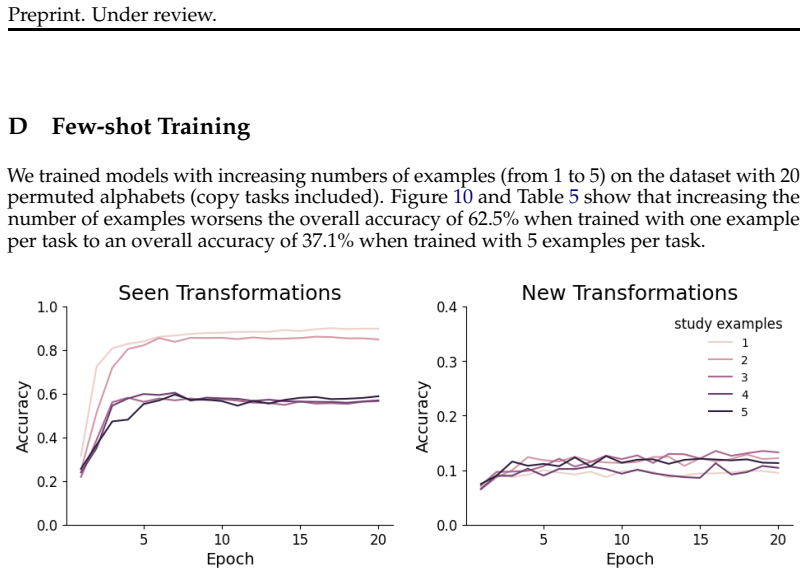
on the dataset with 20 permuted alphabets (copy tasks included). Figure 10 and Table 5 show that increasing the number of examples worsens the overall accuracy of 62.5% when trained with one example per task to an overall accuracy of 37.1% when trained with 5 examples per task. Figure 10: Validation accuracy declines when providing the model with more exa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.