Recognition: no theorem link
AgentGate: A Lightweight Structured Routing Engine for the Internet of Agents
Pith reviewed 2026-05-10 18:35 UTC · model grok-4.3
The pith
AgentGate decomposes agent routing into an action decision stage followed by structural grounding, enabling compact models to handle dispatch competitively under constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
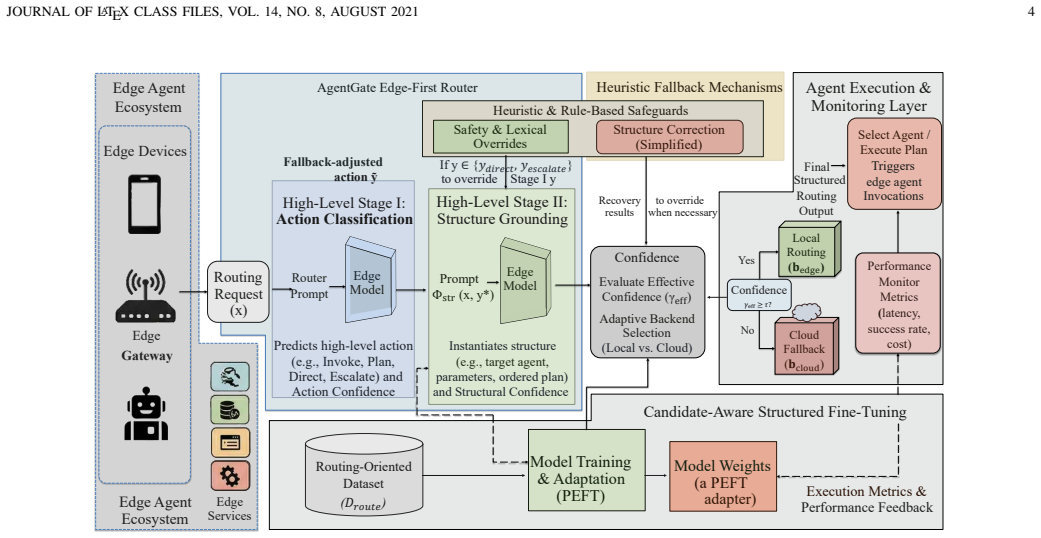
AgentGate formulates candidate-aware agent dispatch as a constrained decision problem that decomposes into an action decision stage, which selects among single-agent invocation, multi-agent planning, direct response, or safe escalation, and a structural grounding stage, which instantiates the chosen action as executable targets, arguments, or plans. A routing-oriented fine-tuning scheme with candidate-aware supervision and hard negative examples adapts compact open-weight models to this format, yielding competitive routing performance on a curated benchmark where model differences concentrate in action prediction, candidate selection, and structured grounding quality.
What carries the argument
Two-stage decomposition of routing: the first stage selects an action category and the second stage grounds it into structured executable outputs, supported by candidate-aware fine-tuning that incorporates hard negatives.
If this is right
- Routing decisions can be executed on resource-limited hardware without transmitting queries to large cloud models.
- Agent systems gain more predictable and auditable dispatch by enforcing explicit action categories rather than free generation.
- Smaller models become practical for coordination tasks when supervision targets structured outputs instead of full responses.
- Dispatch remains feasible even when candidate agent pools change frequently, provided the grounding stage is trained on them.
Where Pith is reading between the lines
- Local routers of this form could reduce overall system cost by limiting large-model calls to only the final task execution.
- The same split between decision type and structured output may transfer to tool-selection or workflow-planning subsystems.
- Deployment on edge nodes would allow fully on-device routing for privacy-sensitive agent interactions.
- Dynamic candidate pools in production would require periodic re-tuning or retrieval-augmented grounding to maintain accuracy.
Load-bearing premise
The curated benchmark and the two-stage action-then-grounding split are representative of the latency, privacy, and cost constraints that arise in real heterogeneous agent deployments.
What would settle it
A controlled comparison in which a single-stage unrestricted generation baseline using a larger model produces measurably higher end-to-end routing accuracy or lower effective latency on queries drawn from live multi-agent traffic.
Figures

read the original abstract
The rapid development of AI agent systems is leading to an emerging Internet of Agents, where specialized agents operate across local devices, edge nodes, private services, and cloud platforms. Although recent efforts have improved agent naming, discovery, and interaction, efficient request dispatch remains an open systems problem under latency, privacy, and cost constraints. In this paper, we present AgentGate, a lightweight structured routing engine for candidate-aware agent dispatch. Instead of treating routing as unrestricted text generation, AgentGate formulates it as a constrained decision problem and decomposes it into two stages: action decision and structural grounding. The first stage determines whether a query should trigger single-agent invocation, multi-agent planning, direct response, or safe escalation, while the second stage instantiates the selected action into executable outputs such as target agents, structured arguments, or multi-step plans. To adapt compact models to this setting, we further develop a routing-oriented fine-tuning scheme with candidate-aware supervision and hard negative examples. Experiments on a curated routing benchmark with several 3B--7B open-weight models show that compact models can provide competitive routing performance in constrained settings, and that model differences are mainly reflected in action prediction, candidate selection, and structured grounding quality. These results indicate that structured routing is a feasible design point for efficient and privacy-aware agent systems, especially when routing decisions must be made under resource-constrained deployment conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentGate, a lightweight structured routing engine for candidate-aware agent dispatch in the Internet of Agents. Routing is formulated as a constrained decision problem decomposed into two stages: (1) action decision, which selects among single-agent invocation, multi-agent planning, direct response, or safe escalation; and (2) structural grounding, which instantiates the action into executable outputs such as target agents, structured arguments, or multi-step plans. A routing-oriented fine-tuning scheme using candidate-aware supervision and hard negative examples is proposed to adapt compact 3B–7B open-weight models. Experiments on a curated routing benchmark are reported to show competitive performance, with model differences primarily in action prediction, candidate selection, and structured grounding quality.
Significance. If the empirical results hold under representative conditions, the work identifies a practical design point for efficient, privacy-aware, and low-latency routing in heterogeneous agent environments. The two-stage decomposition and candidate-aware fine-tuning could reduce reliance on large models for dispatch decisions, supporting deployment on edge and local devices.
major comments (2)
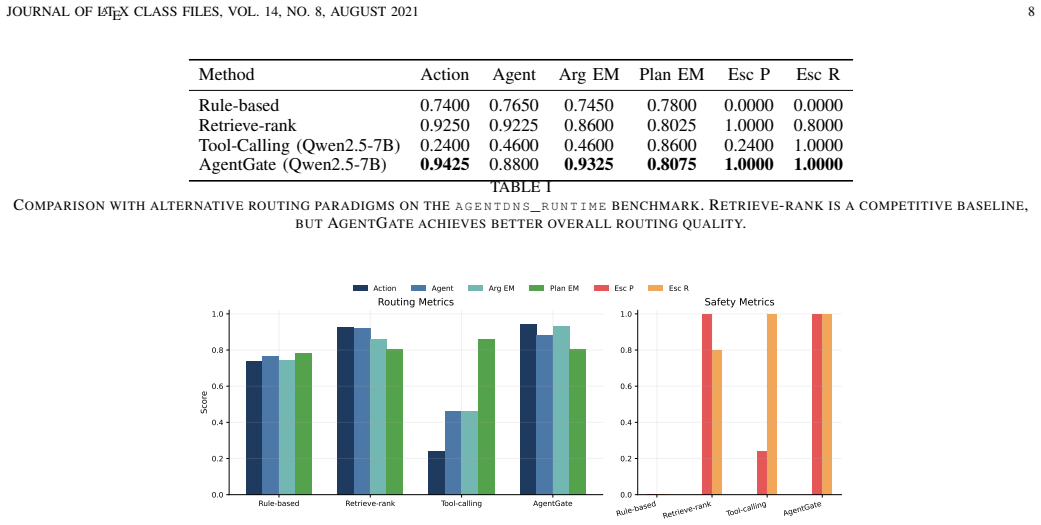
- [Abstract / Experiments] Abstract and Experiments section: the claim of 'competitive routing performance' with 3B–7B models is stated without any quantitative metrics, baseline comparisons, error bars, statistical significance tests, or details on benchmark construction (query sourcing, agent heterogeneity, cost/privacy labeling, negative-example generation, or data exclusions). This leaves the central empirical claim only weakly supported.
- [Experiments / Conclusion] The feasibility conclusion that 'structured routing is a feasible design point for efficient and privacy-aware agent systems' rests on the curated benchmark being representative of real deployment constraints (latency, privacy, cost across local vs. cloud and strict-privacy vs. open settings). No evidence or analysis is provided to establish this representativeness, which is load-bearing for the broader claim.
minor comments (3)
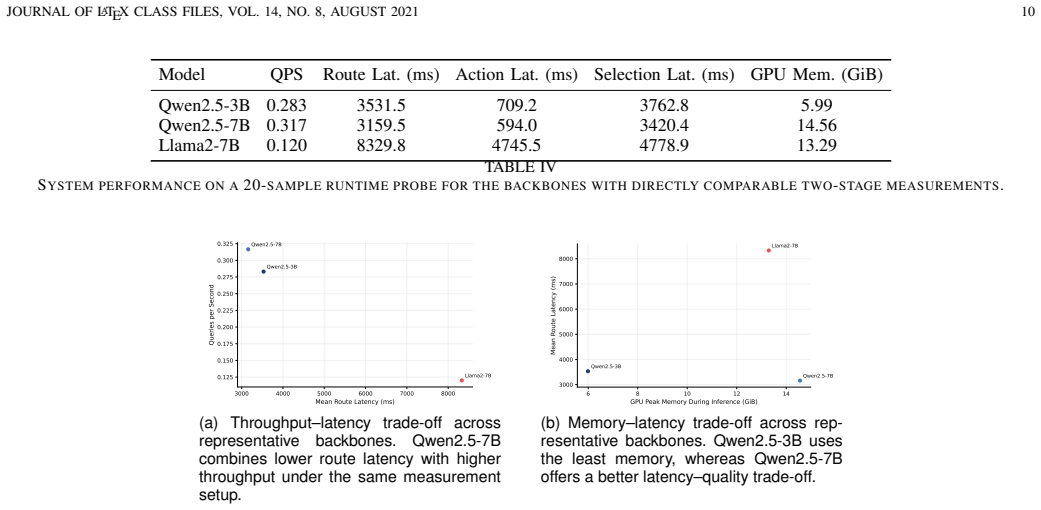
- Clarify the precise model architectures, parameter counts, and inference settings (e.g., quantization, batch size) used in the reported experiments.
- Provide the exact definition of the candidate-aware supervision signal and the construction of hard negatives in the fine-tuning scheme.
- Add a limitations or scope section that explicitly discusses the assumptions underlying the two-stage decomposition and the benchmark.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important areas where the empirical presentation can be strengthened. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim of 'competitive routing performance' with 3B–7B models is stated without any quantitative metrics, baseline comparisons, error bars, statistical significance tests, or details on benchmark construction (query sourcing, agent heterogeneity, cost/privacy labeling, negative-example generation, or data exclusions). This leaves the central empirical claim only weakly supported.
Authors: We agree that the abstract and experiments section would benefit from more explicit quantitative support. The manuscript describes the two-stage decomposition and reports model differences in action prediction and grounding quality, but we acknowledge the absence of direct numerical comparisons, baselines, error bars, and full benchmark construction details in the presented form. In the revision we will (1) update the abstract with key performance figures from the experiments, (2) add a summary table comparing the 3B–7B models against zero-shot larger-model routing and simple heuristic baselines, (3) include standard deviations and note on statistical testing, and (4) expand Section 4.1 with the requested details on query sourcing, agent-type heterogeneity, constraint labeling, and hard-negative construction. These changes will make the competitiveness claim more concrete while preserving the paper’s focus on the lightweight structured approach. revision: yes
-
Referee: [Experiments / Conclusion] The feasibility conclusion that 'structured routing is a feasible design point for efficient and privacy-aware agent systems' rests on the curated benchmark being representative of real deployment constraints (latency, privacy, cost across local vs. cloud and strict-privacy vs. open settings). No evidence or analysis is provided to establish this representativeness, which is load-bearing for the broader claim.
Authors: We recognize that the broader feasibility claim depends on the benchmark reflecting realistic constraints. The benchmark was designed with agent types spanning local, edge, and cloud settings and queries labeled for latency/privacy/cost trade-offs, yet we did not supply a dedicated representativeness analysis or external validation. In the revision we will add a subsection discussing benchmark construction choices and their alignment with common IoA constraints, plus a limitations paragraph that explicitly notes the curated nature of the data. We will also report sensitivity results under varied constraint weightings. A complete empirical validation against diverse production deployments, however, would require access to proprietary logs that are not available to us. revision: partial
- Full empirical validation of benchmark representativeness against heterogeneous real-world IoA deployment traces and logs
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical systems contribution describing AgentGate's two-stage routing design and evaluating it on a curated benchmark with 3B-7B models. No equations, mathematical derivations, fitted parameters, or predictions appear in the provided text or abstract. Claims rest on experimental outcomes rather than any reduction of results to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The approach is self-contained as standard empirical design work evaluated against an external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The two-stage decomposition (action decision then structural grounding) is sufficient to cover all relevant routing behaviors under the stated constraints.
invented entities (1)
-
AgentGate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Internet of agents: Weaving a web of heter ogeneous agents for collaborative intelligence,
W. Chen, Z. You, R. Li, Y . Guan, C. Qian, C. Zhao, C. Yang, R. Xie, Z. Liu, and M. Sun, “Internet of agents: Weaving a web of heterogeneous agents for collaborative intelligence,”arXiv preprint arXiv:2407.07061, 2024
-
[2]
Toward federated large language models: Motivations, methods, and future directions,
Y . Cheng, W. Zhang, Z. Zhang, C. Zhang, S. Wang, and S. Mao, “Toward federated large language models: Motivations, methods, and future directions,”IEEE Communications Surveys & Tutorials, vol. 27, no. 4, pp. 2733–2764, 2024
2024
-
[3]
Joint energy-efficient and throughput optimization in large-scale mobile networks via safe hierarchical marl,
H. Liu, T. Li, W. Huang, D. Niyato, and Y . Li, “Joint energy-efficient and throughput optimization in large-scale mobile networks via safe hierarchical marl,”IEEE Transactions on Wireless Communications, vol. 25, pp. 12 112–12 128, 2026
2026
-
[4]
Resource allocation driven by large models in future semantic-aware networks,
H. Zhang, J. Ni, Z. Wu, X. Liu, and V . C. Leung, “Resource allocation driven by large models in future semantic-aware networks,”IEEE Wireless Communications, 2025
2025
-
[5]
Agentdns: A root domain naming system for llm agents,
E. Cui, Y . Cheng, R. She, D. Liu, Z. Liang, M. Guo, T. Li, Q. Wei, W. Xing, and Z. Zhong, “Agentdns: A root domain naming system for llm agents,”arXiv preprint arXiv:2505.22368, 2025
-
[6]
A2h: Agent-to-human protocol for ai agent,
Z. Liang, E. Cui, Q. Wei, R. She, T. Li, M. Guo, and Y . Cheng, “A2h: Agent-to-human protocol for ai agent,”arXiv preprint arXiv:2602.15831, 2025
-
[7]
Llm-cloud complete: Lever- aging cloud computing for efficient large language model-based code completion,
M. Zhang, B. Yuan, H. Li, and K. Xu, “Llm-cloud complete: Lever- aging cloud computing for efficient large language model-based code completion,”Journal of Artificial Intelligence General science (JAIGS) ISSN: 3006-4023, vol. 5, no. 1, pp. 295–326, 2024
2024
-
[8]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024
2024
-
[9]
Chatdev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Conget al., “Chatdev: Communicative agents for software development,” inProceedings of the 62nd annual meeting of the associ- ation for computational linguistics (volume 1: Long papers), 2024, pp. 15 174–15 186. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2024
-
[10]
Metagpt: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Linet al., “Metagpt: Meta programming for a multi-agent collaborative framework,” inThe twelfth international conference on learning representations, 2023
2023
-
[11]
Crosslm: A data- free collaborative fine-tuning framework for large and small language models,
Y . Deng, Z. Qiao, Y . Zhang, Z. Ma, Y . Liu, and J. Ren, “Crosslm: A data- free collaborative fine-tuning framework for large and small language models,” inProceedings of the 23rd Annual International Conference on Mobile Systems, Applications and Services, 2025, pp. 124–137
2025
-
[12]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
K.-T. Tran, D. Dao, M.-D. Nguyen, Q.-V . Pham, B. O’Sullivan, and H. D. Nguyen, “Multi-agent collaboration mechanisms: A survey of llms,”arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural informa- tion processing systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[14]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 544–126 565, 2024
2024
-
[15]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,
Y . Shen, K. Song, X. Tan, D. Li, W. Lu, and Y . Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face,”Advances in Neural Information Processing Systems, vol. 36, pp. 38 154–38 180, 2023
2023
-
[16]
Adaptrack: Constrained decoding without distorting llm’s output intent,
Y . Li, J. Li, G. Li, and Z. Jin, “Adaptrack: Constrained decoding without distorting llm’s output intent,”arXiv preprint arXiv:2510.17376, 2025
-
[17]
Llm-based agents for tool learning: A survey: W. xu et al
W. Xu, C. Huang, S. Gao, and S. Shang, “Llm-based agents for tool learning: A survey: W. xu et al.”Data Science and Engineering, pp. 1–31, 2025
2025
-
[18]
Rcif: Toward robust distributed dnn collaborative inference under highly lossy iot networks,
Y . Cheng, Z. Zhang, and S. Wang, “Rcif: Toward robust distributed dnn collaborative inference under highly lossy iot networks,”IEEE Internet of Things Journal, vol. 11, no. 15, pp. 25 939–25 949, 2024
2024
-
[19]
Snapcfl: A pre-clustering-based clustered federated learning framework for data and system heterogeneities,
Y . Cheng, W. Zhang, Z. Zhang, J. Kang, Q. Xu, S. Wang, and D. Niyato, “Snapcfl: A pre-clustering-based clustered federated learning framework for data and system heterogeneities,”IEEE Transactions on Mobile Computing, vol. 24, no. 6, pp. 5214–5228, 2025
2025
-
[20]
Seful: A selective federated unlearning framework for client data heterogeneity in intelligent wireless networks,
Y . Cheng, W. Zhang, T. Zheng, E. Cui, X. Ma, and H. Zhang, “Seful: A selective federated unlearning framework for client data heterogeneity in intelligent wireless networks,”IEEE Transactions on Mobile Computing, 2025
2025
-
[21]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[22]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in neural information processing systems, vol. 36, pp. 10 088–10 115, 2023
2023
-
[23]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.