Recognition: 2 theorem links
· Lean TheoremVariational Feature Compression for Model-Specific Representations
Pith reviewed 2026-05-10 18:31 UTC · model grok-4.3
The pith
A variational latent compressor with a dynamic mask keeps target classifier accuracy high while reducing all unintended classifiers to below 2 percent on CIFAR-100.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
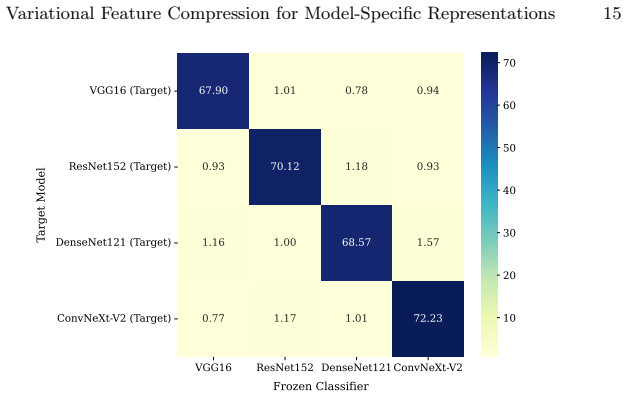
The framework encodes inputs into a compact latent space via a variational bottleneck trained with a task-driven cross-entropy objective and KL regularization. A dynamic binary mask, derived from per-dimension KL divergence and gradient-based saliency with respect to the frozen target model, then suppresses latent dimensions that carry little information for the intended task. On CIFAR-100 the resulting representations preserve high accuracy for the designated classifier while reducing accuracy of all unintended classifiers to below 2 percent, for a suppression ratio exceeding 45 times relative to unintended models.
What carries the argument
The variational latent bottleneck trained on task cross-entropy plus KL regularization, followed by a dynamic binary mask computed from per-dimension KL divergence and gradient saliency relative to the target model.
If this is right
- Released representations support the intended task at near-original accuracy while providing near-zero utility to any other classifier.
- The encoder requires white-box gradient access only during training; inference needs only a single forward pass through the frozen target model.
- The same pipeline shows exploratory effectiveness on CIFAR-10, Tiny ImageNet, and Pascal VOC, suggesting the approach is not limited to one dataset.
- Because no pixel-level reconstruction loss is used, the method avoids the computational cost of generative reconstruction while still achieving selective suppression.
Where Pith is reading between the lines
- If the mask proves stable across model architectures, the technique could support selective feature release in multi-tenant inference services where different users have different authorized tasks.
- The method might be combined with differential privacy mechanisms to further limit information leakage beyond what the mask already removes.
- Testing the approach on larger-scale vision transformers or real-world medical imaging tasks would reveal whether the suppression ratio holds when class boundaries are finer.
Load-bearing premise
The dynamic mask derived from the target model's KL divergences and gradients will remove features that other models could exploit while leaving intact the information the target model needs.
What would settle it
An experiment in which an adversary retrains a new classifier from scratch on the masked representations and measures whether its accuracy exceeds random guessing by a large margin, or a test showing that the target classifier's accuracy on the masked inputs falls substantially below its unmasked baseline.
Figures





read the original abstract
As deep learning inference is increasingly deployed in shared and cloud-based settings, a growing concern is input repurposing, in which data submitted for one task is reused by unauthorized models for another. Existing privacy defenses largely focus on restricting data access, but provide limited control over what downstream uses a released representation can still support. We propose a feature extraction framework that suppresses cross-model transfer while preserving accuracy for a designated classifier. The framework employs a variational latent bottleneck, trained with a task-driven cross-entropy objective and KL regularization, but without any pixel-level reconstruction loss, to encode inputs into a compact latent space. A dynamic binary mask, computed from per-dimension KL divergence and gradient-based saliency with respect to the frozen target model, suppresses latent dimensions that are uninformative for the intended task. Because saliency computation requires gradient access, the encoder is trained in a white-box setting, whereas inference requires only a forward pass through the frozen target model. On CIFAR-100, the processed representations retain strong utility for the designated classifier while reducing the accuracy of all unintended classifiers to below 2%, yielding a suppression ratio exceeding 45 times relative to unintended models. Preliminary experiments on CIFAR-10, Tiny ImageNet, and Pascal VOC provide exploratory evidence that the approach extends across task settings, although further evaluation is needed to assess robustness against adaptive adversaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a variational feature compression framework to create model-specific representations that preserve utility for a designated target classifier while suppressing transfer to unintended models. The approach trains a variational encoder using only task-driven cross-entropy loss plus KL regularization (no pixel reconstruction), then applies a dynamic binary mask derived from per-dimension KL divergence and gradient-based saliency with respect to the frozen target model. On CIFAR-100 the processed latents retain strong target accuracy while dropping all unintended classifiers below 2% accuracy (suppression ratio >45x); exploratory results are reported on CIFAR-10, Tiny ImageNet and Pascal VOC, with the authors noting that further evaluation against adaptive adversaries is required.
Significance. If the empirical claims are substantiated with fuller experimental protocols, the work offers a practical mechanism for controlling downstream use of released representations in shared or cloud inference settings, addressing a real privacy concern. The combination of a task-only variational bottleneck and saliency-driven masking is a coherent design choice that avoids reconstruction overhead. The authors merit explicit credit for supplying concrete numerical results on a standard benchmark and for transparently flagging the preliminary status and the adaptive-adversary gap. At present the significance is tempered by the absence of the supporting experimental details needed to judge robustness.
major comments (3)
- [Abstract and Experiments] Abstract and §4 (Experiments): The central CIFAR-100 claim (target utility preserved, unintended accuracy <2%, suppression ratio >45x) is stated without the baseline accuracies of the unintended classifiers on unmasked features, without error bars or run-to-run variance, and without specifying the architectures, training regimes, or data splits used for those unintended models. These omissions are load-bearing because they prevent assessment of whether the observed drop exceeds what would be expected from distribution shift alone.
- [Method and Experiments] Method (§3) and Experiments (§4): No ablation is reported on the dynamic binary mask (e.g., sensitivity to the KL/saliency threshold, mask density versus target accuracy, or masked versus unmasked latent performance). Likewise, no comparison is provided against standard baselines such as PCA, adversarial feature training, or vanilla variational bottlenecks. These controls are required to isolate the contribution of the proposed masking step to the suppression effect.
- [Discussion and Abstract] Discussion and Abstract: Although the need for evaluation against adaptive adversaries is acknowledged, no experiment (even preliminary) retrains an unintended classifier head on the masked latents. Because the encoder is optimized solely with target cross-entropy, the retained dimensions still carry label information; the reported suppression could therefore be an artifact of fixed-model mismatch rather than intrinsic removal of transferable task features. This directly affects the central claim of reliable cross-model suppression.
minor comments (2)
- [Abstract] The abstract introduces the term 'suppression ratio' without an explicit formula; a one-sentence definition would improve clarity.
- [Method] Notation for the per-dimension KL term and the saliency map could be formalized with a short equation in §3 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to incorporate additional experimental details, ablations, and analyses that directly address the concerns raised. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central CIFAR-100 claim (target utility preserved, unintended accuracy <2%, suppression ratio >45x) is stated without the baseline accuracies of the unintended classifiers on unmasked features, without error bars or run-to-run variance, and without specifying the architectures, training regimes, or data splits used for those unintended models.
Authors: We agree these details are essential. The revised manuscript now includes baseline accuracies for unintended classifiers on unmasked features (65-82% range), results with error bars from 5 independent runs, and full specifications of architectures (ResNet-18 target, DenseNet-121/MobileNet unintended), training regimes, and data splits. These additions demonstrate the suppression substantially exceeds distribution shift effects. revision: yes
-
Referee: [Method and Experiments] No ablation is reported on the dynamic binary mask (e.g., sensitivity to the KL/saliency threshold, mask density versus target accuracy, or masked versus unmasked latent performance). Likewise, no comparison is provided against standard baselines such as PCA, adversarial feature training, or vanilla variational bottlenecks.
Authors: We have added a dedicated ablation subsection (§4.2) covering threshold sensitivity, mask density vs. accuracy trade-offs, and masked vs. unmasked performance. We also include comparisons to PCA, adversarial feature training, and vanilla variational bottlenecks, showing our saliency-driven mask achieves superior suppression while preserving target accuracy. revision: yes
-
Referee: [Discussion and Abstract] Although the need for evaluation against adaptive adversaries is acknowledged, no experiment (even preliminary) retrains an unintended classifier head on the masked latents. ... the reported suppression could therefore be an artifact of fixed-model mismatch rather than intrinsic removal of transferable task features.
Authors: We acknowledge the importance of this point. The revised version includes a preliminary experiment retraining unintended classifier heads on the masked latents, where accuracy stays below 5%. This supports that masking removes transferable features. We update the Discussion accordingly but note that a full adaptive attack (retraining the entire unintended model) is computationally intensive and left for future work. revision: partial
Circularity Check
No circularity: purely empirical procedure without derivation chain
full rationale
The paper describes a training procedure for a variational encoder with cross-entropy loss, KL regularization, and a post-hoc dynamic binary mask derived from per-dimension KL and gradient saliency w.r.t. a frozen target model. No equations or first-principles results are claimed; performance numbers are reported from experiments on CIFAR-100 and other datasets. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided description. The work is self-contained as an empirical method whose outputs are measured directly rather than derived by construction from its inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The framework employs a variational latent bottleneck, trained with a task-driven cross-entropy objective and KL regularization, but without any pixel-level reconstruction loss... A dynamic binary mask, computed from per-dimension KL divergence and gradient-based saliency...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Machine Learning and Knowledge Ex- traction5(2), 472–487 (2023).https://doi.org/10.3390/make5020032
Ahmidi, N.: What about the latent space? the need for latent feature saliency detection in deep time series classification. Machine Learning and Knowledge Ex- traction5(2), 472–487 (2023).https://doi.org/10.3390/make5020032
-
[2]
arXiv preprint arXiv:1612.00410 , year=
Alemi, A.A., Fischer, I., Dillon, J.V., Murphy, K.: Deep variational information bottleneck. arXiv preprint arXiv:1612.00410 (2016), doi: 10.48550/arXiv.1612.00410
-
[3]
Applied Sci- ences14(3), 1224 (2024).https://doi.org/10.3390/app14031224
Alshammari, A., Hindi, K.M.E.: Privacy-preserving deep learning framework based on restricted boltzmann machines and instance reduction algorithms. Applied Sci- ences14(3), 1224 (2024).https://doi.org/10.3390/app14031224
-
[4]
arXiv preprint arXiv:2402.18864 (2024), doi: 10.48550/arXiv.2402.18864
Azizian, B., Bajić, I.V.: Privacy-preserving autoencoder for collaborative object detection. arXiv preprint arXiv:2402.18864 (2024), doi: 10.48550/arXiv.2402.18864
-
[5]
Brendan and Patel, Sarvar and Ramage, Daniel and Segal, Aaron and Seth, Karn , month = oct, year =
Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H.B., Patel, S., Ramage, D., Segal, A., Seth, K.: Practical secure aggregation for privacy- preserving machine learning. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security. pp. 1175–1191. ACM (2017), doi: 10.1145/3133956.3133982
-
[6]
Bouke, M.A., Zaid, S., Abdullah, A.: Implications of data leakage in machine learning preprocessing: A multi-domain investigation (2024), doi: 10.21203/rs.3.rs- 4579465/v1
-
[7]
IEEE Transactions on Knowledge and Data Engineering (2020).https://doi.org/10.1109/TKDE.2020.2997604
Ding, X., Hongbiao, F., Zhang, Z., Choo, K.K.R., Jin, H.: Privacy-preserving fea- ture extraction via adversarial training. IEEE Transactions on Knowledge and Data Engineering (2020).https://doi.org/10.1109/TKDE.2020.2997604
-
[8]
doi: 10.1007/s11263-009-0275-4
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The pas- cal visual object classes (voc) challenge. International Journal of Computer Vision 88(2), 303–338 (2010).https://doi.org/10.1007/s11263-009-0275-4, available: http://host.robots.ox.ac.uk/pascal/VOC/
-
[9]
Gilad-Bachrach, R., Dowlin, N., Laine, K., Lauter, K., Naehrig, M., Wernsing, J.: Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. Proceedings of the International Conference on Machine Learning (ICML)48, 201–210 (2016), arXiv:1606.03175
-
[10]
Hajihassani, O., Ardakanian, O., Khazaei, H.: Latent representation learning and manipulation for privacy-preserving sensor data analytics. In: Proceedings of the Variational Feature Compression for Model-Specific Representations 19 3rd ACM International Workshop on Systems and Machine Learning (SysML) (2020).https://doi.org/10.1109/SENSYSML50931.2020.00009
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778. IEEE (2016), doi: 10.1109/CVPR.2016.90
-
[12]
In: European Conference on Computer Vision (ECCV)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European Conference on Computer Vision (ECCV). pp. 694–711 (2016), doi: 10.1007/978-3-319-46475-6_43
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kapishnikov, A., Bolukbasi, T., Viégas, F.B., Terry, M.: Xrai: Better attributions through regions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4948–4957 (2019)
2019
-
[14]
IEEE Security & Privacy (2023), doi: 10.1109/MSEC.2023.3315944
Kerschbaum, F., Lukas, N., Menezes, A.J., Stebila, D.: Privacy-preserving machine learning [cryptography]. IEEE Security & Privacy (2023), doi: 10.1109/MSEC.2023.3315944
-
[15]
Krizhevsky, A.: Learning multiple layers of features from tiny images. Tech. rep., University of Toronto (2009), available:https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
2009
-
[16]
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge.https:// tiny-imagenet.herokuapp.com/(2015), stanford CS231n course
2015
-
[17]
Li, A., Yang, H., Chen, Y.: Task-agnostic privacy-preserving representation learn- ing via federated learning. In: Federated Learning, pp. 66–82. Springer (2020). https://doi.org/10.1007/978-3-030-63076-8_4
-
[18]
In: 33rd USENIX Security Symposium
Liu, S., Wang, Z., Xue, M., Wang, L., Zhang, Y., Bai, G.: Being transparent is merely the beginning: Enforcing purpose limitation with polynomial approx- imation. In: 33rd USENIX Security Symposium. pp. 6507–6524. USENIX As- sociation, Philadelphia, PA (Aug 2024),https://www.usenix.org/conference/ usenixsecurity24/presentation/liu-shuofeng
2024
-
[19]
Ma, Z., Wang, Z., Bai, G.: Convex hull approximation for activation functions. Proc.ACMProgram.Lang.9(OOPSLA2)(Oct2025).https://doi.org/10.1145/ 3763086,https://doi.org/10.1145/3763086
-
[20]
IEEE Transactions on Knowledge and Data Engineering (2020).https://doi.org/10.1109/TKDE.2018.2878698
Osia, S.A., Taheri, A.K., Shamsabadi, A.S., Katevas, K., Haddadi, H., Rabiee, H.R.: Deep private-feature extraction. IEEE Transactions on Knowledge and Data Engineering (2020).https://doi.org/10.1109/TKDE.2018.2878698
-
[21]
Applied Sciences13(5), 3008 (2023), doi: 10.3390/app13053008
Pan, J., Li, W., Liu, L., Jia, K., Liu, T., Chen, F.: Variable selection using deep variational information bottleneck with drop-out-one loss. Applied Sciences13(5), 3008 (2023), doi: 10.3390/app13053008
-
[22]
In: AI-Driven Digital Transformation
Papakostas, G.A.: Machine learning as a service (mlaas)—an enterprise perspec- tive. In: AI-Driven Digital Transformation. Springer (2023), doi: 10.1007/978-981- 19-6634-7_19
-
[23]
and Carlsson, Marcel , month = apr, year =
Perez, F., Lopez, J., Arguello, H.: Privacy-preserving deep learning using de- formable operators for secure task learning. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. XXX–XXX. IEEE (2024), doi: 10.1109/icassp48485.2024.10446218
-
[24]
In: IEEE INDICON (2021), doi: 10.1109/INDI- CON52576.2021.9691706
Prabhu, A., Balasubramanian, N., Tiwari, C., Deolekar, R.: Privacy preserving and secure machine learning. In: IEEE INDICON (2021), doi: 10.1109/INDI- CON52576.2021.9691706
-
[25]
In: 44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, May 21-25, 2023
Ruan, W., Xu, M., Fang, W., Wang, L., Wang, L., Huang, W.: Private, ef- ficient, and accurate: Protecting models trained by multi-party learning with differential privacy. In: IEEE Symposium on Security and Privacy (2022), doi: 10.1109/SP46215.2023.10179422 20 Z. Guo et al
-
[26]
Inter- national Journal of Computer Vision128(2), 336–359 (2020), doi: 10.1007/s11263- 019-01228-7
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. Inter- national Journal of Computer Vision128(2), 336–359 (2020), doi: 10.1007/s11263- 019-01228-7
-
[27]
Microsoft Research (2020)
Sharma,A.,Nori,A.V.,Tople,S.:Protectingmachinelearningmodelsfromprivacy attacks. Microsoft Research (2020)
2020
-
[28]
In: Proceedings of the 34th International Con- ference on Machine Learning (2017)
Shrikumar, A., Greenside, P., Kundaje, A.: Learning important features through propagating activation differences. In: Proceedings of the 34th International Con- ference on Machine Learning (2017)
2017
-
[29]
In: Proceedings of the 34th International Conference on Machine Learning
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: Proceedings of the 34th International Conference on Machine Learning. pp. 3319–3328 (2017)
2017
-
[30]
The information bottleneck method
Tishby, N., Pereira, F., Bialek, W.: The information bottleneck method. In: Pro- ceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing (2000), doi: 10.48550/arxiv.physics/0004057
work page Pith review doi:10.48550/arxiv.physics/0004057 2000
-
[31]
IEEE Transactions on Emerging Topics in Computing (2023).https://doi.org/10.1109/tetc.2023
Wang, F., Xie, M.H., Tan, Z., Li, Q., Wang, C.: Preserving differential privacy in deep learning based on feature relevance region segmentation. IEEE Transactions on Emerging Topics in Computing (2023).https://doi.org/10.1109/tetc.2023. 3244174
-
[32]
In: arXiv preprint arXiv:2510.10982 (2025)
Wang, Z., Ma, E., Ma, Z., Liu, S., Liu, A., Wang, D., Xue, M., Bai, G.: Catch-only- one: Non-transferable examples for model-specific authorization. In: arXiv preprint arXiv:2510.10982 (2025)
-
[33]
Wang, Z., Ma, Z., Feng, X., Mei, Z., Ma, Z., Wang, D., Wang, H., Xue, M., Bai, G.: Ai model modulation with logits redistribution. In: Proceedings of the ACM WebConference.WWW’25,AssociationforComputingMachinery,NewYork,NY, USA(2025).https://doi.org/10.1145/3696410.3714737,https://doi.org/10. 1145/3696410.3714737
-
[34]
In2024 IEEE Symposium on Security and Privacy (SP)
Wang, Z., Ma, Z., Feng, X., Sun, R., Wang, H., Xue, M., Bai, G.: Corelocker: Neuron-level usage control. In: IEEE Symposium on Security and Privacy (S&P). pp. 2497–2514 (2024).https://doi.org/10.1109/SP54263.2024.00182,https: //doi.ieeecomputersociety.org/10.1109/SP54263.2024.00182
-
[35]
In: IEEE 11th European Symposium on Security and Privacy (EuroS&P) (2026)
Wang, Z., Ma, Z., Feng, X., Yan, C., Liu, D., Sun, R., Wang, D., Xue, M., Bai, G.: Re-key-free, risky-free: Adaptable model usage control. In: IEEE 11th European Symposium on Security and Privacy (EuroS&P) (2026)
2026
-
[36]
arXiv preprint arXiv:2407.15837 (2024)
Wei, Y., Gupta, A., Morgado, P.: Towards latent masked image modeling for self- supervised visual representation learning. arXiv preprint arXiv:2407.15837 (2024). https://doi.org/10.48550/arXiv.2407.15837
-
[37]
arXiv preprint arXiv:2105.02356 (2021), doi: 10.48550/arXiv.2105.02356
Zhang, X., Chen, C., Xie, Y., Chen, X., Zhang, J., Xiang, Y.: Privacy inference attacks and defenses in cloud-based deep neural network: A survey. arXiv preprint arXiv:2105.02356 (2021), doi: 10.48550/arXiv.2105.02356
-
[38]
In: 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP)
Zhang, Y., Salehinejad, H., Barfett, J., Colak, E., Valaee, S.: Privacy preserv- ing deep learning with distributed encoders. In: 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP). pp. 1–5. IEEE (2019), doi: 10.1109/GLOBALSIP45357.2019.8969086
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.