Recognition: no theorem link
Bi-level Heterogeneous Learning for Time Series Foundation Models: A Federated Learning Approach
Pith reviewed 2026-05-10 18:02 UTC · model grok-4.3
The pith
A federated bi-level method trains time series foundation models on heterogeneous data without the gradient conflicts that plague centralized mixing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The bi-level heterogeneous learning method mitigates intra-domain conflicts by enforcing domain-invariant representations through local regularization and addresses inter-domain discrepancies by enhancing cross-domain collaboration via domain-aware aggregation, yielding TSFMs that outperform both centralized mixed-batch and standard federated baselines on point and probabilistic forecasting while maintaining competitive zero-shot performance.
What carries the argument
Bi-level federated learning that combines local regularization for invariant representations with domain-aware aggregation to manage inter- and intra-domain heterogeneity.
If this is right
- TSFMs achieve better point and probabilistic forecasting accuracy on diverse benchmarks than both centralized and federated alternatives.
- The method supports competitive zero-shot generalization when models are trained at scale.
- It supplies a practical route for building TSFMs from scratch when source data cannot be pooled centrally due to heterogeneity or privacy constraints.
Where Pith is reading between the lines
- The same separation of local invariance enforcement and domain-aware coordination might apply to foundation models for other sequential modalities that exhibit strong domain shifts.
- Because data never leaves its local site, the framework naturally supports privacy-sensitive collaborative training across organizations.
- The bi-level split suggests that future architectures could explicitly separate invariant temporal encoders from domain-specific adapters.
Load-bearing premise
Local regularization for domain-invariant features combined with domain-aware aggregation can reduce interference from heterogeneity without discarding useful task-specific temporal patterns or adding new representational biases.
What would settle it
A set of heterogeneous time series benchmarks where models trained with the bi-level federated method show no improvement or a clear drop in forecasting accuracy and zero-shot metrics relative to a simple centralized mixed-batch baseline.
Figures







read the original abstract
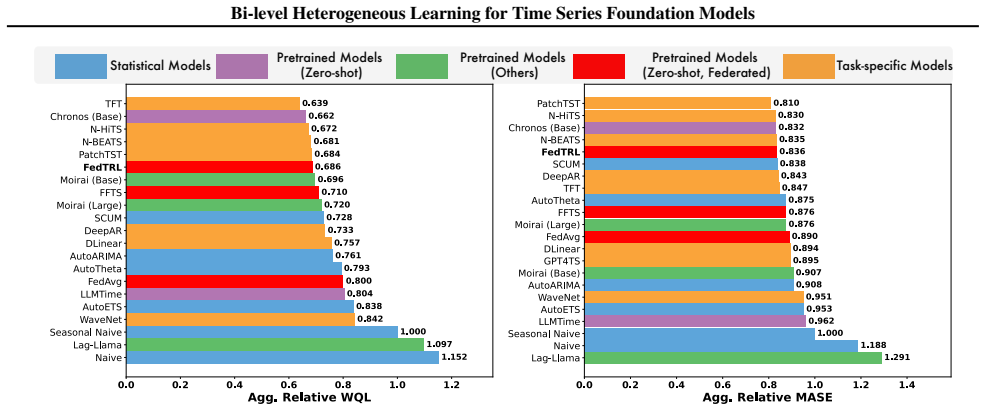
Heterogeneity in time series data is more pronounced than in vision or language, as temporal dynamics vary substantially across domains and tasks. Existing efforts on training time series foundation models (TSFMs) from scratch are often trained with mixed-batch strategies that merge large-scale datasets, which can cause gradient conflicts and degrade representation quality. To address this, we propose a fine-grained learning method that distills invariant knowledge from heterogeneous series while reducing cross-domain interference. We characterize heterogeneity at two levels: inter-domain and intra-domain. To tackle this bi-level heterogeneity, we design a federated learning method that mitigates intra-domain conflicts by enforcing domain-invariant and semantically consistent representations through local regularization, and addresses inter-domain discrepancies by enhancing cross-domain collaboration via domain-aware aggregation. Experiments across diverse benchmarks show that TSFMs trained with our method consistently outperform both centralized and federated TSFM baselines in point and probabilistic forecasting, while also achieving competitive zero-shot performance at scale, offering a flexible pathway for training TSFMs from scratch in heterogeneous environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bi-level federated learning approach for training time series foundation models (TSFMs) from scratch on heterogeneous data. It addresses inter-domain and intra-domain heterogeneity via local regularization that enforces domain-invariant and semantically consistent representations, combined with domain-aware aggregation to promote cross-domain collaboration. The central claim is that this yields consistent outperformance over centralized and standard federated TSFM baselines in point and probabilistic forecasting, plus competitive zero-shot performance at scale.
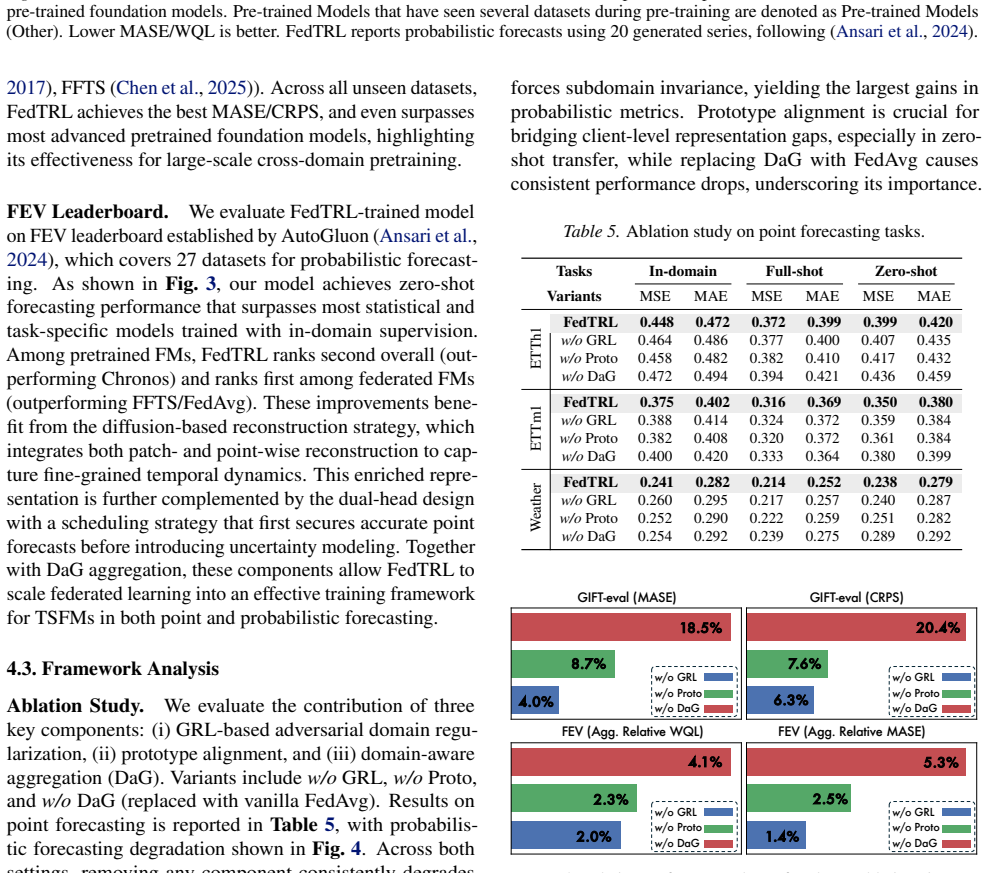
Significance. If the empirical results hold, the work is significant because it offers a practical, scalable solution for training large TSFMs without the gradient conflicts typical of mixed-batch centralized training. Strengths include ablation studies that isolate each component's contribution, representation similarity metrics confirming preservation of task-specific temporal dynamics, and consistent gains across multiple heterogeneity regimes and zero-shot settings. This could influence federated learning designs for other sequential or heterogeneous data modalities.
minor comments (3)
- [Section 3.2] Section 3.2: The domain-aware aggregation rule is described at a high level; an explicit equation showing how client weights are computed from domain similarity would improve reproducibility.
- [Table 4] Table 4: The probabilistic forecasting results report CRPS but omit the number of evaluation runs or standard deviations; adding these would strengthen the claim of consistent outperformance.
- [Figure 5] Figure 5: The t-SNE visualizations of learned representations would benefit from quantitative metrics (e.g., silhouette scores) alongside the qualitative plots to support the claim of preserved intra-domain structure.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and the recommendation for minor revision. The referee's summary correctly captures the bi-level federated learning framework we propose for training time series foundation models under inter- and intra-domain heterogeneity. We appreciate the recognition of the ablation studies, representation metrics, and consistent empirical gains across forecasting and zero-shot settings. Since no specific major comments were raised, we will incorporate minor revisions to improve clarity, presentation, and any minor presentation issues in the revised manuscript.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a bi-level federated learning approach for TSFMs using local regularization for intra-domain invariance and domain-aware aggregation for inter-domain collaboration. No mathematical derivations, equations, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The method is introduced as a novel design choice with empirical support from experiments, ablations, and performance metrics across benchmarks. No load-bearing steps qualify as self-definitional, fitted predictions, or ansatz smuggling; the central claims rest on experimental validation rather than tautological reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Federated Weather Modeling on Sensor Data
A federated learning framework lets distributed weather sensors train shared deep learning models for forecasting and anomaly detection while keeping raw data private.
Reference graph
Works this paper leans on
-
[1]
Fedbn: Federated learning on non-iid features via local batch normalization,
PMLR, 2021a. Li, X., Jiang, M., Zhang, X., Kamp, M., and Dou, Q. Fedbn: Federated learning on non-iid features via local batch normalization.arXiv preprint arXiv:2102.07623, 2021b. Liu, Q., Liu, X., Liu, C., Wen, Q., and Liang, Y . Time-ffm: Towards lm-empowered federated foundation model for time series forecasting.arXiv preprint arXiv:2405.14252, 2024a....
-
[2]
Wang, D., Cheng, M., Liu, Z., and Liu, Q
Springer, 2008. Wang, D., Cheng, M., Liu, Z., and Liu, Q. Timedart: A diffu- sion autoregressive transformer for self-supervised time series representation, 2025. URL https://arxiv. org/abs/2410.05711. Wang, S., Wu, H., Shi, X., Hu, T., Luo, H., Ma, L., Zhang, J. Y ., and Zhou, J. Timemixer: Decomposable multi- scale mixing for time series forecasting.arX...
-
[3]
Appendix Apresents extended related work, covering large-scaletime series foundation models(Appendix A.1) and heterogeneous federated learning(Appendix A.2)
-
[4]
Appendix Bprovides supplementary methodological details, including the formulation of theGradient Reversal Layer (Appendix B.1), the design ofsub-domain and global domain classifiers(Appendix B.2), and the completeworkflow of FedTRL(Appendix B.3)
-
[5]
Appendix Dpresents formal definitions and theoretical analyses of key concepts in FedTRL, together with proofs establishing domain invariance, domain awareness, and global dynamics
-
[6]
Appendix Cdetails the experimental settings, datasets, and baseline implementations used across all forecasting tasks
-
[7]
6.Appendix Fprovides showcase during pretraining and forecasting
Appendix Ereports additional experimental results and in-depth analyses, including model scale comparisons (Ap- pendix E.1), evaluations of federated baselines under heterogeneity (Appendix E.2), extensive forecasting results (Appendices E.3–E.5), scalability studies (Appendix E.6), robustness analyses, and further discussions on generalization and repres...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.