Recognition: 2 theorem links
· Lean TheoremTEC: A Collection of Human Trial-and-error Trajectories for Problem Solving
Pith reviewed 2026-05-10 18:48 UTC · model grok-4.3
The pith
A dataset of human trial-and-error trajectories shows people solve problems more effectively than large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
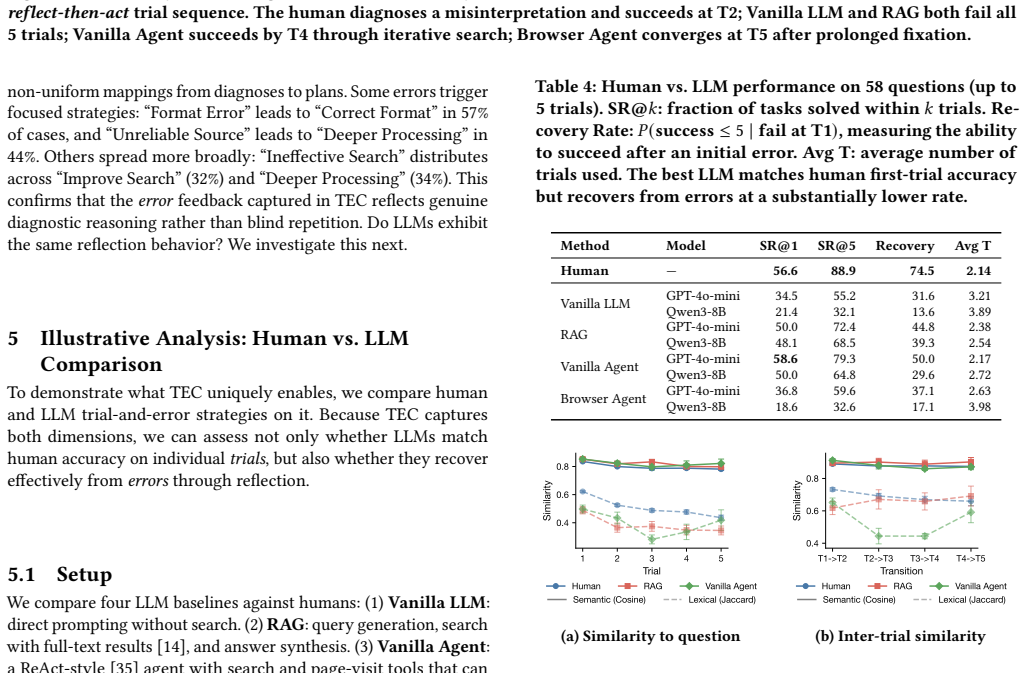
We introduce the Trial-and-Error Collection (TEC) consisting of 5,370 trajectories and reflections from humans solving 58 tasks. The data shows humans achieve substantially higher accuracy than LLMs, which demonstrates that humans are more effective in trial-and-error than LLMs.
What carries the argument
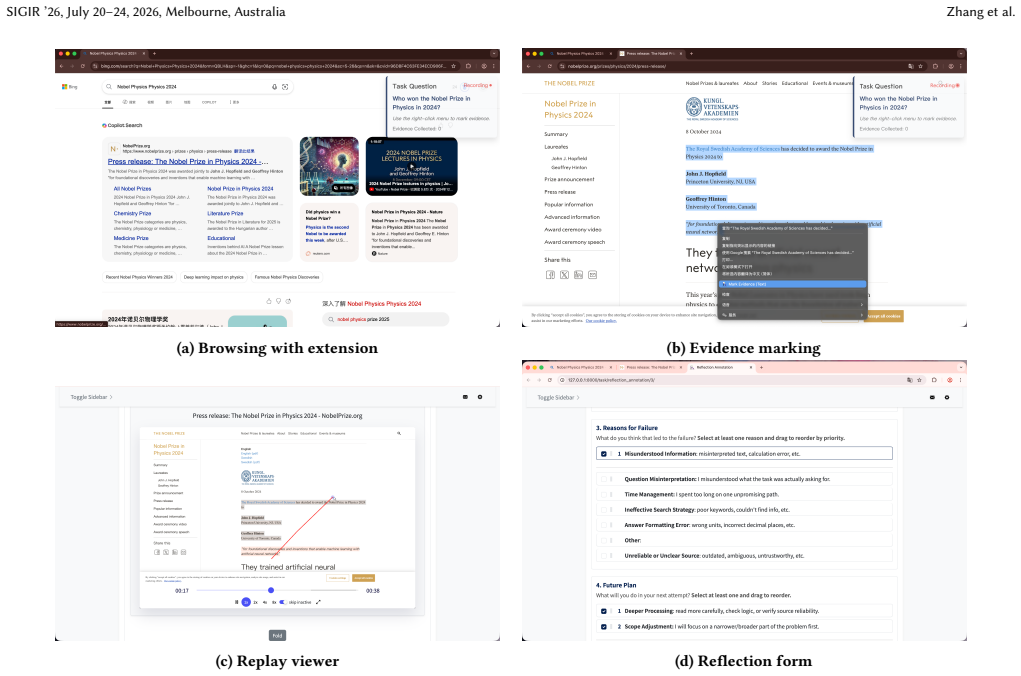
The TEC annotation platform and dataset that records complete multi-trial trajectories together with post-error reflections on web-based problem-solving tasks.
If this is right
- The trajectories can serve as training data for AI systems to acquire more human-like trial-and-error strategies.
- The platform supports collection of additional data on new tasks to expand coverage.
- Error reflections provide examples that could improve how AI systems respond to and learn from failures.
- The dataset establishes a benchmark for measuring future improvements in AI trial-and-error performance.
Where Pith is reading between the lines
- Extracting common patterns from human reflections could yield targeted techniques to enhance LLM prompting for iterative tasks.
- The data may prove especially useful for training models in domains such as coding or research where repeated testing is central.
- The observed gap indicates that persistent, self-directed exploration across attempts remains a missing capability in current models.
Load-bearing premise
The selected tasks, participant pool, and LLM testing setup produce a fair and generalizable comparison of trial-and-error effectiveness between humans and models.
What would settle it
Evaluating LLMs on the exact same 58 tasks using a comparable multi-attempt setup with error feedback and measuring whether they reach or surpass human accuracy.
Figures






read the original abstract
Trial-and-error is a fundamental strategy for humans to solve complex problems and a necessary capability for Artificial Intelligence (AI) systems operating in real-world environments. Although several trial-and-error AI techniques have recently been proposed, most of them rely on simple heuristics designed by researchers and achieve limited performance gains. The core issue is the absence of appropriate data: current models cannot learn from detailed records of how humans actually conduct trial-and-error in practice. To address this gap, we introduce a data annotation platform and a corresponding dataset, termed Trial-and-Error Collection (TEC). The platform records users' complete trajectories across multiple trials and collects their reflections after receiving error feedback. Using this platform, we record the problem-solving processes of 46 participants on 58 tasks, resulting in 5,370 trial trajectories along with error reflections across 41,229 webpages. With this dataset, we observe that humans achieve substantially higher accuracy compared to LLMs, which demonstrates that humans are more effective in trial-and-error than LLMs. We believe that the TEC platform and dataset provide a valuable foundation for understanding human trial-and-error behavior and for developing more capable AI systems. Platform and dataset are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Trial-and-Error Collection (TEC) dataset and platform for recording human problem-solving trajectories. 46 participants completed 58 tasks, yielding 5,370 trajectories and post-error reflections across 41,229 webpages. The authors report that humans achieve substantially higher accuracy than LLMs on these tasks and release the data publicly to support research on iterative problem solving.
Significance. The dataset provides a large-scale, publicly available record of detailed human trial-and-error processes with error feedback and reflections, which is a genuine contribution given the scarcity of such data. If the collection protocol is sound, the resource could support training or benchmarking of AI systems on realistic iterative strategies. The concrete collection statistics and public release strengthen the work.
major comments (1)
- [§4] §4 (LLM Evaluation): The claim that humans are substantially more effective at trial-and-error than LLMs rests on the reported accuracy gap, yet the manuscript does not specify whether LLMs were evaluated with an equivalent multi-turn interface, the same error signals, the same number of attempts, or reflection prompts matching the human platform. If LLMs received only single-pass or limited prompting, the gap is attributable to mismatched conditions rather than a difference in trial-and-error capability.
minor comments (2)
- [§3] The task domains and selection criteria for the 58 problems are described only at a high level; adding a table or appendix listing the tasks with brief descriptions would improve reproducibility.
- [§3.2] Participant instructions and the exact wording of the reflection prompts are not quoted verbatim; including them would clarify how reflections were elicited.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: [§4] §4 (LLM Evaluation): The claim that humans are substantially more effective at trial-and-error than LLMs rests on the reported accuracy gap, yet the manuscript does not specify whether LLMs were evaluated with an equivalent multi-turn interface, the same error signals, the same number of attempts, or reflection prompts matching the human platform. If LLMs received only single-pass or limited prompting, the gap is attributable to mismatched conditions rather than a difference in trial-and-error capability.
Authors: We thank the referee for highlighting this important aspect of our evaluation. The LLMs were evaluated using a multi-turn interface that provided the same error signals after each attempt, the same maximum number of attempts per task, and reflection prompts that encouraged analysis of prior errors before the next trial, closely matching the human collection protocol. We acknowledge that the original manuscript did not explicitly describe these matching conditions in sufficient detail. In the revised version, we will expand Section 4 with a precise description of the LLM evaluation setup, including the interface, feedback mechanism, attempt limits, and prompting strategy, to make the comparability transparent. revision: yes
Circularity Check
No circularity: empirical data collection with external LLM comparison
full rationale
The paper describes a platform for recording human trial-and-error trajectories on 58 tasks, yielding 5,370 trajectories and reflections. The claim that humans achieve higher accuracy than LLMs is presented as a direct observation from the collected dataset rather than any derivation, fitted parameter, or self-referential prediction. No equations, ansatzes, uniqueness theorems, or model-fitting steps exist in the manuscript. The work is self-contained as a data-release effort whose central empirical finding does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Web-based task interactions plus written reflections after errors can faithfully record human trial-and-error behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a data annotation platform and a corresponding dataset, termed Trial-and-Error Collection (TEC). The platform records users' complete trajectories across multiple trials and collects their reflections after receiving error feedback... 5,370 trial trajectories along with error reflections across 41,229 webpages.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Humans achieve substantially higher accuracy compared to LLMs, which demonstrates that humans are more effective in trial-and-error than LLMs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nilavra Bhattacharya and Jacek Gwizdka. 2021. YASBIL: Yet Another Search Behaviour (and) Interaction Logger. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 2585–2589. doi:10.1145/3404835.3462800
-
[2]
Ben Carterette, Paul Clough, Mark Hall, Evangelos Kanoulas, and Mark Sander- son. 2016. Evaluating Retrieval over Sessions: The TREC Session Track 2011-2014. InProceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval(Pisa, Italy)(SIGIR ’16). Association for Com- puting Machinery, New York, NY, USA, 68...
-
[3]
Hall, and Paul D
Ben Carterette, Evangelos Kanoulas, Mark M. Hall, and Paul D. Clough. 2014. Overview of the TREC 2014 Session Track. InProceedings of The Twenty-Third Text REtrieval Conference, TREC 2014, Gaithersburg, Maryland, USA, November 19-21, 2014 (NIST Special Publication, Vol. 500-308), Ellen M. Voorhees and Angela Ellis (Eds.). National Institute of Standards a...
2014
-
[4]
Jia Chen, Jiaxin Mao, Yiqun Liu, Fan Zhang, Min Zhang, and Shaoping Ma
-
[5]
Learning a product relevance model from click-through data in e-commerce,
Towards a Better Understanding of Query Reformulation Behavior in Web Search. InProceedings of the Web Conference 2021(Ljubljana, Slovenia) (WWW ’21). Association for Computing Machinery, New York, NY, USA, 743–755. doi:10.1145/3442381.3450127
-
[6]
Jia Chen, Jiaxin Mao, Yiqun Liu, Min Zhang, and Shaoping Ma. 2019. TianGong- ST: A New Dataset with Large-scale Refined Real-world Web Search Sessions. InProceedings of the 28th ACM International Conference on Information and Knowledge Management(Beijing, China)(CIKM ’19). Association for Computing Machinery, New York, NY, USA, 2485–2488. doi:10.1145/3357...
- [7]
-
[8]
C. Darwin. 1859.On the Origin of Species by Means of Natural Selection, Or, The Preservation of Favoured Races in the Struggle for Life. J. Murray. https: //books.google.co.jp/books?id=jTZbAAAAQAAJ
-
[9]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. MIND2WEB: towards a generalist agent for the web. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 1220, 24 pages
2023
-
[10]
Eugene, serdyukovpv, and Will Cukierski. 2013. Personalized Web Search Challenge. https://kaggle.com/competitions/yandex-personalized-web-search- challenge. Kaggle
2013
-
[11]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024. CRITIC: Large Language Models Can Self-Correct with Tool- Interactive Critiquing. arXiv:2305.11738 [cs.CL] https://arxiv.org/abs/2305.11738
work page internal anchor Pith review arXiv 2024
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[13]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Assoc...
- [14]
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv.org/abs/ 2005.11401
work page internal anchor Pith review arXiv 2021
-
[16]
Ruotian Ma, Peisong Wang, Cheng Liu, Xingyan Liu, Jiaqi Chen, Bang Zhang, Xin Zhou, Nan Du, and Jia Li. 2025. S 2R: Teaching LLMs to Self-verify and Self- correct via Reinforcement Learning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and...
2025
-
[17]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. SELF-REFINE: iterative refinement with self- feedback. InProceedings of the 37th International ...
2023
-
[18]
David Maxwell and Claudia Hauff. 2021. LogUI: Contemporary Logging In- frastructure for Web-Based Experiments. InAdvances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28 – April 1, 2021, Proceedings, Part II. Springer-Verlag, Berlin, Heidelberg, 525–530. doi:10.1007/978-3-030-72240-1_59
-
[19]
Yeray Mera, Gabriel Rodriguez, and Eugenia Marin-Garcia. 2021. Unraveling the benefits of experiencing errors during learning: Definition, modulating factors, and explanatory theories.Psychonomic Bulletin & Review29 (11 2021). doi:10. 3758/s13423-021-02022-8
2021
-
[20]
Janet Metcalfe. 2017. Learning from Errors.Annual Review of Psychology68, 1 (2017), 465–489. doi:10.1146/annurev-psych-010416-044022
-
[21]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA: a benchmark for General AI Assistants. arXiv:2311.12983 [cs.CL] https://arxiv.org/abs/2311.12983
work page internal anchor Pith review arXiv 2023
-
[22]
Matthew Mitsui and Chirag Shah. 2016. Coagmento 2.0: A System for Capturing Individual and Group Information Seeking Behavior. InProceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries(Newark, New Jersey, USA) (JCDL ’16). Association for Computing Machinery, New York, NY, USA, 233–234. doi:10.1145/2910896.2925447
-
[23]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2022. WebGPT: Browser-assisted question-answering with human feedback. arXiv:2112.09...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Newell and H.A
A. Newell and H.A. Simon. 2019.Human Problem Solving. Echo Point Books and Media. https://books.google.co.jp/books?id=Gf8EwgEACAAJ
2019
-
[25]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexan- der Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, An- dre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Ko...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
-
[27]
Srishti Palani, Zijian Ding, Austin Nguyen, Andrew Chuang, Stephen MacNeil, and Steven P. Dow. 2021. CoNotate: Suggesting Queries Based on Notes Promotes Knowledge Discovery. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Machinery, New York, NY, USA, Article 726, 14 page...
-
[28]
1999.All Life is Problem Solving
Karl Popper. 1999.All Life is Problem Solving. Routledge, London. Translated by Patrick Camiller
1999
-
[29]
Navid Rekabsaz, Oleg Lesota, Markus Schedl, Jon Brassey, and Carsten Eickhoff
-
[30]
TripClick: The Log Files of a Large Health Web Search Engine. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 2507–2513. doi:10.1145/3404835. 3463242
-
[31]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 377, 19 pages
2023
-
[32]
Herbert A. Simon. 1978. Information-Processing Theory of Human Problem Solving. https://api.semanticscholar.org/CorpusID:10344827
1978
-
[33]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Con- gcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Haotian Zhao, Haoyu Lu, Haoze Li, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese
-
[35]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents. arXiv:2504.12516 [cs.CL] https://arxiv.org/abs/2504.12516
work page internal anchor Pith review arXiv
-
[36]
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. 2025. Web- Walker: Benchmarking LLMs in Web Traversal. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, a...
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, and Jiecao Chen
-
[40]
Agent-R: Training Language Model Agents to Reflect via Iterative Self- Training. arXiv:2501.11425 [cs.AI] https://arxiv.org/abs/2501.11425
- [41]
-
[42]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[43]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv:2506.05176 [cs.CL] https://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854 [cs.AI] https://arxiv.org/abs/2307.13854
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.