Recognition: 2 theorem links
· Lean TheoremDynLP: Parallel Dynamic Batch Update for Label Propagation in Semi-Supervised Learning
Pith reviewed 2026-05-10 18:32 UTC · model grok-4.3
The pith
DynLP updates labels in semi-supervised graph learning by propagating changes only through the affected subgraph for each new batch of data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
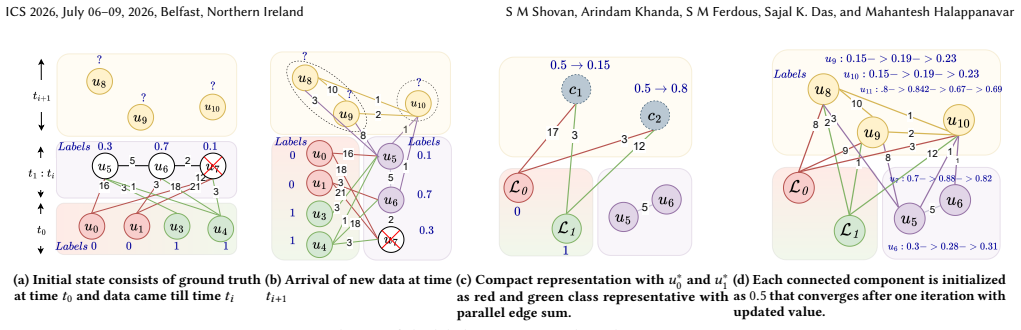
DynLP is a GPU-centric algorithm that performs dynamic batched parallel label propagation by executing only the necessary updates on the relevant subgraph after each batch of new data arrives, rather than recomputing labels across the entire graph. The method exploits GPU architectural features to achieve these targeted updates efficiently.
What carries the argument
DynLP, the dynamic batched parallel label propagation algorithm that restricts propagation to the relevant subgraph for each batch update.
If this is right
- Large graphs receiving regular batch updates can maintain labels without the full recomputation cost each time.
- GPU hardware can be used more effectively for semi-supervised tasks by focusing parallel work on small changing regions.
- State-of-the-art static label propagation methods become slower than necessary once data arrives incrementally.
- The overall time to process successive batches scales with the size of the change rather than the size of the whole graph.
Where Pith is reading between the lines
- Similar subgraph-limited update strategies could apply to other iterative graph algorithms that currently restart from scratch on new data.
- If the subgraph identification step itself stays fast, the approach may extend to streaming scenarios where batches arrive continuously rather than in discrete steps.
- Integration with distributed systems beyond single GPUs could further reduce wall-clock time for very large evolving graphs.
Load-bearing premise
The labels produced by updating only the relevant subgraph match the labels that would result from running full label propagation over the complete graph.
What would settle it
Running both DynLP and a full label propagation recomputation on the same graph after a batch arrival and finding any node whose label differs between the two outputs.
Figures







read the original abstract
Semi-supervised learning aims to infer class labels using only a small fraction of labeled data. In graph-based semi-supervised learning, this is typically achieved through label propagation to predict labels of unlabeled nodes. However, in real-world applications, data often arrive incrementally in batches. Each time a new batch appears, reapplying the traditional label propagation algorithm to recompute all labels is redundant, computationally intensive, and inefficient. To address the absence of an efficient label propagation update method, we propose DynLP, a novel GPU-centric Dynamic Batched Parallel Label Propagation algorithm that performs only the necessary updates, propagating changes to the relevant subgraph without requiring full recalculation. By exploiting GPU architectural optimizations, our algorithm achieves on average 13x and upto 102x speedup on large-scale datasets compared to state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DynLP, a GPU-centric algorithm for dynamic batched label propagation in graph-based semi-supervised learning. It updates only a relevant subgraph after each batch arrival instead of recomputing labels over the full graph, and reports average 13x (up to 102x) speedups versus prior state-of-the-art methods on large-scale datasets.
Significance. If the subgraph updates are proven to produce labels equivalent to full propagation, the work would offer a practical advance for incremental semi-supervised learning on dynamic graphs, where repeated full recomputation is prohibitive. The GPU-specific optimizations could translate to meaningful throughput gains in production settings.
major comments (1)
- [Algorithm description (and any accompanying correctness argument)] The manuscript provides no convergence invariant, distance bound, or equivalence proof showing that restricting propagation to the selected subgraph after a batch update yields the same fixed point as re-running label propagation on the entire updated graph. Because label propagation is a global diffusion process, any subgraph rule that omits paths can alter labels; this equivalence is load-bearing for the speedup claims.
minor comments (1)
- The abstract states speedups but does not name the datasets, graph sizes, or baseline implementations used to obtain the 13x/102x figures; adding this context would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of a formal correctness argument. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Algorithm description (and any accompanying correctness argument)] The manuscript provides no convergence invariant, distance bound, or equivalence proof showing that restricting propagation to the selected subgraph after a batch update yields the same fixed point as re-running label propagation on the entire updated graph. Because label propagation is a global diffusion process, any subgraph rule that omits paths can alter labels; this equivalence is load-bearing for the speedup claims.
Authors: We agree that the manuscript currently lacks an explicit convergence invariant, distance bound, or formal equivalence proof. The algorithm description explains the heuristic for selecting the relevant subgraph (nodes reachable from the batch via propagation paths) but does not rigorously demonstrate that this yields the identical fixed point as full-graph label propagation. In the revised manuscript we will add a dedicated subsection that (1) defines the subgraph selection rule formally, (2) states the invariant that labels of nodes outside the subgraph remain unchanged, and (3) provides a proof sketch showing that iterative updates confined to the subgraph converge to the same solution as re-running the full algorithm, because all paths that could affect any label are included by construction. revision: yes
Circularity Check
No circularity detected in algorithmic contribution
full rationale
The paper proposes a new GPU-centric algorithm (DynLP) for dynamic batched label propagation that restricts updates to a relevant subgraph. No mathematical derivations, fitted parameters, or self-citation chains appear in the provided text that would reduce any claim to an input by construction. The speedup results are presented as empirical outcomes of the algorithm's design rather than predictions derived from prior fits or renamed known results. The core assumption of label equivalence is stated as a design goal but is not used to circularly justify the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of label propagation algorithms in graphs, such as the graph structure representing similarity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DynLP performs only the necessary updates, propagating changes to the relevant subgraph without requiring full recalculation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the update rule is equivalent to standard weighted neighborhood averaging
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Roberto J Bayardo, Yiming Ma, and Ramakrishnan Srikant. 2007. Scaling up all pairs similarity search. InProceedings of the 16th international conference on World Wide Web. 131–140
2007
-
[2]
Dominik Bünger, Miriam Gondos, Lucile Peroche, and Martin Stoll. 2022. An empirical study of graph-based approaches for semi-supervised time series clas- sification.Frontiers in Applied Mathematics and Statistics7 (2022), 784855
2022
-
[3]
Olivier Chapelle, Bernhard Schölkopf, Alexander Zien, et al . 2006. Semi- supervised learning, vol. 2.Cambridge: MIT Press. Cortes, C., & Mohri, M.(2014). Domain adaptation and sample bias correction theory and algorithm for regression. Theoretical Computer Science519 (2006), 103126
2006
-
[4]
Yanwen Chong, Yun Ding, Qing Yan, and Shaoming Pan. 2020. Graph-based semi-supervised learning: A review.Neurocomputing408 (2020), 216–230. doi:10. 1016/j.neucom.2019.12.130
2020
-
[5]
Michele Covell. 2013. Efficient and accurate label propagation on large graphs and label sets. (2013)
2013
-
[6]
Olivier Delalleau, Yoshua Bengio, and Nicolas Le Roux. 2005. Efficient non- parametric function induction in semi-supervised learning. InInternational Work- shop on Artificial Intelligence and Statistics. PMLR, 96–103
2005
-
[7]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
2009
-
[8]
Michael Desmond, Evelyn Duesterwald, Kristina Brimijoin, Michelle Brachman, and Qian Pan. 2021. Semi-automated data labeling. InNeurIPS 2020 competition and demonstration track. PMLR, 156–169
2021
-
[9]
Salah Ud Din, Junming Shao, Jay Kumar, Waqar Ali, Jiaming Liu, and Yu Ye. 2020. Online reliable semi-supervised learning on evolving data streams.Information Sciences525 (2020), 153–171
2020
-
[10]
Salah Ud Din, Aman Ullah, Cobbinah B Mawuli, Qinli Yang, and Junming Shao
-
[11]
A reliable adaptive prototype-based learning for evolving data streams with limited labels.Information Processing & Management61, 1 (2024), 103532
2024
-
[12]
Iain S Duff, Albert M Erisman, C William Gear, and John K Reid. 1988. Sparsity structure and Gaussian elimination.ACM Signum newsletter23, 2 (1988), 2–8
1988
-
[13]
Mohsen Fazaeli and Saeedeh Momtazi. 2022. GuidedWalk: Graph embedding with semi-supervised random walk.World Wide Web25, 6 (2022), 2323–2345
2022
-
[14]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[15]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[16]
Bridging Language and Items for Retrieval and Recommendation.arXiv preprint arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Zhiwen Hua and Youlong Yang. 2022. Robust and sparse label propagation for graph-based semi-supervised classification.Applied Intelligence52, 3 (2022), 3337–3351
2022
-
[18]
Lei Huang, Xianglong Liu, Binqiang Ma, and Bo Lang. 2015. Online semi- supervised annotation via proxy-based local consistency propagation.Neu- rocomputing149 (2015), 1573–1586
2015
-
[19]
Yanchao Li, Yongli Wang, Qi Liu, Cheng Bi, Xiaohui Jiang, and Shurong Sun. 2019. Incremental semi-supervised learning on streaming data.Pattern Recognition88 (2019), 383–396
2019
-
[20]
Yu-Feng Li, Shao-Bo Wang, and Zhi-Hua Zhou. 2016. Graph quality judgement: A large margin expedition. InProceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. 1725–1731
2016
- [21]
-
[22]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. InPro- ceedings of the 49th Annual Meeting of the Association for Computational Linguis- tics: Human Language Technologies. Association for Computational Linguistics, Portland, Oregon, USA, 142–150. http://www...
2011
-
[23]
mhamine. n.d.. Yelp Review Dataset. https://www.kaggle.com/datasets/mhamine/ yelp-review-dataset. Kaggle dataset. Accessed: 2026-02-05
2026
-
[24]
Gabriel Ponte, Marcia Fampa, Jon Lee, and Luze Xu. 2024. On computing sparse generalized inverses.Operations Research Letters52 (2024), 107058
2024
-
[25]
Usha Nandini Raghavan, Réka Albert, and Soundar Kumara. 2007. Near linear time algorithm to detect community structures in large-scale networks.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics76, 3 (2007), 036106
2007
-
[26]
Priyesh Ranjan, Ashish Gupta, and Sajal K Das. 2025. Securing federated learning from distributed backdoor attacks via maximal clique and dynamic reputation system. In2025 IEEE International Conference on Smart Computing (SMARTCOMP). IEEE, 130–137
2025
-
[27]
Sujith Ravi and Qiming Diao. 2016. Large scale distributed semi-supervised learning using streaming approximation. InArtificial intelligence and statistics. PMLR, 519–528
2016
-
[28]
Vikas Sindhwani, Partha Niyogi, and Mikhail Belkin. 2005. Beyond the point cloud: from transductive to semi-supervised learning. InProceedings of the 22nd international conference on Machine learning. 824–831
2005
-
[29]
Wen Song, Yi Liu, Zhiguang Cao, Yaoxin Wu, and Qiqiang Li. 2023. Instance- specific algorithm configuration via unsupervised deep graph clustering.Engi- neering Applications of Artificial Intelligence125 (2023), 106740
2023
-
[30]
Zixing Song, Xiangli Yang, Zenglin Xu, and Irwin King. 2022. Graph-based semi-supervised learning: A comprehensive review.IEEE Transactions on Neural Networks and Learning Systems34, 11 (2022), 8174–8194
2022
-
[31]
Karen Sparck Jones. 1972. A statistical interpretation of term specificity and its application in retrieval.Journal of documentation28, 1 (1972), 11–21
1972
-
[32]
2014.Graph-based semi- supervised learning
Amarnag Subramanya and Partha Pratim Talukdar. 2014.Graph-based semi- supervised learning. Morgan & Claypool Publishers
2014
- [33]
-
[34]
Jesper E Van Engelen and Holger H Hoos. 2020. A survey on semi-supervised learning.Machine learning109, 2 (2020), 373–440
2020
-
[35]
Y Shiloachand U Vishkin and Y Shiloach. 1982. An O (log n) parallel connectivity algorithm.J. algorithms3 (1982), 57–67
1982
-
[36]
Tal Wagner, Sudipto Guha, Shiva Kasiviswanathan, and Nina Mishra. 2018. Semi- supervised learning on data streams via temporal label propagation. InInterna- tional Conference on Machine Learning. PMLR, 5095–5104
2018
-
[37]
Hongwei Wang and Jure Leskovec. 2021. Combining graph convolutional neural networks and label propagation.ACM Transactions on Information Systems (TOIS) 40, 4 (2021), 1–27
2021
-
[38]
Di Wu, Shengda Zhuo, Yu Wang, Zhong Chen, and Yi He. 2023. Online semi- supervised learning with mix-typed streaming features. InProceedings of the DynLP: Parallel Dynamic Batch Update for Label Propagation in Semi-Supervised Learning (to be published in the ACM International Conference on Supercomputing (ICS 2026))ICS 2026, July 06–09, 2026, Belfast, Nor...
2023
-
[39]
Hang Yu, Jiahao Wen, Yiping Sun, Xiao Wei, and Jie Lu. 2024. CA-GNN: A competence-aware graph neural network for semi-supervised learning on stream- ing data.IEEE Transactions on Cybernetics(2024)
2024
-
[40]
Yabin Zhang, Bin Deng, Kui Jia, and Lei Zhang. 2020. Label propagation with augmented anchors: A simple semi-supervised learning baseline for unsupervised domain adaptation. InEuropean Conference on Computer Vision. Springer, 781– 797
2020
-
[41]
Dengyong Zhou, Olivier Bousquet, Thomas N Lal, Jason Weston, and Bernhard Schölkopf. 2004. Learning with local and global consistency. InAdvances in neural information processing systems. 321–328
2004
-
[42]
Xiaojin Zhu, Zoubin Ghahramani, and John D Lafferty. 2003. Semi-supervised learning using gaussian fields and harmonic functions. InProceedings of the 20th International conference on Machine learning (ICML-03). 912–919
2003
-
[43]
Xiaojin Zhu, Andrew B Goldberg, and Tushar Khot. 2009. Some new directions in graph-based semi-supervised learning. In2009 IEEE International Conference on Multimedia and Expo. IEEE, 1504–1507
2009
-
[44]
2003.Semi-supervised learning: From Gaussian fields to Gaussian processes
Xiaojin Zhu, John Lafferty, and Zoubin Ghahramani. 2003.Semi-supervised learning: From Gaussian fields to Gaussian processes. School of Computer Science, Carnegie Mellon University
2003
- [45]
-
[46]
Yong-Nan Zhu and Yu-Feng Li. 2020. Semi-supervised streaming learning with emerging new labels. InProceedings of the AAAI Conference on Artificial Intelli- gence, Vol. 34. 7015–7022
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.