Recognition: no theorem link
Generative Cross-Entropy: A Strictly Proper Loss for Data-Efficient Classification
Pith reviewed 2026-05-12 01:18 UTC · model grok-4.3
The pith
GenCE rewrites cross-entropy to normalize softmax scores within each mini-batch, making the loss strictly proper so its minimum is uniquely the true posterior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GenCE follows from rewriting the class-conditional likelihood in Bayesian form and approximating it via mini-batch normalization of each sample's softmax score against the model's predictions on the rest of the batch. The authors prove that the population risk of this non-local loss is uniquely minimized at the true posterior provided the mild completeness condition holds, and they show that the same training procedure produces lower error than cross-entropy on three datasets in both balanced small-data and class-imbalanced regimes.
What carries the argument
Mini-batch normalization of softmax scores, which couples the training signal across examples that share a predicted class and thereby injects a generative principle into an otherwise discriminative network.
If this is right
- GenCE can be substituted for cross-entropy in any existing discriminative classifier without altering the network or adding parameters.
- Training with GenCE yields better-calibrated probabilities and improved out-of-distribution detection as direct consequences of its strict properness.
- The same loss improves performance in both low-sample balanced settings and class-imbalanced regimes because the batch-normalization term supplies information that standard cross-entropy lacks.
- No separate generative model needs to be fit; the generative signal arises entirely from the normalization step inside the discriminative training loop.
Where Pith is reading between the lines
- The batch-normalization step might be generalized to other non-local losses that couple predictions across examples, potentially improving sample efficiency in structured prediction tasks.
- Because the method avoids fitting an explicit density model, it could be combined with modern data-augmentation pipelines to obtain further gains in extremely low-data regimes.
- If the completeness condition holds for typical over-parameterized networks, GenCE might also serve as a drop-in replacement in semi-supervised settings where pseudo-labels are generated from the same model.
Load-bearing premise
The mild completeness condition must hold so that the population risk is uniquely minimized at the true posterior, together with the validity of the mini-batch approximation to the class-conditional likelihood.
What would settle it
A controlled experiment in which the empirical risk minimizer of GenCE is shown to converge to a different distribution than the true posterior on data generated from a known posterior, or in which GenCE fails to outperform cross-entropy on a small balanced dataset where the completeness condition is deliberately violated.
Figures



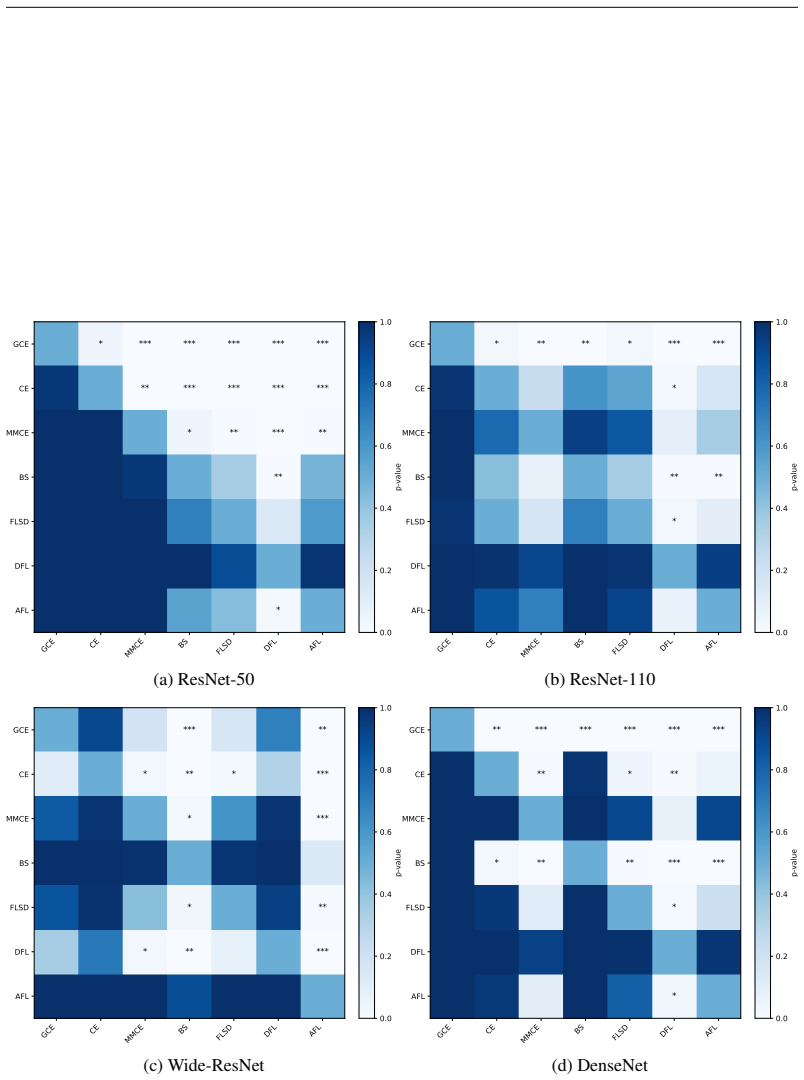
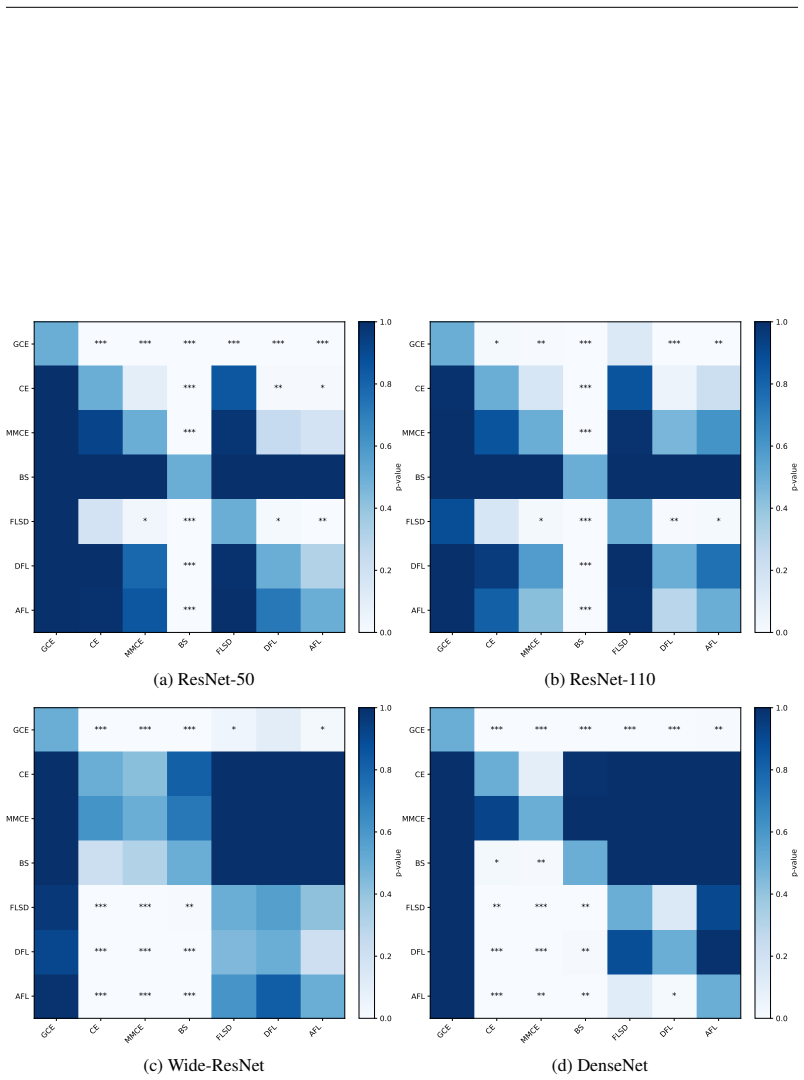
read the original abstract
Cross-entropy (CE) is the default training loss for supervised classification, but its sample efficiency is limited when labels are scarce. Existing remedies primarily act on the data side, via augmentation, synthesis, or transfer from pretrained models; the training objective itself is rarely revisited. We revisit it here. Drawing on the classical observation that generative classifiers reach their asymptotic error with fewer samples than discriminative ones, we propose Generative Cross-Entropy (GenCE), a drop-in replacement for CE that introduces a generative learning principle into a standard discriminative network without altering the architecture or fitting a separate density model. GenCE follows from a Bayesian rewrite of the class-conditional likelihood and, in the mini-batch approximation, reduces to normalizing each sample's softmax score against the model's predictions on the batch, coupling the training signal across examples sharing a class. We extend the proper-scoring-rule framework to such non-local losses and prove that GenCE is strictly proper under a mild completeness condition: its population risk is uniquely minimized at the true posterior. Across three datasets, on two architectures and in both balanced small-data and class-imbalanced regimes, GenCE outperforms CE and other widely used losses, while also producing better-calibrated probabilities and stronger out-of-distribution detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Generative Cross-Entropy (GenCE) as a drop-in replacement for standard cross-entropy in supervised classification. GenCE is obtained via a Bayesian rewrite of the class-conditional likelihood and, in its mini-batch form, normalizes each sample's softmax against the model's predictions on the current batch. The authors extend the proper-scoring-rule framework to non-local losses and prove that GenCE is strictly proper under a mild completeness condition, so that its population risk is uniquely minimized at the true posterior. Experiments on three datasets with two architectures report gains over CE and other losses in balanced small-data and class-imbalanced regimes, together with improved calibration and OOD detection.
Significance. If the strict-properness claim survives scrutiny of the mini-batch approximation, GenCE supplies a principled, architecture-preserving route to incorporating generative information into discriminative training. This could improve sample efficiency without separate density models. The empirical results in data-scarce and imbalanced regimes, if robust, would constitute a practical contribution; the extension of proper-scoring rules to batch-coupled losses is also of conceptual interest.
major comments (2)
- [§3.3] §3.3, Eq. (8) and the subsequent population-risk definition: the proof that the expectation over random mini-batches preserves unique minimization at the true posterior under the completeness condition does not address the dependence created by intra-batch normalization. Because the normalization couples examples within each finite batch, it is not immediate that the resulting risk functional remains strictly proper when the completeness condition holds only approximately (the regime of the small-data and imbalanced experiments).
- [§4.1] §4.1, Theorem 1: the completeness condition is stated as 'mild,' yet the argument relies on it holding exactly for the population; no quantitative bound is given on how violation of the condition (inevitable with finite batches or finite data) propagates to the uniqueness of the minimizer.
minor comments (3)
- [§5] The experimental tables report point estimates without error bars or results from multiple random seeds; adding these would strengthen the empirical claims.
- Notation for the batch-normalized softmax (e.g., the precise definition of the normalizing constant) is introduced only in the mini-batch section; moving a compact definition to the notation table would improve readability.
- [§3] The abstract states that GenCE 'reduces to normalizing each sample's softmax score against the model's predictions on the batch'; a one-sentence reminder of this reduction in the theoretical section would help readers connect the derivation to the implementation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We respond to each major comment below and indicate the revisions we intend to make.
read point-by-point responses
-
Referee: [§3.3] §3.3, Eq. (8) and the subsequent population-risk definition: the proof that the expectation over random mini-batches preserves unique minimization at the true posterior under the completeness condition does not address the dependence created by intra-batch normalization. Because the normalization couples examples within each finite batch, it is not immediate that the resulting risk functional remains strictly proper when the completeness condition holds only approximately (the regime of the small-data and imbalanced experiments).
Authors: We appreciate the referee highlighting the intra-batch dependence. The population risk is defined as the expectation of the GenCE loss over the distribution of randomly sampled mini-batches. Under the completeness condition, each batch term is minimized uniquely when the model outputs the true posterior; because the expectation marginalizes over all possible batch compositions, the coupling within any single finite batch does not shift the location of the global minimizer. We nevertheless agree that the current proof sketch would benefit from an explicit step that isolates the normalization operator and shows it preserves uniqueness after the outer expectation. In the revision we will expand the argument in §3.3 with this intermediate derivation while leaving the theorem statement unchanged. This is a partial revision focused on exposition. revision: partial
-
Referee: [§4.1] §4.1, Theorem 1: the completeness condition is stated as 'mild,' yet the argument relies on it holding exactly for the population; no quantitative bound is given on how violation of the condition (inevitable with finite batches or finite data) propagates to the uniqueness of the minimizer.
Authors: The referee correctly observes that we supply no quantitative bounds on the effect of approximate completeness. The condition is labeled mild because it is satisfied whenever the model class is sufficiently expressive to represent the true class-conditionals—an assumption standard in consistency analyses of classifiers. For finite data the condition holds only approximately, yet the empirical results on small-data and imbalanced regimes indicate that GenCE retains its advantages. We will insert a short discussion paragraph after Theorem 1 that (i) recalls the role of the condition, (ii) acknowledges the absence of finite-sample bounds, and (iii) notes that deriving such bounds under additional regularity assumptions is left for future work. No alteration to the theorem itself is required. revision: partial
Circularity Check
No circularity: derivation from Bayesian rewrite and proof under stated condition are independent of target result
full rationale
The paper obtains GenCE via a standard Bayesian identity applied to the class-conditional likelihood, followed by an explicit mini-batch normalization approximation whose population risk is then analyzed. It extends the proper-scoring-rule framework to non-local losses and states a mild completeness condition under which the risk is uniquely minimized at the true posterior. No equation reduces to a fitted parameter, no self-citation supplies the uniqueness theorem, and the mini-batch coupling is part of the defined loss rather than a hidden assumption that forces the conclusion. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild completeness condition under which the population risk of GenCE is uniquely minimized at the true posterior
Reference graph
Works this paper leans on
-
[1]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common cor- ruptions and perturbations.arXiv preprint arXiv:1903.12261,
work page internal anchor Pith review arXiv 1903
-
[2]
Like Hui and Mikhail Belkin. Evaluation of neural architectures trained with square loss vs cross- entropy in classification tasks.arXiv preprint arXiv:2006.07322,
-
[3]
William J Jagust, Susan M Landau, Robert A Koeppe, Eric M Reiman, Kewei Chen, Chester A Mathis, Julie C Price, Norman L Foster, and Angela Y Wang. The alzheimer’s disease neu- roimaging initiative 2 pet core: 2015.Alzheimer’s & Dementia, 11(7):757–771,
work page 2015
-
[4]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp
work page 2011
-
[5]
Khanh Nguyen and Brendan O’Connor. Posterior calibration and exploratory analysis for natural language processing models.arXiv preprint arXiv:1508.05154,
-
[6]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks.arXiv preprint arXiv:1605.07146,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.