Recognition: 3 theorem links
· Lean TheoremExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilistic Circuits
Pith reviewed 2026-05-10 18:34 UTC · model grok-4.3
The pith
Probabilistic circuits compiled from grammars generate more realistic test inputs that satisfy constraints and trigger more bugs than mutational fuzzing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
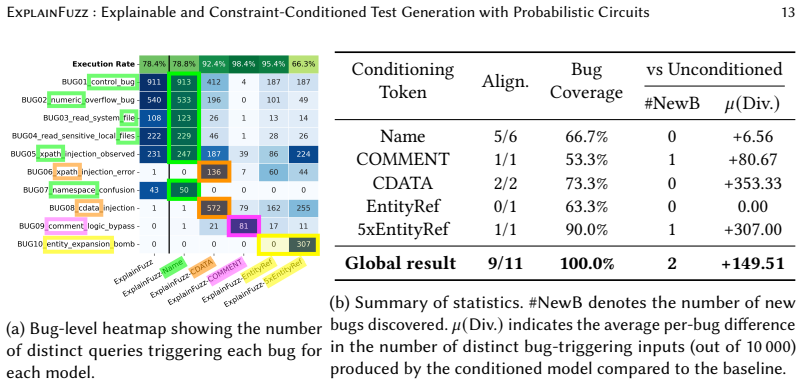
ExplainFuzz compiles a context-free grammar into a probabilistic circuit, trains the circuit on sample inputs to capture their distribution, and generates new inputs by sampling, either freely or conditioned on user constraints such as requiring a GROUP BY clause. This produces inputs with reduced perplexity relative to probabilistic context-free grammars, grammar-unaware circuits, and language models, greater diversity under constraints, and higher bug-triggering effectiveness, raising rates from 35 percent to 63 percent in SQL and from 10 percent to 100 percent in XML compared with grammar-aware mutational fuzzing.
What carries the argument
Probabilistic circuits compiled from a context-free grammar, whose exact conditioning operation enforces user constraints while sampling from the learned distribution over valid inputs.
If this is right
- Generated inputs achieve lower perplexity than probabilistic context-free grammars, grammar-unaware circuits, and large language models.
- Conditioned sampling yields greater variety of inputs that meet user-specified constraints.
- Bug detection improves over mutational fuzzing because the method draws from a global learned distribution rather than local neighborhoods of seed inputs.
Where Pith is reading between the lines
- The method could support testing of other structured formats by swapping the grammar and retraining the circuit on domain-specific samples.
- Explainability features might help developers understand which input properties most often trigger particular classes of bugs.
Load-bearing premise
Training a probabilistic circuit on a finite set of sample inputs will faithfully represent the full distribution of realistic, context-sensitive test cases, and conditioning will enforce constraints without creating invalid or improbable outputs.
What would settle it
An experiment on the same SQL and XML targets that finds no improvement in bug-triggering rates over grammar-aware mutational fuzzing or that shows conditioned samples frequently violating the grammar rules.
Figures












read the original abstract
Understanding and explaining the structure of generated test inputs is essential for effective software testing and debugging. Existing approaches--including grammar-based fuzzers, probabilistic Context-Free Grammars (pCFGs), and Large Language Models (LLMs)--suffer from critical limitations. They frequently produce ill-formed inputs that fail to reflect realistic data distributions, struggle to capture context-sensitive probabilistic dependencies, and lack explainability. We introduce ExplainFuzz, a test generation framework that leverages Probabilistic Circuits (PCs) to learn and query structured distributions over grammar-based test inputs interpretably and controllably. Starting from a Context-Free Grammar (CFG), ExplainFuzz compiles a grammar-aware PC and trains it on existing inputs. New inputs are then generated via sampling. ExplainFuzz utilizes the conditioning capability of PCs to incorporate test-specific constraints (e.g., a query must have GROUP BY), enabling constrained probabilistic sampling to generate inputs satisfying grammar and user-provided constraints. Our results show that ExplainFuzz improves the coherence and realism of generated inputs, achieving significant perplexity reduction compared to pCFGs, grammar-unaware PCs, and LLMs. By leveraging its native conditioning capability, ExplainFuzz significantly enhances the diversity of inputs that satisfy a user-provided constraint. Compared to grammar-aware mutational fuzzing, ExplainFuzz increases bug-triggering rates from 35% to 63% in SQL and from 10% to 100% in XML. These results demonstrate the power of a learned input distribution over mutational fuzzing, which is often limited to exploring the local neighborhood of seed inputs. These capabilities highlight the potential of PCs to serve as a foundation for grammar-aware, controllable test generation that captures context-sensitive, probabilistic dependencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExplainFuzz, a test generation framework that compiles a grammar-aware Probabilistic Circuit from a CFG, trains it on existing inputs, and leverages PC conditioning to generate new inputs satisfying both the grammar and user-specified constraints (e.g., presence of GROUP BY). It claims lower perplexity than pCFGs, grammar-unaware PCs, and LLMs, plus substantially higher bug-triggering rates than grammar-aware mutational fuzzing (35% to 63% for SQL, 10% to 100% for XML).
Significance. If the empirical results can be substantiated with proper controls, the work would demonstrate a useful application of PCs' tractable conditioning and sampling for controllable, grammar-respecting test generation that captures probabilistic dependencies better than mutational or LLM baselines. The emphasis on explainability via the circuit structure is a potential strength.
major comments (3)
- [Abstract] Abstract: The reported quantitative gains (perplexity reduction and bug-trigger rates of 35%→63% SQL / 10%→100% XML) are presented without any experimental protocol, sample counts, statistical tests, dataset sizes, or ablation details. This makes the central claims unverifiable from the manuscript text and load-bearing for acceptance.
- [Experimental evaluation] Experimental evaluation: No post-conditioning validity audit against the original CFG parser is described. Because bug-triggering rates are compared to a grammar-aware mutational fuzzer that produces only valid inputs by construction, the absence of such a check risks confounding the results if conditioning places mass on out-of-grammar structures.
- [Method] Method section on PC compilation and conditioning: The description does not establish that the conditioning operation preserves strict grammatical validity while enforcing constraints. This directly affects the weakest assumption that the learned distribution plus conditioning yields realistic, valid inputs without distortion.
minor comments (1)
- [Abstract] The abstract uses 'perplexity' for cross-model comparisons without defining its exact computation for each baseline (pCFGs, PCs, LLMs).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for improving the clarity and rigor of our claims. We address each major comment below and will revise the manuscript to incorporate the suggested enhancements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported quantitative gains (perplexity reduction and bug-trigger rates of 35%→63% SQL / 10%→100% XML) are presented without any experimental protocol, sample counts, statistical tests, dataset sizes, or ablation details. This makes the central claims unverifiable from the manuscript text and load-bearing for acceptance.
Authors: We agree that the abstract, being a concise summary, does not include the full experimental protocol details. The manuscript's Experimental Evaluation section provides dataset descriptions, generation sample counts, baseline comparisons, and statistical analysis. To address the verifiability concern directly from the abstract, we will revise it to incorporate a brief statement on the evaluation protocol, including sample sizes and the use of statistical tests for the reported gains. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: No post-conditioning validity audit against the original CFG parser is described. Because bug-triggering rates are compared to a grammar-aware mutational fuzzer that produces only valid inputs by construction, the absence of such a check risks confounding the results if conditioning places mass on out-of-grammar structures.
Authors: This is a valid concern regarding potential confounding. Our PC is compiled from the CFG such that its structure encodes only valid derivations, and conditioning operates on grammar-aligned variables without introducing invalid paths. To explicitly substantiate this and eliminate any risk of confounding, we will add a post-conditioning validity audit in the revised Experimental Evaluation section: all generated inputs will be parsed with the original CFG parser, with validity rates reported (expected to be 100%). revision: yes
-
Referee: [Method] Method section on PC compilation and conditioning: The description does not establish that the conditioning operation preserves strict grammatical validity while enforcing constraints. This directly affects the weakest assumption that the learned distribution plus conditioning yields realistic, valid inputs without distortion.
Authors: We appreciate the call for greater methodological clarity. The compilation process builds the PC topology directly from CFG productions, ensuring no invalid structures exist in the circuit; conditioning then clamps evidence on these variables while respecting the existing topology. To strengthen this, we will revise the Method section with an explicit argument (including a brief proof sketch) demonstrating that conditioning preserves strict grammatical validity, along with additional pseudocode for the compilation and conditioning procedures. revision: yes
Circularity Check
No circularity; all claims rest on external empirical benchmarks
full rationale
The paper introduces ExplainFuzz as a PC-based framework compiled from a CFG, trained on existing inputs, and using conditioning for constraints. All load-bearing claims (perplexity reductions vs. pCFGs/LLMs, bug-triggering rate gains vs. mutational fuzzing) are measured against independent external baselines and datasets. No equation, sampling procedure, or prediction is defined in terms of its own fitted values or reduces to a self-citation theorem. Self-citations to PC conditioning literature are not load-bearing for the reported results.
Axiom & Free-Parameter Ledger
free parameters (1)
- PC parameters
axioms (2)
- domain assumption A supplied context-free grammar correctly defines the space of valid inputs
- domain assumption The training corpus is representative of realistic, context-sensitive input distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAlgorithm 1 PC construction ... for symbol s ∈ symbols(G) ... add sum node (s,i,j) ... product node for each rule ... prune nodes not connected to root
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPCs support ... conditioning ... targeted sampling ... P(HAVING|GROUP)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearperplexity reduction ... 1.27× vs pCFGs ... bug-triggering rates ... 35% to 63% SQL
Reference graph
Works this paper leans on
-
[1]
Oliver Broadrick, Sanyam Agarwal, Guy Van den Broeck, and Markus Bläser. 2025. The Limits of Tractable Marginal- ization. InProceedings of the 42th International Conference on Machine Learning (ICML). https://starai.cs.ucla.edu/ papers/BroadrickICML25.pdf
2025
-
[2]
Eugene Charniak. 1997. Statistical parsing with a context-free grammar and word statistics. InProceedings of the Fourteenth National Conference on Artificial Intelligence and Ninth Conference on Innovative Applications of Artificial Intelligence(Providence, Rhode Island)(AAAI’97/IAAI’97). AAAI Press, 598–603
1997
-
[3]
Wei-Chen Cheng, Stanley Kok, Hoai Vu Pham, Hai Leong Chieu, and Kian Ming Adam Chai. 2014. Language modeling with sum-product networks.. InInterspeech, Vol. 2014. 2098–2102
2014
-
[4]
YooJung Choi, Antonio Vergari, and Guy Van den Broeck. 2020. Probabilistic Circuits: A Unifying Framework for Tractable Probabilistic Models. (2020)
2020
-
[5]
Poorva Garg, Benjie Wang, Oliver Broadrick, Guy Van den Broeck, and Todd Millstein. 2025. Bitblasting for Constrained Decorrelation in Tractable Image Modeling. InProceedings of the UAI Workshop on Tractable Probabilistic Modeling (TPM). http://starai.cs.ucla.edu/papers/GargTPM25.pdf
2025
-
[6]
Renáta Hodován, Ákos Kiss, and Tibor Gyimóthy. 2018. Grammarinator: a grammar-based open source fuzzer. In Proceedings of the 9th ACM SIGSOFT International Workshop on Automating TEST Case Design, Selection, and Evaluation (Lake Buena Vista, FL, USA)(A-TEST 2018). Association for Computing Machinery, New York, NY, USA, 45–48. doi:10.1145/3278186.3278193
-
[7]
Anji Liu, Kareem Ahmed, and Guy Van Den Broeck. 2024. Scaling tractable probabilistic circuits: a systems perspective. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1234, 17 pages
2024
-
[8]
Anji Liu, Stephan Mandt, and Guy Van den Broeck. 2022. Lossless Compression with Probabilistic Circuits. In Proceedings of the International Conference on Learning Representations (ICLR)
2022
-
[9]
Sladek Aleksanteri, Stefan Mengel, Martin Trapp, Arno Solin, Nicolas Gillis, and Antonio Vergari
Lorenzo Loconte, M. Sladek Aleksanteri, Stefan Mengel, Martin Trapp, Arno Solin, Nicolas Gillis, and Antonio Vergari
-
[10]
InThe Twelfth International Conference on Learning Representations
Subtractive Mixture Models via Squaring: Representation and Learning. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=xIHi5nxu9P
-
[11]
Lorenzo Loconte, Nicola Di Mauro, Robert Peharz, and Antonio Vergari. 2023. How to turn your knowledge graph embeddings into generative models.Advances in Neural Information Processing Systems36 (2023), 77713–77744
2023
-
[12]
Jaron Maene, Vincent Derkinderen, and Pedro Zuidberg Dos Martires. 2025. KLay: Accelerating Arithmetic Circuits for Neurosymbolic AI. InThe Thirteenth International Conference on Learning Representations
2025
-
[13]
1999.Foundations of statistical natural language processing
Christopher D Manning and Hinrich Schutze. 1999.Foundations of statistical natural language processing. MIT Press, London, England
1999
-
[14]
MITRE. 2006. CWE-190: Integer Overflow or Wraparound. https://cwe.mitre.org/data/definitions/190.html Accessed: 2025
2006
-
[15]
MITRE. 2008. CWE-643: Improper Neutralization of Data within XPath Expressions. https://cwe.mitre.org/data/ definitions/643.html Accessed: 2025
2008
-
[16]
National Institute of Standards and Technology. 2018. CVE-2018-14665: X.Org Server Arbitrary File Read Vulnerability. https://nvd.nist.gov/vuln/detail/CVE-2018-14665 Accessed: 2025
2018
-
[17]
Hoifung Poon and Pedro Domingos. 2011. Sum-product networks: a new deep architecture. InProceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence(Barcelona, Spain)(UAI’11). AUAI Press, Arlington, Virginia, USA, 337–346
2011
-
[18]
L.R. Rabiner. 1989. A tutorial on hidden Markov models and selected applications in speech recognition.Proc. IEEE77, 2 (1989), 257–286. doi:10.1109/5.18626
-
[19]
Tahrima Rahman, Prasanna Kothalkar, and Vibhav Gogate. 2014. Cutset networks: A simple, tractable, and scalable approach for improving the accuracy of chow-liu trees. InJoint European conference on machine learning and knowledge discovery in databases. Springer, 630–645
2014
-
[20]
Andreas Seltenreich, Bo Tang, and Sjoerd Mullender. 2018. SQLsmith: a random SQL query generator. https://github. com/anse1/sqlsmith. Accessed: 2025-05-22
2018
-
[21]
Jonas Seng, Florian Peter Busch, Pooja Prasad, Devendra Singh Dhami, Martin Mundt, and Kristian Kersting. 2025. Scaling Probabilistic Circuits via Data Partitioning. InConference on Uncertainty in Artificial Intelligence. PMLR, 3701–3717
2025
-
[22]
Sahil Sidheekh and Sriraam Natarajan. 2024. Building expressive and tractable probabilistic generative models: a review. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 8234–8243
2024
-
[23]
Ezekiel Soremekun, Esteban Pavese, Nikolas Havrikov, Lars Grunske, and Andreas Zeller. 2022. Inputs From Hell:. IEEE Transactions on Software Engineering48, 4 (2022), 1138–1153. doi:10.1109/TSE.2020.3013716
-
[24]
Pierce, and Guy Van den Broeck
Ryan Tjoa, Poorva Garg, Harrison Goldstein, Todd Millstein, Benjamin C. Pierce, and Guy Van den Broeck. 2025. Tuning Random Generators: Property-Based Testing as Probabilistic Programming. InProc. ACM Program. Lang. , Vol. 1, No. 1, Article . Publication date: April 2026. ExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilist...
-
[25]
Antonio Vergari, YooJung Choi, Anji Liu, Stefano Teso, and Guy Van den Broeck. 2021. A compositional atlas of tractable circuit operations for probabilistic inference.Advances in Neural Information Processing Systems34 (2021), 13189–13201
2021
-
[26]
Benjie Wang, Denis Deratani Mauá, Guy Van den Broeck, and YooJung Choi. 2024. A Compositional Atlas for Algebraic Circuits. InConference on Neural Information Processing Systems (NeurIPS)
2024
-
[27]
Benjie Wang and Guy Van den Broeck. 2025. On the Relationship Between Monotone and Squared Probabilistic Circuits. InAAAI Conference on Artificial Intelligence
2025
-
[28]
Gwen Yidou-Weng, Benjie Wang, and Guy Van den Broeck. 2025. TRACE Back from the Future: A Probabilistic Reasoning Approach to Controllable Language Generation. InInternational Conference on Machine Learning
2025
-
[29]
Fabio Massimo Zanzotto, Giorgio Satta, and Giordano Cristini. 2020. CYK Parsing over Distributed Representations. Algorithms13, 10 (Oct. 2020), 262. doi:10.3390/a13100262
-
[30]
Honghua Zhang, Meihua Dang, Benjie Wang, Stefano Ermon, Nanyun Peng, and Guy Van den Broeck. 2025. Scaling Probabilistic Circuits via Monarch Matrices. InInternational Conference on Machine Learning
2025
-
[31]
Honghua Zhang, Po-Nien Kung, Masahiro Yoshida, Guy Van den Broeck, and Nanyun Peng. 2024. Adaptable logical control for large language models.Advances in Neural Information Processing Systems37 (2024), 115563–115587. , Vol. 1, No. 1, Article . Publication date: April 2026. 22 Annaëlle Baiget, Jaron Maene, Seongmin Lee, Benjie Wang, Guy Van den Broeck, and...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.