Recognition: 2 theorem links
· Lean TheoremCan Drift-Adaptive Malware Detectors Be Made Robust? Attacks and Defenses Under White-Box and Black-Box Threats
Pith reviewed 2026-05-10 18:22 UTC · model grok-4.3
The pith
Fine-tuning on adversarially transformed inputs makes drift-adaptive malware detectors robust to white-box and black-box attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
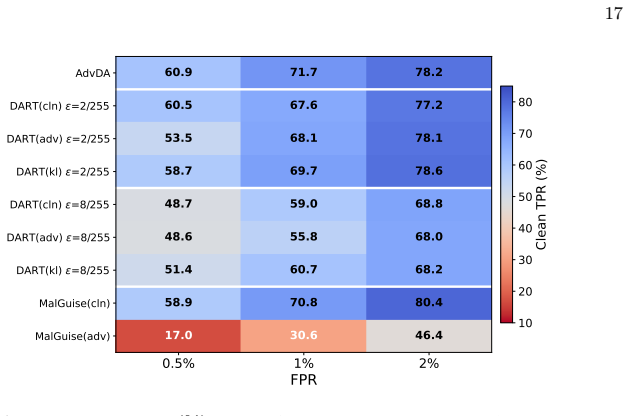
A universal robustification framework that fine-tunes pretrained AdvDA models on adversarially transformed inputs, without depending on the specific attack type, reduces PGD attack success from 100 percent to as low as 3.2 percent and MalGuise success from 13 percent to 5.1 percent across five monthly adaptation windows and three false-positive-rate points. Source adversarial training is required for effective PGD defense but proves counterproductive for MalGuise defense, where target-only training suffices, and robustness does not transfer between the two threat models.
What carries the argument
The universal robustification framework that fine-tunes a pretrained AdvDA model on adversarially transformed inputs agnostic to attack type.
If this is right
- Source adversarial training must be included when defending against white-box feature-space attacks such as PGD.
- Target-only adversarial training is sufficient and more efficient for black-box binary-modifying attacks such as MalGuise.
- Robustness acquired against one threat model provides no protection against the other, so separate evaluation is required.
- The framework supports maintaining high detection accuracy at low false-positive rates while adding robustness.
- Monthly drift adaptation can incorporate the fine-tuning step without disrupting the core domain-alignment process.
Where Pith is reading between the lines
- The same fine-tuning idea could be tried on other domain-adaptation detectors facing combined drift and evasion.
- Hybrid training that mixes source and target adversarial examples might be tested for broader coverage even though the paper shows trade-offs.
- Operational systems would need ongoing monitoring to detect when a new attack type emerges that the current defenses do not cover.
- Computational cost of the fine-tuning step could be measured against the reduction in successful evasions to guide practical adoption.
Load-bearing premise
That the five monthly adaptation windows, three false-positive-rate points, and two specific attack types tested are representative enough to support general deployment recommendations for real-world drift and threats.
What would settle it
A test set of malware samples drawn from later months or using a different evasion technique that produces attack success rates above 10 percent on the fine-tuned models would show the claimed robustness does not hold.
Figures




read the original abstract
Concept drift and adversarial evasion are two major challenges for deploying machine learning-based malware detectors. While both have been studied separately, their combination, the adversarial robustness of drift-adaptive detectors, remains unexplored. We address this problem with AdvDA, a recent malware detector that uses adversarial domain adaptation to align a labeled source domain with a target domain with limited labels. The distribution shift between domains poses a unique challenge: robustness learned on the source may not transfer to the target, and existing defenses assume a fixed distribution. To address this, we propose a universal robustification framework that fine-tunes a pretrained AdvDA model on adversarially transformed inputs, agnostic to the attack type and choice of transformations. We instantiate it with five defense variants spanning two threat models: white-box PGD attacks in the feature space and black-box MalGuise attacks that modify malware binaries via functionality-preserving control-flow mutations. Across nine defense configurations, five monthly adaptation windows on Windows malware, and three false-positive-rate operating points, we find the undefended AdvDA completely vulnerable to PGD (100% attack success) and moderately to MalGuise (13%). Our framework reduces these rates to as low as 3.2% and 5.1%, respectively, but the optimal strategy differs: source adversarial training is essential for PGD defenses yet counterproductive for MalGuise defenses, where target-only training suffices. Furthermore, robustness does not transfer across these two threat models. We provide deployment recommendations that balance robustness, detection accuracy, and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the intersection of concept drift and adversarial evasion in ML-based malware detectors. It builds on AdvDA, a drift-adaptive detector using adversarial domain adaptation to align labeled source and sparsely labeled target domains. The authors introduce a universal robustification framework that fine-tunes a pretrained AdvDA model on adversarially transformed inputs, independent of attack type. They instantiate nine defense variants under white-box PGD attacks (feature space) and black-box MalGuise attacks (binary control-flow mutations). Experiments over five monthly adaptation windows on Windows malware and three FPR operating points show undefended AdvDA achieves 100% PGD success and 13% MalGuise success; the framework reduces these to 3.2% and 5.1%. Optimal strategies differ by threat model (source adversarial training essential for PGD, counterproductive for MalGuise where target-only suffices), robustness does not transfer across models, and deployment recommendations balancing robustness, accuracy, and cost are offered.
Significance. If the empirical findings hold under broader conditions, the work is significant for addressing an underexplored combination of challenges in real-world malware detection. It provides concrete attack success reductions and differential defense insights that could inform practical deployment of adaptive detectors. Credit is due for the multi-window temporal evaluation on actual Windows malware and the explicit comparison of white-box versus black-box threat models within a single framework.
major comments (1)
- [§5] §5 (Experimental Evaluation) and associated tables/figures: The central claims that optimal strategies differ by threat model (source adversarial training essential for PGD defenses but counterproductive for MalGuise, where target-only suffices) and that robustness does not transfer are derived exclusively from five monthly adaptation windows, two attack instantiations (PGD and MalGuise), and three FPR points. This narrow scope directly supports the deployment recommendations yet leaves open whether the relative value of source vs. target training or the non-transfer result would hold under additional drifts, malware families, or attack formulations; expanding the evaluation or adding explicit sensitivity analysis is needed to ground the recommendations.
minor comments (2)
- [Abstract and §4] The description of the universal framework as 'agnostic to the attack type' (Abstract and §4) could be clarified, as the instantiations remain specific to PGD and MalGuise transformations; a brief discussion of how the fine-tuning procedure would extend to other attacks would strengthen the universality claim.
- [§4] Notation for the five defense variants and nine configurations is introduced without an explicit summary table; adding a compact table listing each variant's training data source (source/target), attack type, and hyperparameters would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Evaluation) and associated tables/figures: The central claims that optimal strategies differ by threat model (source adversarial training essential for PGD defenses but counterproductive for MalGuise, where target-only suffices) and that robustness does not transfer are derived exclusively from five monthly adaptation windows, two attack instantiations (PGD and MalGuise), and three FPR points. This narrow scope directly supports the deployment recommendations yet leaves open whether the relative value of source vs. target training or the non-transfer result would hold under additional drifts, malware families, or attack formulations; expanding the evaluation or adding explicit sensitivity analysis is needed to ground the recommendations.
Authors: We acknowledge that the reported findings rest on five consecutive monthly adaptation windows drawn from real Windows malware, two representative attacks (white-box PGD in feature space and black-box MalGuise via control-flow mutations), and three FPR operating points. This scope already exceeds the single-snapshot or synthetic evaluations common in the malware robustness literature and captures temporal drift in a production-like setting. Nevertheless, we agree that stronger grounding for the differential value of source versus target adversarial training and the observed non-transferability would benefit from additional analysis. In the revision we will add a dedicated sensitivity-analysis subsection to §5. It will (i) quantify how attack success rates vary with drift magnitude across the five windows, (ii) report results on a held-out malware family subset, and (iii) discuss expected behavior under alternative attack formulations (e.g., other gradient or query-based methods). We will also expand the limitations paragraph to explicitly caveat generalizability. A full re-run of all nine defense variants over additional windows or families is not feasible within reasonable compute and labeling budgets, but the proposed sensitivity discussion directly addresses the referee’s request for grounding the deployment recommendations. revision: partial
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper advances an empirical framework (AdvDA robustification) and reports attack success rates, optimal training strategies, and non-transfer of robustness directly from experiments on five monthly Windows malware adaptation windows, two specific attacks (PGD and MalGuise), and three FPR points. No mathematical derivations, fitted parameters presented as independent predictions, self-definitional constructs, or load-bearing self-citation chains appear in the abstract or described approach. All central claims reduce to measured outcomes on the chosen data and threat models rather than to any input by construction, satisfying the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a universal robustification framework for AdvDA that is agnostic to the attack type and the choice of input transformations, and instantiate it with five defense variants across two threat models.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
source adversarial training is essential for PGD defenses yet counterproductive for MalGuise defenses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://bazaar.abuse.ch/api/ (2025), online; ac- cessed 29-May-2025
Abuse.ch: MalwareBazaar API. https://bazaar.abuse.ch/api/ (2025), online; ac- cessed 29-May-2025
2025
-
[2]
In: International Conference on Web Information Systems Engineering
Abusnaina, A., Anwar, A., Saad, M., Alabduljabbar, A., Jang, R., Salem, S., Mo- haisen, D.: Exposing the limitations of machine learning for malware detection under concept drift. In: International Conference on Web Information Systems Engineering. pp. 273–289. Springer (2025)
2025
-
[3]
In: 2022 IEEE Symposium on Security and Privacy (SP)
Barbero, F., Pendlebury, F., Pierazzi, F., Cavallaro, L.: Transcending transcend: Revisiting malware classification in the presence of concept drift. In: 2022 IEEE Symposium on Security and Privacy (SP). pp. 805–823. IEEE (2022)
2022
-
[4]
Computers & Security148, 104122 (2025)
Botacin, M., Gomes, H.: Towards more realistic evaluations: The impact of label delays in malware detection pipelines. Computers & Security148, 104122 (2025)
2025
-
[5]
Digital Threats: Research and Practice5(1), 1–32 (2024)
Ceschin, F., Botacin, M., Bifet, A., Pfahringer, B., Oliveira, L.S., Gomes, H.M., Grégio, A.: Machine learning (in) security: A stream of problems. Digital Threats: Research and Practice5(1), 1–32 (2024)
2024
-
[6]
Expert Systems with Applications212, 118590 (2023)
Ceschin, F., Botacin, M., Gomes, H.M., Pinagé, F., Oliveira, L.S., Grégio, A.: Fast & furious: On the modelling of malware detection as an evolving data stream. Expert Systems with Applications212, 118590 (2023)
2023
-
[7]
Adversarial Attacks and Defences: A Survey
Chakraborty, A., Alam, M., Dey, V., Chattopadhyay, A., Mukhopadhyay, D.: Ad- versarial attacks and defences: A survey. arXiv preprint arXiv:1810.00069 (2018)
work page Pith review arXiv 2018
-
[8]
In: 32nd USENIX Security Symposium (USENIX Security 23)
Chen, Y., Ding, Z., Wagner, D.: Continuous learning for android malware detec- tion. In: 32nd USENIX Security Symposium (USENIX Security 23). pp. 1127–1144 (2023)
2023
-
[9]
In: International Conference on Detection of Intrusions and Malware, and Vulner- ability Assessment
Digregorio,G.,Maccarrone,S.,D’Onghia,M.,Gallo,L.,Carminati,M.,Polino,M., Zanero, S.: Tarallo: Evading behavioral malware detectors in the problem space. In: International Conference on Detection of Intrusions and Malware, and Vulner- ability Assessment. pp. 128–149. Springer (2024)
2024
-
[10]
In: Proceedings of the 16th ACM Workshop on Artificial Intelli- gence and Security
D’Onghia, M., Di Cesare, F., Gallo, L., Carminati, M., Polino, M., Zanero, S.: Lookin’out my backdoor! investigating backdooring attacks against dl-driven mal- ware detectors. In: Proceedings of the 16th ACM Workshop on Artificial Intelli- gence and Security. pp. 209–220 (2023)
2023
-
[11]
IEEE Transactions on Information Forensics and Security15, 2750–2765 (2020)
D’Elia, D.C., Coppa, E., Palmaro, F., Cavallaro, L.: On the dissection of evasive malware. IEEE Transactions on Information Forensics and Security15, 2750–2765 (2020)
2020
-
[12]
Computers & security113, 102550 (2022)
Galloro, N., Polino, M., Carminati, M., Continella, A., Zanero, S.: A systematical and longitudinal study of evasive behaviors in windows malware. Computers & security113, 102550 (2022)
2022
-
[13]
Explaining and Harnessing Adversarial Examples
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
work page internal anchor Pith review arXiv 2014
-
[14]
In: NDSS (2023)
Han, D., Wang, Z., Chen, W., Wang, K., Yu, R., Wang, S., Zhang, H., Wang, Z., Jin, M., Yang, J., et al.: Anomaly detection in the open world: Normality shift detection, explanation, and adaptation. In: NDSS (2023)
2023
-
[15]
In: Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security
He, Y., Lei, J., Qin, Z., Ren, K., Chen, C.: Combating concept drift with explana- tory detection and adaptation for android malware classification. In: Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. pp. 978–992 (2025) 22
2025
-
[16]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Hendrycks,D.,Dietterich,T.:Benchmarkingneuralnetworkrobustnesstocommon corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019)
work page internal anchor Pith review arXiv 1903
-
[17]
In: 26th USENIX security symposium (USENIX security 17)
Jordaney, R., Sharad, K., Dash, S.K., Wang, Z., Papini, D., Nouretdinov, I., Cav- allaro, L.: Transcend: Detecting concept drift in malware classification models. In: 26th USENIX security symposium (USENIX security 17). pp. 625–642 (2017)
2017
-
[18]
In: Proc
Kreuk, F., Barak, A., Aviv-Reuven, S., Baruch, M., Pinkas, B., Keshet, J.: Adver- sarial examples on discrete sequences for beating whole-binary malware detection. In: Proc. NeurIPSW (2018)
2018
-
[19]
arXiv preprint arXiv:2511.14963 (2025)
Li, A.S., Bertino, E.: Lfreeda: Label-free drift adaptation for windows malware detection. arXiv preprint arXiv:2511.14963 (2025)
-
[20]
Net- work and Distributed System Security (NDSS) Symposium (2025)
Li, A.S., Iyengar, A., Kundu, A., Bertino, E.: Revisiting concept drift in windows malware detection: Adaptation to real drifted malware with minimal samples. Net- work and Distributed System Security (NDSS) Symposium (2025)
2025
-
[21]
In: 33rd USENIX Security Symposium (USENIX Security 24)
Ling, X., Wu, Z., Wang, B., Deng, W., Wu, J., Ji, S., Luo, T., Wu, Y.: A wolf in sheep’s clothing: Practical black-box adversarial attacks for evading learning-based windows malware detection in the wild. In: 33rd USENIX Security Symposium (USENIX Security 24). pp. 7393–7410. USENIX Association (2024)
2024
-
[22]
In: Proceedings of the Asian Conference on Computer Vision
Lo, S.Y., Patel, V.: Exploring adversarially robust training for unsupervised do- main adaptation. In: Proceedings of the Asian Conference on Computer Vision. pp. 4093–4109 (2022)
2022
-
[23]
In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security
Lucas, K., Lin, W., Bauer, L., Reiter, M.K., Sharif, M.: Training robust ml-based raw-binary malware detectors in hours, not months. In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. pp. 124–138 (2024)
2024
-
[24]
In: 32nd USENIX Security Symposium (USENIX Security 23)
Lucas, K., Pai, S., Lin, W., Bauer, L., Reiter, M.K., Sharif, M.: Adversarial train- ing for{Raw-Binary}malware classifiers. In: 32nd USENIX Security Symposium (USENIX Security 23). pp. 1163–1180 (2023)
2023
-
[25]
In: Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security
Lucas, K., Sharif, M., Bauer, L., Reiter, M.K., Shintre, S.: Malware makeover: Breaking ml-based static analysis by modifying executable bytes. In: Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security. pp. 744–758 (2021)
2021
-
[26]
In: Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering
Ma, Y., Liu, S., Jiang, J., Chen, G., Li, K.: A comprehensive study on learning- based pe malware family classification methods. In: Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. pp. 1314–1325 (2021)
2021
-
[27]
Towards Deep Learning Models Resistant to Adversarial Attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017)
work page internal anchor Pith review arXiv 2017
-
[28]
In: 28th USENIX security symposium (USENIX Security 19)
Pendlebury, F., Pierazzi, F., Jordaney, R., Kinder, J., Cavallaro, L.: {TESSERACT}: Eliminating experimental bias in malware classification across space and time. In: 28th USENIX security symposium (USENIX Security 19). pp. 729–746 (2019)
2019
-
[29]
Engineering (2020)
Ren, K., Zheng, T., Qin, Z., Liu, X.: Adversarial attacks and defenses in deep learning. Engineering (2020)
2020
-
[30]
Intriguing properties of neural networks
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fer- gus, R.: Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013)
work page internal anchor Pith review arXiv 2013
-
[31]
In: International Confer- ence on Detection of Intrusions and Malware, and Vulnerability Assessment
Tripathi, J., Gomes, H., Botacin, M.: Towards explainable drift detection and early retrain in ml-based malware detection pipelines. In: International Confer- ence on Detection of Intrusions and Malware, and Vulnerability Assessment. pp. 3–24. Springer (2025) 23
2025
-
[32]
https://github.com/google-research/ domain-robust (2025), our DART implementation is based on this codebase
Wang, H., Ge, S., Xing, E.P., Lipton, Z.C.: Domainrobust: A testbed for ad- versarial robustness of domain adaptation. https://github.com/google-research/ domain-robust (2025), our DART implementation is based on this codebase
2025
-
[33]
In: 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML)
Wang, Y., Hazimeh, H., Ponomareva, N., Kurakin, A., Hammoud, I., Arora, R.: Dart: A principled approach to adversarially robust unsupervised domain adap- tation. In: 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). pp. 773–796. IEEE (2025)
2025
-
[34]
Yang, L., Guo, W., Hao, Q., Ciptadi, A., Ahmadzadeh, A., Xing, X., Wang, G.: {CADE}: Detecting and explaining concept drift samples for security applica- tions.In:30thUSENIXSecuritySymposium(USENIXSecurity21).pp.2327–2344 (2021)
2021
-
[35]
IEEE Transactions on Dependable and Secure Computing20(2), 1390–1402 (2022)
Zhang, L., Liu, P., Choi, Y.H., Chen, P.: Semantics-preserving reinforcement learn- ing attack against graph neural networks for malware detection. IEEE Transactions on Dependable and Secure Computing20(2), 1390–1402 (2022)
2022
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhu, W., Yin, J.L., Chen, B.H., Liu, X.: Srouda: meta self-training for robust unsu- pervised domain adaptation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 3852–3860 (2023) A Additional Tables Table 5:Malware-to-benign ratios per testing month. Test Month Source Tr./Te. Target Train Target Test 08/2024 0.6:1 0.5:1 0.6:...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.