Recognition: 2 theorem links
· Lean TheoremFoundry: Template-Based CUDA Graph Context Materialization for Fast LLM Serving Cold Start
Pith reviewed 2026-05-10 18:18 UTC · model grok-4.3
The pith
Foundry materializes CUDA graph contexts from offline templates to cut LLM cold-start latency by up to 99 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
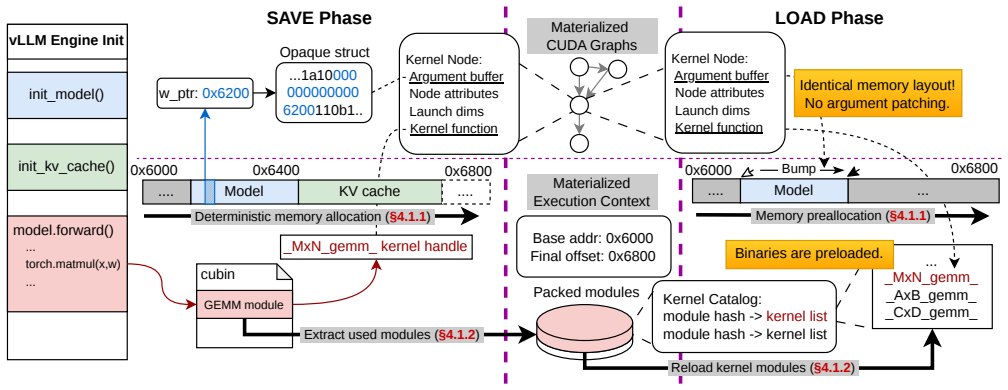
Foundry is a template-based CUDA graph context materialization system that persists both graph topology and execution context during an offline processing stage, and reconstructs executable graphs online with negligible overhead. It enforces deterministic memory layouts, automatically extracts and reloads kernel binaries required by captured graphs, and reduces online reconstruction costs through topology-based templating. For distributed serving, Foundry further enables a single-GPU offline capture to generate templates for multi-GPU deployments by patching only rank-dependent communication state. Across dense and MoE models up to 235B parameters, this reduces cold-start latency by up to 99
What carries the argument
template-based CUDA graph context materialization, which persists graph topology together with execution context such as device addresses and kernel binaries for fast deterministic online reconstruction
If this is right
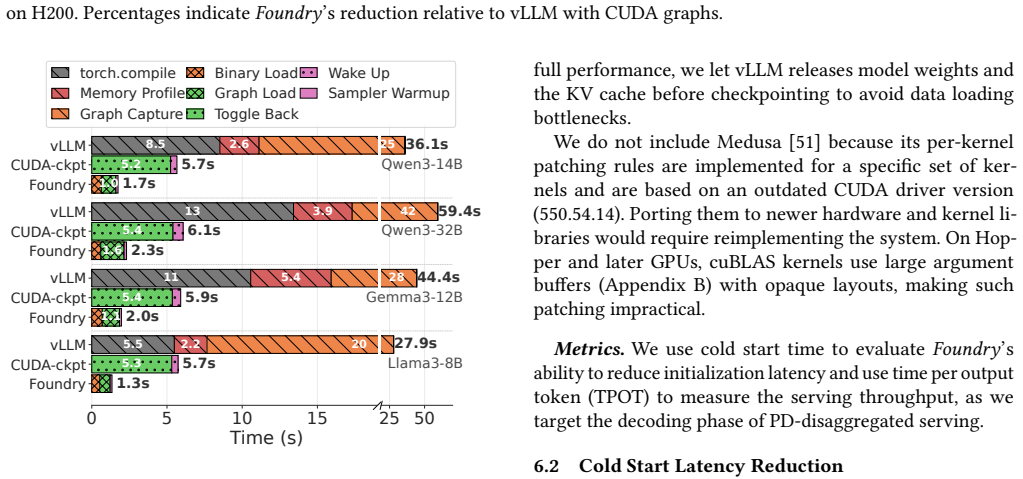
- Cold-start times for models up to 235B parameters fall from minutes to a few seconds, as seen with Qwen3-235B-A22B dropping to 3.9 seconds.
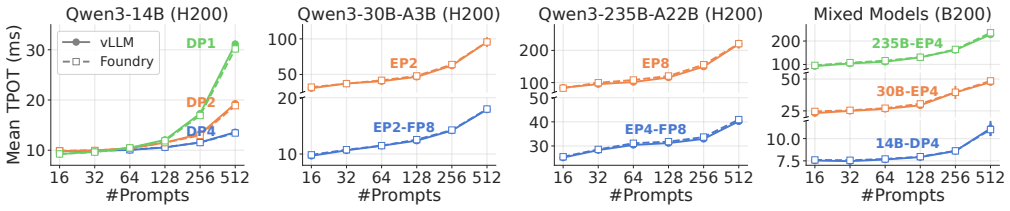
- CUDA graph throughput gains remain available immediately upon startup instead of after a long capture phase.
- Dynamic parallelism reconfiguration becomes practical during autoscaling without relying on brittle kernel patches or full process checkpoints.
- Single-GPU offline capture can supply templates for multi-GPU distributed deployments after only rank-dependent state patching.
Where Pith is reading between the lines
- The separation of offline capture from online use could make frequent model or cluster reconfiguration feasible in production LLM fleets where cold starts previously limited scaling frequency.
- Because templates encode deterministic layouts, similar materialization techniques might apply to other graph-based GPU runtimes when context dependencies are the main startup cost.
- Measuring reconstruction success rates across hardware generations would provide a direct test of whether the approach remains robust as GPU architectures evolve.
Load-bearing premise
Offline-captured templates can be reliably reconstructed online with negligible overhead across dynamic parallelism switches and distributed multi-GPU deployments without introducing brittleness or correctness issues.
What would settle it
A reconstruction that takes more than a few seconds, crashes, or produces incorrect outputs when the number of GPUs or the parallelism degree differs from the original capture would show the approach does not deliver reliable negligible-overhead materialization.
Figures







read the original abstract
Modern LLM service providers increasingly rely on autoscaling and parallelism reconfiguration to respond to rapidly changing workloads, but cold-start latency remains a major bottleneck. While recent systems have reduced model weight loading to seconds, CUDA graph capture still takes tens of seconds to minutes and often dominates startup. Unfortunately, CUDA graphs cannot be naively serialized: beyond graph topology, they are tightly coupled to execution context, including device addresses embedded in kernel arguments and kernel code lazily loaded during warmup. Existing approaches either rely on brittle kernel-specific patching or heavyweight process-level checkpoint/restore that are inflexible to dynamic parallelism switching. We present Foundry, a template-based CUDA graph context materialization system that persists both graph topology and execution context during an offline processing stage, and reconstructs executable graphs online with negligible overhead. Foundry enforces deterministic memory layouts, automatically extracts and reloads kernel binaries required by captured graphs, and reduces online reconstruction costs through topology-based templating. For distributed serving, Foundry further enables a single-GPU offline capture to generate templates for multi-GPU deployments by patching only rank-dependent communication state. Across dense and MoE models up to 235B parameters, Foundry reduces cold-start latency by up to 99%, cutting the initialization time of Qwen3-235B-A22B from 10 minutes to 3.9 seconds while preserving the throughput gains of CUDA graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Foundry, a template-based CUDA graph context materialization system for reducing cold-start latency in LLM serving under autoscaling and dynamic parallelism. It performs offline capture of both graph topology and execution context (including deterministic memory layouts and kernel binaries), then reconstructs executable graphs online with negligible overhead. For distributed multi-GPU deployments, it generates templates from single-GPU captures by patching only rank-dependent communication state. The central claims are up to 99% cold-start latency reduction (e.g., Qwen3-235B-A22B initialization from 10 minutes to 3.9 seconds) while preserving CUDA graph throughput.
Significance. If the claims are substantiated, Foundry would meaningfully advance practical LLM serving by addressing the CUDA graph capture bottleneck that dominates cold starts, enabling faster reconfiguration without sacrificing the performance benefits of graphs. The separation of offline/online phases, automatic kernel binary handling, and single-to-multi-GPU templating via targeted patching are pragmatic engineering contributions that could influence production systems.
major comments (2)
- Abstract: The quantitative claims of up to 99% latency reduction and a 3.9-second initialization time for the 235B model are presented without any reference to experimental methodology, hardware configuration, baselines, error bars, or ablation studies. These details are load-bearing for the central performance claim and must be provided to allow assessment of reproducibility and generality.
- Abstract (multi-GPU description): The approach of generating multi-GPU templates from single-GPU capture 'by patching only rank-dependent communication state' is insufficiently justified. CUDA graphs embed additional device-specific state (memory pointers, device ordinals, and per-rank allocations) directly into kernel launch parameters and nodes beyond NCCL collectives; if these are not explicitly handled, online reconstruction risks incorrect execution or non-negligible overhead during dynamic parallelism switches.
minor comments (1)
- The abstract would benefit from a concise statement of the offline versus online phase responsibilities to improve immediate clarity of the workflow.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We address each major comment point by point below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: Abstract: The quantitative claims of up to 99% latency reduction and a 3.9-second initialization time for the 235B model are presented without any reference to experimental methodology, hardware configuration, baselines, error bars, or ablation studies. These details are load-bearing for the central performance claim and must be provided to allow assessment of reproducibility and generality.
Authors: We agree that the abstract would benefit from additional context to support assessment of the central claims. In the revised manuscript, we will update the abstract to briefly reference the experimental methodology, including the hardware platform (NVIDIA H100 GPUs in a multi-node setup), the primary baselines (standard CUDA graph capture without Foundry and representative LLM serving systems), and a note that full details on error bars (from repeated runs) and ablation studies appear in Sections 5 and 6. This change will improve transparency while respecting abstract length limits. revision: yes
-
Referee: Abstract (multi-GPU description): The approach of generating multi-GPU templates from single-GPU capture 'by patching only rank-dependent communication state' is insufficiently justified. CUDA graphs embed additional device-specific state (memory pointers, device ordinals, and per-rank allocations) directly into kernel launch parameters and nodes beyond NCCL collectives; if these are not explicitly handled, online reconstruction risks incorrect execution or non-negligible overhead during dynamic parallelism switches.
Authors: We thank the referee for this precise observation on CUDA graph internals. Our design enforces deterministic memory layouts during offline capture, ensuring that memory pointers and per-rank allocations remain consistent and can be systematically adjusted through the rank-specific patching process. Device ordinals are explicitly included in the patched state, and the templating mechanism updates all embedded launch parameters accordingly rather than limiting changes to NCCL collectives. We have validated correct execution and negligible overhead in our multi-GPU experiments. To address the concern directly, we will expand the multi-GPU templating subsection with a more detailed explanation of the full state-handling procedure, including how non-communication device state is managed, along with additional validation results. revision: yes
Circularity Check
No circularity: offline/online phases are independent engineering mechanisms
full rationale
The paper presents an engineering system design with a clear separation between an offline stage (capturing graph topology, execution context, memory layouts, and kernel binaries) and an online reconstruction stage. No equations, fitted parameters, or mathematical derivations are present. Core claims rely on explicit mechanisms such as deterministic memory layouts, automatic kernel binary extraction, and topology-based templating rather than reducing to self-referential definitions or self-citations. The distributed multi-GPU extension via rank-dependent patching is described as a direct implementation choice, not derived from prior self-cited results. This matches the default expectation of a self-contained system description without circular dependence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CUDA graphs are tightly coupled to execution context including device addresses and lazily loaded kernel code, preventing naive serialization
invented entities (1)
-
template-based CUDA graph context materialization
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Foundry enforces deterministic memory layouts, automatically extracts and reloads kernel binaries required by captured graphs, and reduces online reconstruction costs through topology-based templating.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For distributed serving, Foundry further enables a single-GPU offline capture to generate templates for multi-GPU deployments by patching only rank-dependent communication state.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). 117–134. https://www.usenix.org/conference/...
2024
-
[2]
Amazon Web Services. [n. d.].Amazon Bedrock.https:// aws.amazon.com/bedrock/
-
[3]
2025.Let Tensors Fly — Accelerating Large Model Weight Loading with R-Fork.https: //lmsys.org/blog/2025-12-10-rfork/
Ant Group DeepXPU Team and SGLang Team. 2025.Let Tensors Fly — Accelerating Large Model Weight Loading with R-Fork.https: //lmsys.org/blog/2025-12-10-rfork/
2025
-
[4]
Vivek M Bhasi, Jashwant Raj Gunasekaran, Prashanth Thinakaran, Cyan Subhra Mishra, Mahmut Taylan Kandemir, and Chita Das. 2021. Kraken: Adaptive container provisioning for deploying dynamic dags in serverless platforms. InProceedings of the ACM Symposium on Cloud Computing. 153–167
2021
-
[5]
Marc Brooker, Mike Danilov, Chris Greenwood, and Phil Piwonka
-
[6]
In2023 USENIX Annual Technical Conference (USENIX ATC 23)
On-demand container loading in{AWS} lambda. In2023 USENIX Annual Technical Conference (USENIX ATC 23). 315–328
-
[7]
James Cadden, Thomas Unger, Yara Awad, Han Dong, Orran Krieger, and Jonathan Appavoo. 2020. SEUSS: skip redundant paths to make serverless fast. InProceedings of the Fifteenth European Conference on Computer Systems. 1–15
2020
-
[8]
Shubham Chaudhary, Ramachandran Ramjee, Muthian Sivathanu, Nipun Kwatra, and Srinidhi Viswanatha. 2020. Balancing efficiency and fairness in heterogeneous GPU clusters for deep learning. In Proceedings of the Fifteenth European Conference on Computer Systems. 1–16
2020
-
[9]
checkpoint-restore. [n. d.]. CRIU: Checkpoint/Restore tool.https: //github.com/checkpoint-restore/criu. GitHub repository, accessed April 1, 2026
2026
-
[10]
Haoyu Chen, Xue Li, Kun Qian, Yu Guan, Jin Zhao, and Xin Wang
-
[11]
Gyges: Dynamic Cross-Instance Parallelism Transformation for Efficient LLM Inference.arXiv preprint arXiv:2509.19729(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
NVIDIA Corporation. 2025. cuda-checkpoint: CUDA Checkpoint and Restore Utility.https://github .com/NVIDIA/cuda-checkpoint. Accessed: 2026-03-22
2025
-
[13]
DeepSeek-AI. 2025. Open Infra Index. GitHub repository.https: //github.com/deepseek-ai/open-infra-indexDay 6: One More Thing – DeepSeek-V3/R1 Inference System Overview
2025
-
[14]
Niklas Eiling, Jonas Baude, Stefan Lankes, and Antonello Monti. 2022. Cricket: A virtualization layer for distributed execution of CUDA applications with checkpoint/restart support.Concurrency and Com- putation: Practice and Experience34, 14 (2022), e6474
2022
-
[15]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. {ServerlessLLM}:{Low- Latency} serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 24). 135–153
2024
-
[16]
Alexander Fuerst and Prateek Sharma. 2021. Faascache: keeping serverless computing alive with greedy-dual caching. InProceedings of the 26th ACM international conference on architectural support for programming languages and operating systems. 386–400
2021
- [17]
-
[18]
Rohan Garg, Apoorve Mohan, Michael Sullivan, and Gene Cooperman
-
[19]
In2018 IEEE International Conference on Cluster Computing (CLUSTER)
CRUM: Checkpoint-restart support for CUDA’s unified memory. In2018 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 302–313
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Naibin Gu, Zhenyu Zhang, Yuchen Feng, Yilong Chen, Peng Fu, Zheng Lin, Shuohuan Wang, Yu Sun, Hua Wu, Weiping Wang, et al. 2025. Elastic MoE: Unlocking the Inference-Time Scalability of Mixture-of- Experts.arXiv preprint arXiv:2509.21892(2025)
work page internal anchor Pith review arXiv 2025
-
[22]
Junhao Hu, Jiang Xu, Zhixia Liu, Yulong He, Yuetao Chen, Hao Xu, Jiang Liu, Jie Meng, Baoquan Zhang, Shining Wan, Gengyuan Dan, Zhiyu Dong, Zhihao Ren, Changhong Liu, Tao Xie, Dayun Lin, Qin Zhang, Yue Yu, Hao Feng, Xusheng Chen, and Yizhou Shan. 2025. DEEPSERVE: Serverless Large Language Model Serving at Scale. In 2025 USENIX Annual Technical Conference ...
2025
-
[23]
Twinkle Jain and Gene Cooperman. 2020. Crac: Checkpoint-restart architecture for cuda with streams and uvm. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15
2020
-
[24]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ra- mona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al . 2025. Gemma 3 technical report.arXiv preprint arXiv:2503.197864 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Michael Kerrisk. [n. d.].proc_sys_kernel(5) — Linux manual page. man7.org.https://man7 .org/linux/ man-pages/man5/proc_sys_kernel.5.htmlSection: /proc/sys/kernel/randomize_va_space, accessed 2026-04-01
2026
-
[26]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[27]
Gonzalez, Hao Zhang, and Ion Stoica
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). doi:10 .1145/3600006.3613165
-
[28]
Zhen Lin, Kao-Feng Hsieh, Yu Sun, Seunghee Shin, and Hui Lu. 2021. Flashcube: Fast provisioning of serverless functions with streamlined container runtimes. InProceedings of the 11th Workshop on Program- ming Languages and Operating Systems. 38–45
2021
- [29]
-
[30]
Chiheng Lou, Sheng Qi, Chao Jin, Dapeng Nie, Haoran Yang, Yu Ding, Xuanzhe Liu, and Xin Jin. 2026. HydraServe: Minimizing Cold Start Latency for Serverless LLM Serving in Public Clouds. InProceedings of the 23rd USENIX Symposium on Networked Systems Design and Im- plementation (NSDI ’26).https://www .usenix.org/conference/nsdi26/ presentation/lou
2026
- [31]
-
[32]
Akira Nukada, Taichiro Suzuki, and Satoshi Matsuoka. 2023. Efficient checkpoint/Restart of CUDA applications.Parallel Comput.116 (2023), 103018
2023
-
[33]
NVIDIA.https://docs .nvidia.com/cuda/cuda-driver- api/group__CUDA__GRAPH.htmlAccessed March 5, 2026
NVIDIA 2026.CUDA Driver API: Graph Management. NVIDIA.https://docs .nvidia.com/cuda/cuda-driver- api/group__CUDA__GRAPH.htmlAccessed March 5, 2026
2026
-
[34]
2026.NCCL: Optimized primitives for inter-GPU communica- tion.https://github.com/NVIDIA/nccl
NVIDIA. 2026.NCCL: Optimized primitives for inter-GPU communica- tion.https://github.com/NVIDIA/nccl
2026
-
[35]
2026.NVSHMEM: The NVIDIA SHMEM library for GPU clusters.https://github.com/NVIDIA/nvshmem
NVIDIA. 2026.NVSHMEM: The NVIDIA SHMEM library for GPU clusters.https://github.com/NVIDIA/nvshmem
2026
-
[36]
OpenAI. [n. d.].Models | OpenAI API.https://developers .openai.com/ api/docs/models
-
[37]
2025.Weight Transfer for RL Post-Training in under 2 seconds.https://research .perplexity.ai/articles/weight-transfer-for- rl-post-training-in-under-2-seconds 13
Perplexity. 2025.Weight Transfer for RL Post-Training in under 2 seconds.https://research .perplexity.ai/articles/weight-transfer-for- rl-post-training-in-under-2-seconds 13
2025
-
[38]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Manage- ment for Serving LLMs without PagedAttention. InProceedings of the 30th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Systems (ASPLOS ’25). 1133–1150. doi:10.1145/3669940.3707256
-
[39]
PyTorch Contributors. [n. d.]. CUDA semantics.https:// docs.pytorch.org/docs/stable/notes/cuda.html. Accessed: 2026-04-01
2026
- [40]
-
[41]
Qwen Team. 2025. Qwen3-14B.https://huggingface .co/Qwen/Qwen3- 14B. Hugging Face model card, accessed 2026-04-01
2025
-
[42]
Rohan Basu Roy, Tirthak Patel, and Devesh Tiwari. 2022. Icebreaker: Warming serverless functions better with heterogeneity. InProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 753–767
2022
- [43]
-
[44]
Yifan Sui, Hanfei Yu, Yitao Hu, Jianxun Li, and Hao Wang. 2024. Pre- warming is not enough: Accelerating serverless inference with oppor- tunistic pre-loading. InProceedings of the 2024 ACM Symposium on Cloud Computing. 178–195
2024
-
[45]
Hiroyuki Takizawa, Katsuto Sato, Kazuhiko Komatsu, and Hiroaki Kobayashi. 2009. CheCUDA: A checkpoint/restart tool for CUDA ap- plications. In2009 International Conference on Parallel and Distributed Computing, Applications and Technologies. IEEE, 408–413
2009
-
[46]
2026.Elastic EP in SGLang: Achieving Partial Failure Tolerance for DeepSeek MoE Deploy- ments.https://www .lmsys.org/blog/2026-03-25-eep-partial-failure- tolerance/
The Mooncake Team, Volcano Engine. 2026.Elastic EP in SGLang: Achieving Partial Failure Tolerance for DeepSeek MoE Deploy- ments.https://www .lmsys.org/blog/2026-03-25-eep-partial-failure- tolerance/
2026
-
[47]
vLLM Project. [n. d.].CUDA Graphs - vLLM.https://docs .vllm.ai/en/ latest/design/cuda_graphs/
-
[48]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al . 2025. Burstgpt: A real-world workload dataset to optimize llm serving sys- tems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5831–5841
2025
-
[49]
Xingda Wei, Zhuobin Huang, Tianle Sun, Yingyi Hao, Rong Chen, Mingcong Han, Jinyu Gu, and Haibo Chen. 2025. PhoenixOS: Concur- rent OS-level GPU Checkpoint and Restore with Validated Speculation. InProceedings of the 31st Symposium on Operating Systems Principles (SOSP ’25). doi:10.1145/3731569.3764813
-
[50]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 640–654
2024
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [52]
- [53]
-
[54]
Shaoxun Zeng, Tingxu Ren, Jiwu Shu, and Youyou Lu. 2026. {GPU } {Checkpoint/Restore} Made Fast and Lightweight. In24th USENIX Conference on File and Storage Technologies (FAST 26). 239– 254
2026
-
[55]
Shaoxun Zeng, Minhui Xie, Shiwei Gao, Youmin Chen, and Youyou Lu. 2025. Medusa: Accelerating Serverless LLM Inference with Ma- terialization. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25). 653–668. doi:10.1145/3669940.3707285
-
[56]
Dingyan Zhang, Haotian Wang, Yang Liu, Xingda Wei, Yizhou Shan, Rong Chen, and Haibo Chen. 2025. {BlitzScale}: Fast and Live Large Model Autoscaling with O (1) Host Caching. In19th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 25). 275–293
2025
-
[57]
Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Huazuo Gao, Jiashi Li, Liyue Zhang, Panpan Huang, Shangyan Zhou, Shirong Ma, et al . 2025. Insights into deepseek-v3: Scaling challenges and reflections on hardware for ai architectures. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 1731–1745
2025
-
[58]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serv- ing. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Art...
2024
-
[59]
Wenbin Zhu, Zhaoyan Shen, Zili Shao, Hongjun Dai, and Feng Chen
- [60]
-
[61]
id": 7,
Edward Zitron. 2025.Exclusive: Here’s How Much OpenAI Spends On Inference and Its Revenue Share With Microsoft.https:// www.wheresyoured.at/oai_docs/ 14 A Parallel CUDA Graph Construction We build a standalone test that allocates different numbers of threads to build 80 graphs, each with 500 dummy nodes, in parallel. Table 2 shows that wall time is almost...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.