Recognition: 3 theorem links
· Lean TheoremBi-Lipschitz Autoencoder With Injectivity Guarantee
Pith reviewed 2026-05-10 18:33 UTC · model grok-4.3
The pith
Autoencoders can be made injective with a separation-based regularization while relaxing to bi-Lipschitz constraints for better geometry preservation and robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Bi-Lipschitz Autoencoder, through its injective regularization scheme based on a separation criterion and bi-Lipschitz relaxation, eliminates pathological local minima, preserves manifold geometry, and remains robust to data distribution drift, as demonstrated by superior empirical performance in structure preservation.
What carries the argument
The separation criterion for injective regularization together with the bi-Lipschitz relaxation that enforces geometry preservation.
If this is right
- Encoder mappings become injective, avoiding the mapping of distinct inputs to the same point.
- Latent representations better preserve the original manifold structure.
- The model exhibits resilience to sampling sparsity and distribution shifts.
- Overall performance exceeds that of prior regularized autoencoders on multiple datasets.
Where Pith is reading between the lines
- Similar regularization ideas might improve other unsupervised learning models that rely on latent space geometry.
- Testing on even more extreme distribution drifts could further validate the robustness claims.
- If the method scales well, it could be integrated into larger deep learning pipelines for data compression tasks.
Load-bearing premise
The separation-criterion regularization satisfies the admissible-regularization conditions without introducing new issues, and the bi-Lipschitz relaxation holds for arbitrary data distribution drifts.
What would settle it
A counterexample where the BLAE produces non-injective mappings on a dataset with a distribution shift, or fails to outperform baselines in manifold preservation metrics, would falsify the central claims.
Figures














read the original abstract
Autoencoders are widely used for dimensionality reduction, based on the assumption that high-dimensional data lies on low-dimensional manifolds. Regularized autoencoders aim to preserve manifold geometry during dimensionality reduction, but existing approaches often suffer from non-injective mappings and overly rigid constraints that limit their effectiveness and robustness. In this work, we identify encoder non-injectivity as a core bottleneck that leads to poor convergence and distorted latent representations. To ensure robustness across data distributions, we formalize the concept of admissible regularization and provide sufficient conditions for its satisfaction. In this work, we propose the Bi-Lipschitz Autoencoder (BLAE), which introduces two key innovations: (1) an injective regularization scheme based on a separation criterion to eliminate pathological local minima, and (2) a bi-Lipschitz relaxation that preserves geometry and exhibits robustness to data distribution drift. Empirical results on diverse datasets show that BLAE consistently outperforms existing methods in preserving manifold structure while remaining resilient to sampling sparsity and distribution shifts. Code is available at https://github.com/qipengz/BLAE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Bi-Lipschitz Autoencoder (BLAE) to address non-injectivity in regularized autoencoders for dimensionality reduction. It formalizes the concept of admissible regularization and provides sufficient conditions for injectivity, introduces an injective regularization scheme based on a separation criterion to eliminate pathological local minima, and adds a bi-Lipschitz relaxation to preserve manifold geometry with robustness to data distribution drift. The authors claim that BLAE consistently outperforms existing methods on diverse datasets while remaining resilient to sampling sparsity and shifts, with code publicly available.
Significance. If the theoretical injectivity guarantees are rigorously established and the empirical robustness holds under distribution shifts, the work could meaningfully improve training stability and representation quality in autoencoders by providing a principled regularization approach. The public code is a strength for reproducibility.
major comments (1)
- [Formalization of admissible regularization and separation criterion] The central theoretical claim rests on the assertion that the separation-criterion regularizer satisfies the sufficient conditions for admissible regularization and thereby guarantees injectivity. The manuscript provides no explicit derivation, proof, or verification that this holds (e.g., without additional assumptions on encoder Lipschitz constants or manifold curvature), which is load-bearing for the injectivity guarantee and the elimination of pathological minima.
minor comments (2)
- [Empirical results] The empirical section reports consistent outperformance but supplies no error bars, ablation studies on the separation-criterion threshold, or detailed protocols for testing robustness to distribution drift.
- [Method] Clarify the precise definition and implementation of the bi-Lipschitz relaxation term, including how it is relaxed from strict bi-Lipschitz constraints.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We are pleased that the significance of the theoretical guarantees and empirical robustness is recognized. Below, we provide a point-by-point response to the major comment, and we will revise the manuscript to address the concern.
read point-by-point responses
-
Referee: [Formalization of admissible regularization and separation criterion] The central theoretical claim rests on the assertion that the separation-criterion regularizer satisfies the sufficient conditions for admissible regularization and thereby guarantees injectivity. The manuscript provides no explicit derivation, proof, or verification that this holds (e.g., without additional assumptions on encoder Lipschitz constants or manifold curvature), which is load-bearing for the injectivity guarantee and the elimination of pathological minima.
Authors: We agree with the referee that the current manuscript would be improved by including an explicit derivation showing that the separation-criterion regularizer satisfies the sufficient conditions for admissible regularization. In the revised version, we will add a detailed proof in the main text or an appendix. This proof will specify the required assumptions, such as bounds on the encoder's Lipschitz constant and considerations for manifold curvature, to rigorously establish the injectivity guarantee and the elimination of pathological local minima. We believe this addition will clarify the theoretical foundation without altering the core contributions. revision: yes
Circularity Check
No significant circularity; formalization supplies independent logical foundation
full rationale
The paper defines admissible regularization and states sufficient conditions for injectivity as an independent formal step, then proposes a separation-criterion regularizer and bi-Lipschitz relaxation that are asserted to meet those conditions. No quoted equations or self-citations reduce the claimed injectivity guarantee or geometry preservation to a fitted parameter or prior result by construction. The derivation chain is self-contained: the sufficient conditions are presented as external to the specific regularizer choice, and the bi-Lipschitz term is introduced as a relaxation rather than a renaming or redefinition of outcomes. This matches the default expectation of no circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- separation-criterion threshold
axioms (1)
- domain assumption High-dimensional data lies on low-dimensional manifolds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Definition 4 (Bi-Lipschitz). A mapping f:M→N is κ-Bi-Lipschitz... 1/κ · dM(x,y) ≤ dN(f(x),f(y)) ≤ κ · dM(x,y)
-
IndisputableMonolith/Foundation/BranchSelectionRCLCombiner_isCoupling_iff echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Definition 2 ((δ,ϵ)-separation)... dN(f(x),f(y))/dM(x,y) > ϵ ... Theorem 1: f is injective iff (δ,ϵ)-separated
-
IndisputableMonolith/Foundation/AbsoluteFloorClosureabsolute_floor_iff_bare_distinguishability refines?
refinesRelation between the paper passage and the cited Recognition theorem.
Definition 3 (Admissibility)... SP = SQ ... Theorem 2: if min E[R] = min R(u) then admissible
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning flat latent manifolds with vaes.arXiv preprint arXiv:2002.04881,
Nutan Chen, Alexej Klushyn, Francesco Ferroni, Justin Bayer, and Patrick Van Der Smagt. Learning flat latent manifolds with vaes.arXiv preprint arXiv:2002.04881,
-
[2]
Flow Match- ing in Latent Space.arXiv:2307.08698,
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv preprint arXiv:2307.08698,
-
[3]
Isometric autoencoders.arXiv preprint arXiv:2006.09289,
Amos Gropp, Matan Atzmon, and Yaron Lipman. Isometric autoencoders.arXiv preprint arXiv:2006.09289,
-
[4]
Jungbin Lim, Jihwan Kim, Yonghyeon Lee, Cheongjae Jang, and Frank C Park. Graph geometry- preserving autoencoders. InForty-first International Conference on Machine Learning, 2024a. Uzu Lim, Harald Oberhauser, and Vidit Nanda. Tangent space and dimension estimation with the wasserstein distance.SIAM Journal on Applied Algebra and Geometry, 8(3):650–685, 2...
-
[5]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttp://www.jstor.org/stable/1969989
ISSN 0003486X. URLhttp://www.jstor.org/stable/1969989. Philipp Nazari, Sebastian Damrich, and Fred A Hamprecht. Geometric autoencoders–what you see is what you decode.arXiv preprint arXiv:2306.17638,
-
[7]
Parametric umap embeddings for represen- tation and semisupervised learning.Neural Computation, 33(11):2881–2907,
11 Published as a conference paper at ICLR 2026 Tim Sainburg, Leland McInnes, and Timothy Q Gentner. Parametric umap embeddings for represen- tation and semisupervised learning.Neural Computation, 33(11):2881–2907,
2026
-
[8]
Zhisheng Xiao, Qing Yan, and Yali Amit. Generative latent flow.arXiv preprint arXiv:1905.10485,
-
[9]
Multi-scale geometric autoencoder.arXiv preprint arXiv:2509.24168,
Qipeng Zhan, Zhuoping Zhou, Zexuan Wang, and Li Shen. Multi-scale geometric autoencoder.arXiv preprint arXiv:2509.24168,
-
[10]
(⇐) ∀x̸=y∈ M , choose δ=d M(x, y), there exists ϵ >0 , such that f is (δ, ϵ)-separated, then dN (f(x), f(y)) dM(x, y) > ϵ.(13) Therefore, dN (f(x), f(y))> ϵ·d M(x, y) =ϵ·δ >0 , i.e
12 Published as a conference paper at ICLR 2026 A THEORETICALPROOFS A.1 PROOF OFTHEOREM1 Proof. (⇐) ∀x̸=y∈ M , choose δ=d M(x, y), there exists ϵ >0 , such that f is (δ, ϵ)-separated, then dN (f(x), f(y)) dM(x, y) > ϵ.(13) Therefore, dN (f(x), f(y))> ϵ·d M(x, y) =ϵ·δ >0 , i.e. f(x)̸=f(y) . So f is an injection. Note that the sufficiency does not require a...
2026
-
[11]
Letγ: (−ε, ε)→ Mbe a smooth curve withγ(0) =xandγ ′(0) =v
(⇒) Suppose f is κ-bi-Lipschitz, ∀x∈ int M, consider a unit vector v∈T xM. Letγ: (−ε, ε)→ Mbe a smooth curve withγ(0) =xandγ ′(0) =v. By the chain rule: (f◦γ) ′(0) =J f(x)v.(29) For|t|< ε, the bi-Lipschitz condition implies that 1 κ ·d M(γ(t), x)≤d N (f(γ(t)), f(x))≤κ·d M(γ(t), x).(30) Through dividing by|t|and takingt→0, we obtain: 1 κ ∥v∥ ≤ ∥J f(x)v∥ ≤κ...
2026
-
[12]
Table 3: Hyperparameter settings for BLAE across all evaluated datasets. Datasets Swiss Roll dSprites MNIST ssREAD λreg 1 2 30 2 λbi-Lip 0.3 0.1 0.1 0.1 κ 1 1.1 2 1.2 ϵ 0.3 0.3 0.6 0.6 B.2 EVALUATIONMETRICS We evaluate the performance of each model using three metrics: mean squared error (MSE), k-NN recall (Sainburg et al., 2021; Kobak et al., 2019), and ...
2021
-
[13]
= Z θ2 θ1 1ds = Z θ2 θ1 p r2(θ) +r ′2(θ)dθ = Z θ2 θ1 ebθ p 1 +b 2dθ = √ 1 +b 2 b (ebθ2 −e bθ1). (44) Fixing the starting point at θ1 = 0 and allowing the negative arc length to be negative, we obtain the arc length as a function ofθ: s(θ) = √ 1 +b 2 b (ebθ −1),(45) which leads to the inverse function: θ(s) = 1 b log( bs√ 1 +b 2 + 1).(46) This yields an is...
2026
-
[14]
All models were trained on the indicated sample sizes, while visualizations use the full set of 10,000 data points
on the Swiss Roll data. All models were trained on the indicated sample sizes, while visualizations use the full set of 10,000 data points. The performance of graph-based methods is highly sensitive to sample density, as the quality of the neighborhood graph—and hence the accuracy of geodesic distance estimation—directly depends on the number of training ...
2026
-
[15]
For MSE and KL metrics, lower values are better; fork-NN, higher values are better
on the Swiss Roll data. For MSE and KL metrics, lower values are better; fork-NN, higher values are better. The best performance for each metric is shown in bold. Measure BLAE GGAE SPAE TAE Diffusion Net GRAE Sample size = 400 MSE(↓) 1.52e-03±1.07e-049.69e-02±7.98e-031.86e-02±6.07e-035.39e-02±2.96e-031.34e-01±2.84e-021.80e-01±3.93e-03k-NN(↑) 9.19e-01±3.10...
2026
-
[16]
better preserve the intrinsic manifold geometry. (a)κ= 1.0 (b)κ= 1.1 (c)κ= 1.2 (d)κ= 1.5 (e)κ= 2.0 (f)κ= 5.0 (g)κ= 10 Figure 10: Sensitivity analysis of κ: 2-D latent representation of Swiss Roll data learned by BLAE with differentκvalues. Separation threshold ϵ.Figure 11 visualizes how latent structure evolves as ϵ varies from 0.2 to 0.8. Low ϵ values (0...
2026
-
[17]
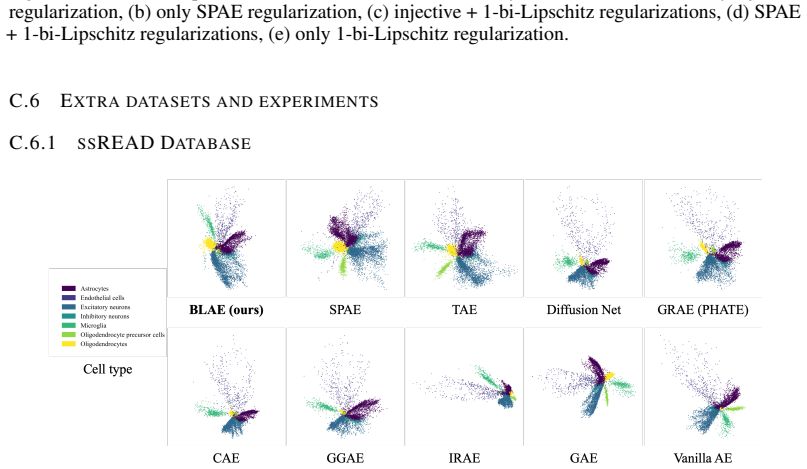
Sequencing was performed using the 10x Genomics Chromium platform. 25 Published as a conference paper at ICLR 2026 Standard preprocessing steps were applied, including quality control, normalization, dimensionality reduction, and unsupervised clustering. The resulting dataset consists of 9,891 cells and 27,801 genes, annotated into seven distinct cell typ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.