Recognition: 1 theorem link
· Lean TheoremImproving Local Feature Matching by Entropy-inspired Scale Adaptability and Flow-endowed Local Consistency
Pith reviewed 2026-05-10 17:45 UTC · model grok-4.3
The pith
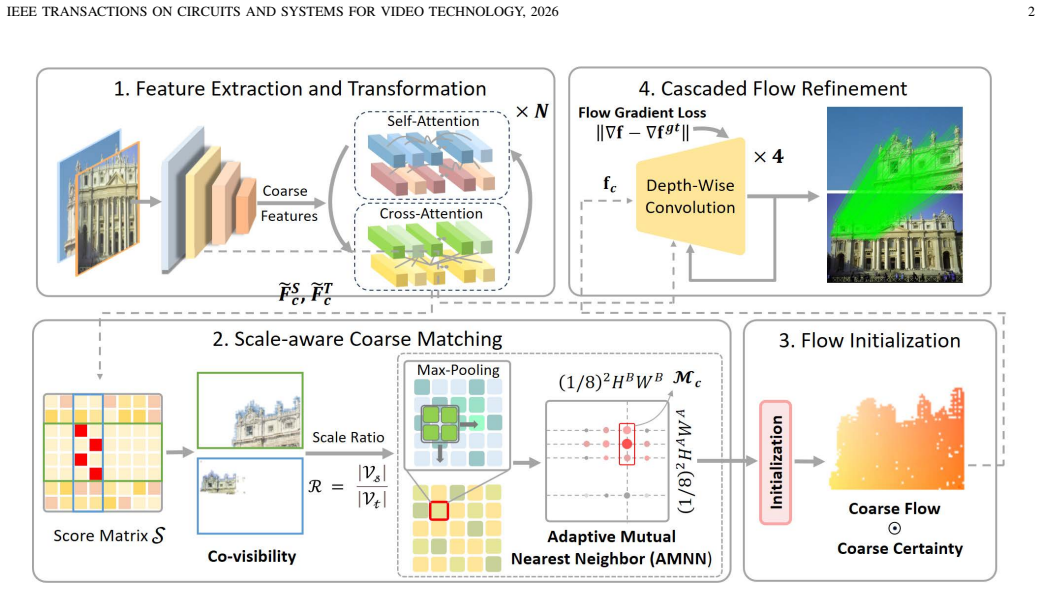
Score matrix hints indicate scale ratios between images, enabling a low-overhead scale-aware matcher, while reformulating fine matching as cascaded flow refinement with gradient loss enforces local consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By observing that the score matrix conceals hints about the scale ratio, a scale-aware matching module is introduced at the coarse stage. At the fine stage, the matching is recast as cascaded flow refinement, with a gradient loss added to promote local consistency in the flow field, resulting in robust and accurate performance on downstream tasks.
What carries the argument
The scale-aware matching module derived from score matrix hints for scale ratio, combined with gradient loss in cascaded flow refinement to enforce local flow consistency.
Load-bearing premise
The hint concealed in the score matrix can be exploited to indicate the scale ratio and that reformulating fine-stage matching as cascaded flow refinement with a gradient loss will enforce useful local consistency without introducing new failure modes
What would settle it
A test where images with large scale differences are matched and the scale-aware module shows no improvement over standard MNN, or where the gradient loss fails to reduce flow inconsistencies, would disprove the effectiveness of these modifications.
Figures







read the original abstract
Recent semi-dense image matching methods have achieved remarkable success, but two long-standing issues still impair their performance. At the coarse stage, the over-exclusion issue of their mutual nearest neighbor (MNN) matching layer makes them struggle to handle cases with scale difference between images. To this end, we comprehensively revisit the matching mechanism and make a key observation that the hint concealed in the score matrix can be exploited to indicate the scale ratio. Based on this, we propose a scale-aware matching module which is exceptionally effective but introduces negligible overhead. At the fine stage, we point out that existing methods neglect the local consistency of final matches, which undermines their robustness. To this end, rather than independently predicting the correspondence for each source pixel, we reformulate the fine stage as a cascaded flow refinement problem and introduce a novel gradient loss to encourage local consistency of the flow field. Extensive experiments demonstrate that our novel matching pipeline, with these proposed modifications, achieves robust and accurate matching performance on downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semi-dense local feature matching suffers from over-exclusion in mutual nearest neighbor matching under scale differences and from neglected local consistency at the fine stage. It proposes a scale-aware matching module that exploits hints in the score matrix to adapt to scale ratios, and reformulates fine-stage matching as cascaded flow refinement with a novel gradient loss to enforce local consistency of the flow field. These modifications are presented as low-overhead, parameter-free additions that yield robust and accurate performance on downstream tasks, supported by extensive experiments.
Significance. If the empirical gains hold under rigorous validation, the work would supply targeted, low-cost fixes to known limitations in semi-dense pipelines, potentially improving reliability in scale-varying scenarios and downstream applications such as pose estimation or reconstruction. The engineering focus and claimed negligible overhead are practical strengths.
major comments (2)
- Abstract: the central claim that the modifications achieve 'robust and accurate matching performance' rests on 'extensive experiments' yet the abstract supplies no quantitative results, baselines, error bars, or dataset details, leaving the strength of evidence for the two modules unverified at the point of first reading.
- The key observation on the score matrix (used to motivate the scale-aware module) and the reformulation of fine-stage matching as cascaded flow with gradient loss are presented as independent engineering additions; no derivation is shown that reduces either improvement to quantities already defined by the base pipeline, making the claimed benefits appear additive rather than derived.
minor comments (3)
- Title: 'Entropy-inspired' appears but the abstract and high-level description do not explain any connection to entropy or how the scale hint is entropy-related; this notation mismatch should be clarified.
- The description of the gradient loss and cascaded flow refinement lacks explicit equations or pseudocode showing how the loss is computed from the flow field and how refinement is cascaded, which would aid reproducibility.
- No mention of failure modes or edge cases introduced by the new modules (e.g., whether the scale adaptation can produce false positives when the score-matrix hint is noisy).
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments on the abstract and the presentation of our contributions. We address each major comment below and have made targeted revisions to improve clarity and substantiation.
read point-by-point responses
-
Referee: Abstract: the central claim that the modifications achieve 'robust and accurate matching performance' rests on 'extensive experiments' yet the abstract supplies no quantitative results, baselines, error bars, or dataset details, leaving the strength of evidence for the two modules unverified at the point of first reading.
Authors: We agree that the abstract would benefit from quantitative anchors to allow immediate evaluation of the claims. In the revised manuscript we have updated the abstract to include key performance highlights from our experiments, such as the reported gains in matching precision and AUC metrics on standard benchmarks, while preserving conciseness. revision: yes
-
Referee: The key observation on the score matrix (used to motivate the scale-aware module) and the reformulation of fine-stage matching as cascaded flow with gradient loss are presented as independent engineering additions; no derivation is shown that reduces either improvement to quantities already defined by the base pipeline, making the claimed benefits appear additive rather than derived.
Authors: The scale-aware module is directly motivated by an observable property of the score matrix produced by the base coarse matcher, which we analyze explicitly in Section 3.1. The fine-stage reformulation and gradient loss address the absence of explicit local consistency constraints in prior per-pixel fine matching, a limitation we identify from the base pipeline's design. These are principled extensions rather than purely additive heuristics; we have expanded the motivation and analysis sections to more clearly trace each addition back to the base pipeline's outputs and shortcomings. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents two targeted engineering modifications to semi-dense matching pipelines: a scale-aware module motivated by an empirical observation on score-matrix hints for scale ratio, and a reformulation of fine-stage matching as cascaded flow refinement using a gradient loss for local consistency. No equations, derivations, or self-citations are shown that reduce these modules or the claimed performance gains to fitted parameters, tautological restatements, or load-bearing prior results by the same authors. The central claims rest on independent motivation from known issues and experimental validation, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The hint concealed in the score matrix can be exploited to indicate the scale ratio
- domain assumption Reformulating fine-stage matching as cascaded flow refinement with a gradient loss encourages useful local consistency
Reference graph
Works this paper leans on
-
[1]
Building rome in a day,
S. Agarwal, Y . Furukawa, N. Snavely, I. Simon, B. Curless, S. M. Seitz, and R. Szeliski, “Building rome in a day,”ICCV, 2009
2009
-
[2]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J. Frahm, “Structure-from-motion revisited,” in CVPR, 2016
2016
-
[3]
Pixel- perfect structure-from-motion with featuremetric refinement,
P. Lindenberger, P.-E. Sarlin, V . Larsson, and M. Pollefeys, “Pixel- perfect structure-from-motion with featuremetric refinement,”ICCV, pp. 5967–5977, 2021
2021
-
[4]
Detector-free structure from motion,
X. He, J. Sun, Y . Wang, S. Peng, Q. Huang, H. Bao, and X. Zhou, “Detector-free structure from motion,” inCVPR, 2024
2024
-
[5]
Sparf: Neural radiance fields from sparse and noisy poses,
P. Truong, M.-J. Rakotosaona, F. Manhardt, and F. Tombari, “Sparf: Neural radiance fields from sparse and noisy poses,” inCVPR, 2023
2023
-
[6]
CorresNeRF: Image correspondence priors for neural radiance fields,
Y . Lao, X. Xu, Z. Cai, X. Liu, and H. Zhao, “CorresNeRF: Image correspondence priors for neural radiance fields,” inNeurIPS, 2023
2023
-
[7]
Mariner: Enhanc- ing novel views by matching rendered images with nearby references,
L. B ¨osiger, M. Dusmanu, M. Pollefeys, and Z. Bauer, “Mariner: Enhanc- ing novel views by matching rendered images with nearby references,” inEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[8]
Joint stroke tracing and correspondence for 2d animation,
H. Mo, C. Gao, and R. Wang, “Joint stroke tracing and correspondence for 2d animation,”ACM Trans. Graph., vol. 43, no. 3, Apr. 2024
2024
-
[9]
Loftr: Detector-free local feature matching with transformers,
J. Sun, Z. Shen, Y . Wang, H. Bao, and X. Zhou, “Loftr: Detector-free local feature matching with transformers,” inCVPR, 2021, pp. 8922– 8931
2021
-
[10]
Match- former: Interleaving attention in transformers for feature matching,
Q. Wang, J. Zhang, K. Yang, K. Peng, and R. Stiefelhagen, “Match- former: Interleaving attention in transformers for feature matching,” in ACCV, 2022
2022
-
[11]
Aspanformer: Detector-free image matching with adaptive span transformer,
H. Chen, Z. Luo, L. Zhou, Y . Tian, M. Zhen, T. Fang, D. Mckinnon, Y . Tsin, and L. Quan, “Aspanformer: Detector-free image matching with adaptive span transformer,” inECCV. Springer, 2022, pp. 20–36
2022
-
[12]
Quadtree attention for vision transformers,
S. Tang, J. Zhang, S. Zhu, and P. Tan, “Quadtree attention for vision transformers,”ICLR, 2022
2022
-
[13]
Adaptive spot-guided transformer for consistent local feature matching,
J. Yu, J. Chang, J. He, T. Zhang, J. Yu, and F. Wu, “Adaptive spot-guided transformer for consistent local feature matching,” inCVPR, 2023, pp. 21 898–21 908
2023
-
[14]
Topicfm: Robust and interpretable topic-assisted feature matching,
K. T. Giang, S. Song, and S.-G. Jo, “Topicfm: Robust and interpretable topic-assisted feature matching,” inAAAI, 2023
2023
-
[15]
Efficient loftr: Semi- dense local feature matching with sparse-like speed,
Y . Wang, X. He, S. Peng, D. Tan, and X. Zhou, “Efficient loftr: Semi- dense local feature matching with sparse-like speed,” inCVPR, 2024, pp. 21 666–21 675
2024
-
[16]
Aslfeat: Learning local features of accurate shape and localization,
Z. Luo, L. Zhou, X. Bai, H. Chen, J. Zhang, Y . Yao, S. Li, T. Fang, and L. Quan, “Aslfeat: Learning local features of accurate shape and localization,” inCVPR, 2020, pp. 6589–6598
2020
-
[17]
D2d: Keypoint extraction with describe to detect approach,
Y . Tian, V . Balntas, T. Ng, A. Barroso-Laguna, Y . Demiris, and K. Miko- lajczyk, “D2d: Keypoint extraction with describe to detect approach,” in ACCV, 2020
2020
-
[18]
SuperGlue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” inCVPR, 2020
2020
-
[19]
LightGlue: Local Feature Matching at Light Speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “LightGlue: Local Feature Matching at Light Speed,” inICCV, 2023
2023
-
[20]
Dkm: Dense kernelized feature matching for geometry estimation,
J. Edstedt, I. Athanasiadis, M. Wadenb ¨ack, and M. Felsberg, “Dkm: Dense kernelized feature matching for geometry estimation,” inCVPR, 2023, pp. 17 765–17 775
2023
-
[21]
RoMa: Robust Dense Feature Matching
J. Edstedt, Q. Sun, G. B ¨okman, M. Wadenb¨ack, and M. Felsberg, “Roma: Revisiting robust losses for dense feature matching,”arXiv preprint arXiv:2305.15404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Pats: Patch area transportation with subdivision for local feature matching,
J. Ni, Y . Li, Z. Huang, H. Li, H. Bao, Z. Cui, and G. Zhang, “Pats: Patch area transportation with subdivision for local feature matching,” CVPR, pp. 17 776–17 786, 2023
2023
-
[23]
Adaptive assignment for geometry aware local feature matching,
D. Huang, Y . Chen, Y . Liu, J. Liu, S. Xu, W. Wu, Y . Ding, F. Tang, and C. Wang, “Adaptive assignment for geometry aware local feature matching,” inCVPR, 2023, pp. 5425–5434
2023
-
[24]
Distinctive image features from scale-invariant key- points,
G. LoweDavid, “Distinctive image features from scale-invariant key- points,”IJCV, 2004
2004
-
[25]
Machine learning for high-speed corner detection,
E. Rosten and T. Drummond, “Machine learning for high-speed corner detection,” inECCV. Springer, 2006, pp. 430–443
2006
-
[26]
Speeded-up robust features (surf),
H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool, “Speeded-up robust features (surf),”CVIU, vol. 110, no. 3, pp. 346–359, 2008
2008
-
[27]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. R. Bradski, “Orb: An efficient alternative to sift or surf,” inICCV, 2011, pp. 2564–2571
2011
-
[28]
Quad- networks: unsupervised learning to rank for interest point detection,
N. Savinov, A. Seki, L. Ladicky, T. Sattler, and M. Pollefeys, “Quad- networks: unsupervised learning to rank for interest point detection,” in CVPR, 2017, pp. 1822–1830
2017
-
[29]
Key.net: Keypoint detection by handcrafted and learned cnn filters,
A. B. Laguna, E. Riba, D. Ponsa, and K. Mikolajczyk, “Key.net: Keypoint detection by handcrafted and learned cnn filters,”ICCV, pp. 5835–5843, 2019
2019
-
[30]
L2-net: Deep learning of discriminative patch descriptor in euclidean space,
Y . Tian, B. Fan, and F. Wu, “L2-net: Deep learning of discriminative patch descriptor in euclidean space,” inCVPR, 2017, pp. 661–669. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , 2026 12
2017
-
[31]
Working hard to know your neighbor’s margins: Local descriptor learning loss,
A. Mishchuk, D. Mishkin, F. Radenovic, and J. Matas, “Working hard to know your neighbor’s margins: Local descriptor learning loss,”NeurIPS, vol. 30, 2017
2017
-
[32]
Sosnet: Second order similarity regularization for local descriptor learning,
Y . Tian, X. Yu, B. Fan, F. Wu, H. Heijnen, and V . Balntas, “Sosnet: Second order similarity regularization for local descriptor learning,” in CVPR, 2019, pp. 11 016–11 025
2019
-
[33]
Beyond cartesian representations for local descriptors,
P. Ebel, A. Mishchuk, K. M. Yi, P. Fua, and E. Trulls, “Beyond cartesian representations for local descriptors,” inICCV, 2019, pp. 253–262
2019
-
[34]
D2-net: A trainable cnn for joint description and detection of local features,
M. Dusmanu, I. Rocco, T. Pajdla, M. Pollefeys, J. Sivic, A. Torii, and T. Sattler, “D2-net: A trainable cnn for joint description and detection of local features,” inCVPR, 2019, pp. 8092–8101
2019
-
[35]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,”CVPRW, 2018
2018
-
[36]
R2d2: Reliable and repeatable detector and descriptor,
J. Revaud, C. R. de Souza, M. Humenberger, and P. Weinzaepfel, “R2d2: Reliable and repeatable detector and descriptor,” inNeurIPS, 2019
2019
-
[37]
Rwbd: Learning robust weighted binary descriptor for image matching,
Z. Huang, Z. Wei, and G. Zhang, “Rwbd: Learning robust weighted binary descriptor for image matching,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 7, pp. 1553–1564, 2018
2018
-
[38]
Learning general descriptors for image matching with regression feedback,
Y . Rao, Y . Ju, C. Li, E. Rigall, J. Yang, H. Fan, and J. Dong, “Learning general descriptors for image matching with regression feedback,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 11, pp. 6693–6707, 2023
2023
-
[39]
Tcdesc: Learning topology consistent descriptors for image matching,
H. Pan, Y . Chen, Z. He, F. Meng, and N. Fan, “Tcdesc: Learning topology consistent descriptors for image matching,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 5, pp. 2845– 2855, 2022
2022
-
[40]
Learning to reduce scale differences for large-scale invariant image matching,
Y . Fu, P. Zhang, B. Liu, Z. Rong, and Y . Wu, “Learning to reduce scale differences for large-scale invariant image matching,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 3, pp. 1335– 1348, 2023
2023
-
[41]
Msga-net: Progressive feature matching via multi-layer sparse graph attention,
Z. Gong, G. Xiao, Z. Shi, R. Chen, and J. Yu, “Msga-net: Progressive feature matching via multi-layer sparse graph attention,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 5765–5775, 2024
2024
-
[42]
Contextmatcher: Detector-free feature matching with cross-modality context,
D. Li and S. Du, “Contextmatcher: Detector-free feature matching with cross-modality context,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 9, pp. 7922–7934, 2024
2024
-
[43]
Dgc-net: Dense geometric correspondence network,
I. Melekhov, A. Tiulpin, T. Sattler, M. Pollefeys, E. Rahtu, and J. Kan- nala, “Dgc-net: Dense geometric correspondence network,” inWACV, 2019, pp. 1034–1042
2019
-
[44]
Learning accurate dense correspondences and when to trust them,
P. Truong, M. Danelljan, L. Van Gool, and R. Timofte, “Learning accurate dense correspondences and when to trust them,” inCVPR, 2021, pp. 5714–5724
2021
-
[45]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y . Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features withou...
2023
-
[46]
Neighbourhood consensus networks,
I. Rocco, M. Cimpoi, R. Arandjelovi ´c, A. Torii, T. Pajdla, and J. Sivic, “Neighbourhood consensus networks,” inNeurIPS, 2018
2018
-
[47]
Disk: Learning local features with policy gradient,
M. Tyszkiewicz, P. Fua, and E. Trulls, “Disk: Learning local features with policy gradient,”NeurIPS, 2020
2020
-
[48]
Grounding image matching in 3d with mast3r,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inECCV, 2024
2024
-
[49]
Dual-resolution correspondence networks,
X. Li, K. Han, S. Li, and V . Prisacariu, “Dual-resolution correspondence networks,” inNeurIPS, 2020
2020
-
[50]
Jamma: Ultra-lightweight local feature matching with joint mamba,
X. Lu and S. Du, “Jamma: Ultra-lightweight local feature matching with joint mamba,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[51]
Comatch: Dynamic covisibility-aware transformer for bilateral subpixel-level semi-dense image matching,
Z. Li, Y . Lu, L. Tang, S. Zhang, and J. Ma, “Comatch: Dynamic covisibility-aware transformer for bilateral subpixel-level semi-dense image matching,” inICCV, 2025
2025
-
[52]
Repvgg: Making vgg-style convnets great again,
X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, and J. Sun, “Repvgg: Making vgg-style convnets great again,” inCVPR, 2021, pp. 13 733– 13 742
2021
-
[53]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Su, Y . Lu, S. Pan, B. Wen, and Y . Liu, “Roformer: Enhanced trans- former with rotary position embedding,”ArXiv, vol. abs/2104.09864, 2021
work page internal anchor Pith review arXiv 2021
-
[54]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inCVPR, 2017
2017
-
[55]
Megadepth: Learning single-view depth predic- tion from internet photos,
Z. Li and N. Snavely, “Megadepth: Learning single-view depth predic- tion from internet photos,” inCVPR, 2018, pp. 2041–2050
2018
-
[56]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inCVPR, 2017, pp. 5828–5839
2017
-
[57]
Efficient neighbourhood consensus networks via submanifold sparse convolutions,
I. Rocco, R. Arandjelovi ´c, and J. Sivic, “Efficient neighbourhood consensus networks via submanifold sparse convolutions,” inECCV. Springer, 2020, pp. 605–621
2020
-
[58]
Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors,
V . Balntas, K. Lenc, A. Vedaldi, and K. Mikolajczyk, “Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors,” inCVPR, 2017, pp. 5173–5182
2017
-
[59]
Inloc: Indoor visual localization with dense matching and view synthesis,
H. Taira, M. Okutomi, T. Sattler, M. Cimpoi, M. Pollefeys, J. Sivic, T. Pajdla, and A. Torii, “Inloc: Indoor visual localization with dense matching and view synthesis,” inCVPR, 2018, pp. 7199–7209
2018
-
[60]
Benchmarking 6dof outdoor visual localization in changing conditions,
T. Sattler, W. Maddern, C. Toft, A. Torii, L. Hammarstrand, E. Stenborg, D. Safari, M. Okutomi, M. Pollefeys, J. Sivicet al., “Benchmarking 6dof outdoor visual localization in changing conditions,” inCVPR, 2018, pp. 8601–8610. Ke Jinreceived the B.S. degree from the College of Automation at Southeast University, Nanjing, China, in 2024. He is currently pu...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.