Recognition: 1 theorem link
· Lean TheoremTurn Your Face Into An Attack Surface: Screen Attack Using Facial Reflections in Video Conferencing
Pith reviewed 2026-05-10 17:47 UTC · model grok-4.3
The pith
Facial reflections in video calls leak detailed on-screen application activity to observers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
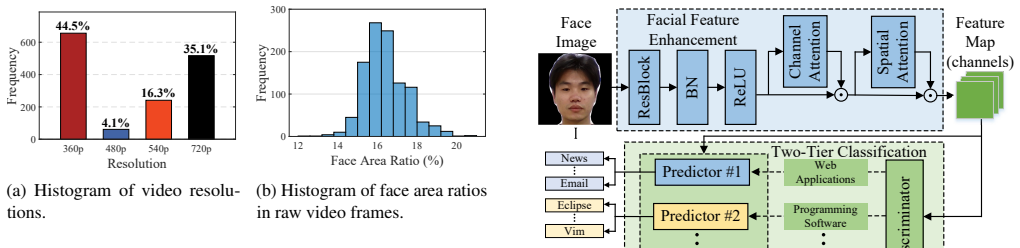
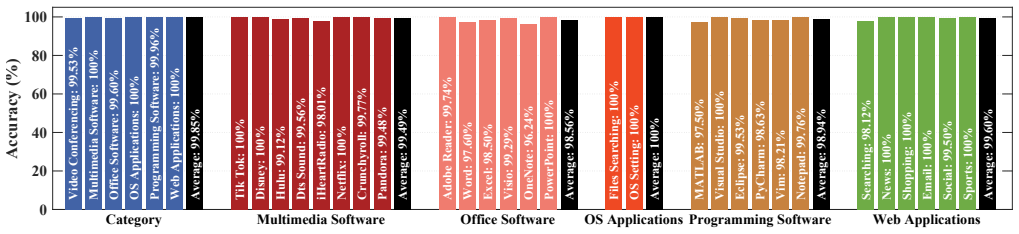
FaceTell recovers fine-grained application activity by analyzing optical variations reflected from the user's face during video conferencing. The face receives light from both the display and the room, then redirects content-dependent changes back to the camera. Experiments with 24 subjects, 13 indoor settings, three laptop models, and four conferencing platforms produced 99.32 percent accuracy across more than 12 hours of video for 28 applications, with resilience to common practical disturbances.
What carries the argument
The optical reflection of screen-emitted and ambient light from the human face, which encodes and carries on-screen content variations into the video conferencing camera feed for classification.
If this is right
- Observers of a video call can determine the exact applications open on a participant's screen without any direct access.
- The leakage occurs across multiple laptop brands and major conferencing platforms under everyday indoor conditions.
- User movement and ambient light changes do not stop reliable extraction of application activity.
- Countermeasures must be added to video systems to limit how much screen light reaches and reflects from the face.
Where Pith is reading between the lines
- Video call participants in sensitive environments may need to control room lighting or screen brightness to reduce the reflection channel.
- The same reflection principle could allow inference of other screen details such as document text or browser tabs if the classifier is extended.
- Conferencing software could incorporate real-time filters that detect and suppress facial reflection patterns before transmission.
- Similar optical side channels may appear in other camera-based remote collaboration tools where faces are filmed near displays.
Load-bearing premise
Subtle light variations reflected from the face stay detectable and distinguishable in ordinary video call conditions even when lighting, head position, camera quality, and background change.
What would settle it
A controlled test in a typical indoor video call with standard room lighting and normal user movement that drops FaceTell's application identification accuracy to near-random levels.
Figures















read the original abstract
In video conferencing, human faces serve as the primary visual focal points, playing multifaceted roles that enhance visual communication and emotional connection. However, we argue that a human face is also a side channel, which can unwittingly leak on-screen information through online video feeds. To demonstrate this, we conduct feasibility studies, which reveal that, illuminated by both ambient light and light emitted from displays, the human face can reflect optical variations of different on-screen content. The paper then proposes FaceTell, a novel side-channel attack system that eavesdrops on fine-grained application activities from pervasive yet subtle facial reflections during video conferencing. We implement FaceTell in a real-world testbed with three different brands of laptops and four mainstream video conferencing platforms. FaceTell is then evaluated with 24 human subjects across 13 unique indoor environments. With more than 12 hours of video data, FaceTell achieves a high accuracy of 99.32% for eavesdropping on 28 popular applications and is resilient to many practical impact factors. Finally, potential countermeasures are proposed to mitigate this new attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FaceTell, a side-channel attack exploiting optical reflections from a user's face (illuminated by ambient light and screen emissions) during video conferencing to eavesdrop on on-screen application activity. It reports feasibility studies confirming detectable reflections, followed by a real-world implementation and evaluation across three laptop brands, four video platforms, 24 subjects, 13 indoor environments, and over 12 hours of video data, claiming 99.32% accuracy in classifying 28 popular applications while asserting resilience to lighting, movement, camera quality, and background variations.
Significance. If the empirical results hold under the described conditions, this work identifies a novel and practical side-channel in ubiquitous video conferencing tools, extending the literature on optical and visual side channels beyond traditional screen emanations or acoustic leaks. The scale of the multi-device, multi-subject, multi-environment testbed provides concrete evidence of feasibility and strengthens the case for considering facial reflections as an attack surface, which could motivate new privacy-preserving features in conferencing software.
minor comments (2)
- The abstract states concrete accuracy figures and resilience claims but omits any reference to the feature extraction pipeline, classifier architecture, or statistical controls (e.g., error bars, cross-validation scheme, or explicit handling of head-pose/lighting confounders); adding one sentence summarizing these would improve clarity without altering the central narrative.
- Section describing the testbed (multi-laptop, multi-platform, 24 subjects, 13 environments) would benefit from an explicit statement of how ground-truth application labels were obtained and synchronized with the video streams to allow independent reproduction.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment of our work on FaceTell. We appreciate the recognition that the multi-device, multi-subject, multi-environment evaluation provides concrete evidence of a novel optical side-channel in video conferencing. As the report contains no specific major comments, we have no points requiring rebuttal and will address any minor revisions in the updated manuscript.
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The manuscript describes a side-channel attack implemented and evaluated via real-world testbed experiments (three laptops, four platforms, 24 subjects, 13 environments, >12 hours of video). No equations, parameter fitting, or derivation chain appear in the provided text. The 99.32% accuracy is reported as a measured outcome from collected data, not derived from or reduced to any internal definition or self-citation. Feasibility studies on illumination and resilience claims are addressed by explicit experimental variation rather than by construction. This is a standard empirical demonstration with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleartheoretical modeling ... Phong reflection model ... diffuse and specular reflections ... two-tier classification model ... heuristic label correction algorithm
Reference graph
Works this paper leans on
-
[1]
Technical guide, Labsphere Inc., 2001
The radiometry of light emitting diodes. Technical guide, Labsphere Inc., 2001. https://www.labspher e.com/wp-content/uploads/2021/09/Radiometry-of-L ight-Emitting-Diodes.pdf
2001
-
[2]
Faisal R Al-Osaimi, Mohammed Bennamoun, and Aj- mal Mian. Illumination normalization of facial images by reversing the process of image formation.Machine Vision and Applications, 22(6):899–911, 2011. https://li nk.springer.com/article/10.1007/s00138-010-0309-5
-
[3]
Tempest in a teapot: Compromising reflections revisited
Michael Backes, Tongbo Chen, Markus Dürmuth, Hen- drik PA Lensch, and Martin Welk. Tempest in a teapot: Compromising reflections revisited. InProceedings of the IEEE Symposium on Security and Privacy (SP), pages 315–327, 2009. https://ieeexplore.ieee.org/docu ment/5207653
-
[4]
Compromising reflections-or-how to read LCD monitors around the corner
Michael Backes, Markus Dürmuth, and Dominique Un- ruh. Compromising reflections-or-how to read LCD monitors around the corner. InProceedings of the IEEE Symposium on Security and Privacy (SP), pages 158– 169, 2008. https://ieeexplore.ieee.org/document/45311 51
2008
-
[5]
Average Session Duration By Industry,
Evan Bailyn. Average Session Duration By Industry,
-
[6]
https://firstpagesage.com/reports/average-session -duration-by-industry/
-
[7]
Principles of shape from specular reflection.Measurement, 43(10):1305– 1317, 2010
Jonathan Balzer and Stefan Werling. Principles of shape from specular reflection.Measurement, 43(10):1305– 1317, 2010. https://www.sciencedirect.com/science/arti cle/abs/pii/S0263224110001570
2010
-
[8]
Stefano Cecconello, Alberto Compagno, Mauro Conti, Daniele Lain, and Gene Tsudik. Skype & Type: Key- board eavesdropping in V oice-over-IP.ACM Transac- tions on Privacy and Security, 22(4):1–34, 2019. https: //dl.acm.org/doi/10.1145/3365366
-
[9]
Toward proper eval- uation of light dose in indoor office environment by frontal lux meter.Energy Procedia, 122:835–840, 2017
Maíra Vieira Dias, Ali Motamed, Paulo Sergio Scaraz- zato, and Jean-Louis Scartezzini. Toward proper eval- uation of light dose in indoor office environment by frontal lux meter.Energy Procedia, 122:835–840, 2017. https://www.sciencedirect.com/science/article/pii/S1 87661021733148X?ref=pdf_download&fr=RR-2&rr= 9ac48880bc91a9b5
2017
-
[10]
3D morphable face models—past, present, and future.ACM Transactions on Graphics, 39(5):1–38,
Bernhard Egger, William AP Smith, Ayush Tewari, Ste- fanie Wuhrer, Michael Zollhoefer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romd- hani, et al. 3D morphable face models—past, present, and future.ACM Transactions on Graphics, 39(5):1–38,
-
[11]
https://dl.acm.org/doi/10.1145/3395208
-
[12]
No training hurdles: Fast training-agnostic attacks to infer your typing
Song Fang, Ian Markwood, Yao Liu, Shangqing Zhao, Zhuo Lu, and Haojin Zhu. No training hurdles: Fast training-agnostic attacks to infer your typing. InPro- ceedings of the ACM Conference on Computer and Com- munications Security (CCS), page 1747–1760, 2018. https://dl.acm.org/doi/10.1145/3243734.3243755
-
[13]
Synesthesia: Detecting screen content via re- mote acoustic side channels
Daniel Genkin, Mihir Pattani, Roei Schuster, and Eran Tromer. Synesthesia: Detecting screen content via re- mote acoustic side channels. InProceedings of the IEEE Symposium on Security and Privacy (SP), pages 853– 869, 2019. https://www.computer.org/csdl/proceeding s-article/sp/2019/666000a853/1dlwjC6dIT6
2019
-
[14]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial exam- ples.arXiv:1412.6572, 2014. https://arxiv.org/pdf/1412 .6572
work page internal anchor Pith review arXiv 2014
-
[15]
A threat for tablet PCs in public space: Remote visualization of screen im- ages using em emanation
Yuichi Hayashi, Naofumi Homma, Mamoru Miura, Takafumi Aoki, and Hideaki Sone. A threat for tablet PCs in public space: Remote visualization of screen im- ages using em emanation. InProceedings of the ACM Conference on Computer and Communications Security (CCS), pages 954–965, 2014. https://dl.acm.org/doi/10. 1145/2660267.2660292
-
[16]
Mask R-CNN
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2961–2969, 2017. https://openaccess.thecvf.com/ content_ICCV_2017/papers/He_Mask_R-CNN_ICC V_2017_paper.pdf
2017
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 770–778,
- [18]
-
[19]
Zoom user statistics 2024 — market share & revenue, 2024
Naveen Kumar. Zoom user statistics 2024 — market share & revenue, 2024. http://pages.cs.wisc.edu/~remzi /OSTEP/
2024
-
[20]
Wavespy: Remote and through-wall screen attack via mmWave sensing
Zhengxiong Li, Fenglong Ma, Aditya Singh Rathore, Zhuolin Yang, Baicheng Chen, Lu Su, and Wenyao Xu. Wavespy: Remote and through-wall screen attack via mmWave sensing. InProceedings of the IEEE Sym- posium on Security and Privacy (SP), pages 217–232,
- [21]
-
[22]
Private Eye: On the lim- its of textual screen peeking via eyeglass reflections in video conferencing
Yan Long, Chen Yan, Shilin Xiao, Shivan Prasad, Wenyuan Xu, and Kevin Fu. Private Eye: On the lim- its of textual screen peeking via eyeglass reflections in video conferencing. InProceedings of the IEEE Sympo- sium on Security and Privacy (SP), pages 3432–3449,
-
[23]
https://www.computer.org/csdl/proceedings-artic le/sp/2023/933600a870/1OXGUMtuJLa
2023
-
[24]
Eavesdropping mobile app activity via radio- frequency energy harvesting
Tao Ni, Guohao Lan, Jia Wang, Qingchuan Zhao, and Weitao Xu. Eavesdropping mobile app activity via radio- frequency energy harvesting. InProceedings of the USENIX Security Symposium (USENIX Security), pages 3511–3528, 2023. https://www.usenix.org/system/files /usenixsecurity23-ni.pdf
2023
-
[25]
Do users write more insecure code with AI assistants?
Tao Ni, Xiaokuan Zhang, and Qingchuan Zhao. Re- covering fingerprints from in-display fingerprint sen- sors via electromagnetic side channel. InProceedings of the ACM Conference on Computer and Communi- cations Security (CCS), pages 253–267, 2023. https: //dl.acm.org/doi/10.1145/3576915.3623153
-
[26]
Illumination for computer generated pictures
Bui Tuong Phong. Illumination for computer generated pictures. InSeminal graphics: pioneering efforts that shaped the field, pages 95–101. 1998. http://www.cs.n orthwestern.edu/~ago820/cs395/Papers/Phong_1975. pdf
1998
-
[27]
Digital Devices and Your Eyes, 2025
Daniel Porter. Digital Devices and Your Eyes, 2025. https://www.aao.org/eye-health/tips-prevention/digita l-devices-your-eyes
2025
-
[28]
iSpy: automatic reconstruction of typed input from com- promising reflections
Rahul Raguram, Andrew M White, Dibyendusekhar Goswami, Fabian Monrose, and Jan-Michael Frahm. iSpy: automatic reconstruction of typed input from com- promising reflections. InProceedings of the ACM con- ference on Computer and Communications Security (CCS), pages 527–536, 2011. https://dl.acm.org/d oi/10.1145/2046707.2046769
-
[29]
René Riedl. On the stress potential of videoconferenc- ing: definition and root causes of Zoom fatigue.Elec- tronic Markets, 32(1):153–177, 2022. https://link.sprin ger.com/article/10.1007/s12525-021-00501-3
-
[30]
LED directivity measurement in situ
Linas Svilainis. LED directivity measurement in situ. Measurement, 41(6):647–654, 2008. https://www.scie ncedirect.com/science/article/abs/pii/S0263224107000 917
2008
-
[31]
Numerical comparison of LED directivity approximation functions for video displays.Displays, 31(4-5):196–204, 2010
Linas Svilainis and Vytautas Dumbrava. Numerical comparison of LED directivity approximation functions for video displays.Displays, 31(4-5):196–204, 2010. https://www.sciencedirect.com/science/article/abs/pii/ S0141938210000661
2010
-
[32]
Illuminance - Recommended Light Levels, 2004
The Engineering ToolBox. Illuminance - Recommended Light Levels, 2004. https://www.engineeringtoolbox.c om/light-level-rooms-d_708.html
2004
-
[33]
Rapid object detec- tion using a boosted cascade of simple features
Paul Viola and Michael Jones. Rapid object detec- tion using a boosted cascade of simple features. In Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages I–I, 2001. https://ieeexplore.ieee.org/document/990517
2001
-
[34]
attention
Yan Wang, Yi Liu, Shijie Zhao, Junlin Li, and Li Zhang. CAMixerSR: Only details need more "attention". InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 25837–25846,
-
[35]
https://openaccess.thecvf.com/content/CVPR20 24/papers/Wang_CAMixerSR_Only_Details_Need_M ore_Attention_CVPR_2024_paper.pdf
-
[36]
The proof is in the glare: On the privacy risk posed by eyeglasses in video calls
Hassan Wasswa and Abdul Serwadda. The proof is in the glare: On the privacy risk posed by eyeglasses in video calls. InProceedings of the 2022 ACM on Inter- national Workshop on Security and Privacy Analytics, pages 46–54, 2022. https://dl.acm.org/doi/abs/10.1145 /3510548.3519378
-
[37]
Zachary Weinberg, Eric Y Chen, Pavithra Ramesh Ja- yaraman, and Collin Jackson. I still know what you visited last summer: Leaking browsing history via user interaction and side channel attacks. In2011 IEEE Sym- posium on Security and Privacy, pages 147–161, 2011. https://ieeexplore.ieee.org/document/5958027
-
[38]
CBAM: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. CBAM: Convolutional block attention module. InProceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018. https: //openaccess.thecvf.com/content_ECCV_2018/papers /Sanghyun_Woo_Convolutional_Block_Attention_EC CV_2018_paper.pdf
2018
-
[39]
Seeing double: Reconstruct- ing obscured typed input from repeated compromising reflections
Yi Xu, Jared Heinly, Andrew M White, Fabian Monrose, and Jan-Michael Frahm. Seeing double: Reconstruct- ing obscured typed input from repeated compromising reflections. InProceedings of the ACM conference on Computer and Communications Security (CCS), pages 1063–1074, 2013. https://dl.acm.org/doi/10.1145/250 8859.2516709
work page doi:10.1145/250 2013
-
[40]
Study of human visual comfort based on sudden vertical illuminance changes.Build- ings, 12(8):1127, 2022
Jiuhong Zhang, Kunjie Lv, Xiaoqian Zhang, Mingxiao Ma, and Jiahui Zhang. Study of human visual comfort based on sudden vertical illuminance changes.Build- ings, 12(8):1127, 2022. https://www.mdpi.com/2075-5 309/12/8/1127. A Details of Implementation A.1 Screenshots of Selected Applications Multimedia: 1 to 8, Web Application: 9 to 14. OS Application: 1 to...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.