Recognition: 2 theorem links
· Lean TheoremSelect-then-Solve: Paradigm Routing as Inference-Time Optimization for LLM Agents
Pith reviewed 2026-05-10 18:27 UTC · model grok-4.3
The pith
A per-task router for choosing reasoning paradigms raises average LLM accuracy by 2.8 percentage points over any fixed choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
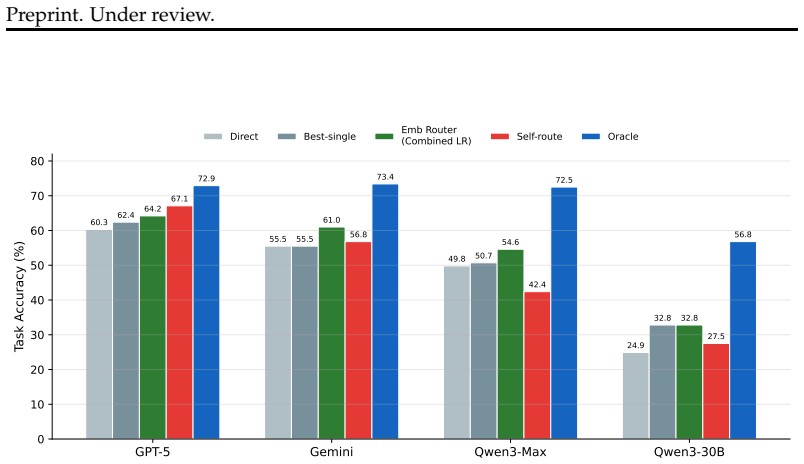
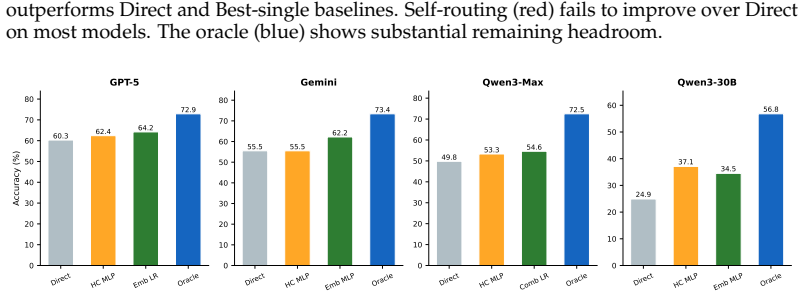
Across ten benchmarks and four models, no single reasoning paradigm is best for all tasks, but a lightweight embedding-based router that selects among Direct, Chain-of-Thought, ReAct, Plan-Execute, Reflection, and ReCode paradigms before answering each query lifts average accuracy from 47.6% to 53.1%, outperforming the best fixed paradigm by 2.8pp while recovering up to 37% of the oracle gap.
What carries the argument
Select-then-solve paradigm routing, in which a lightweight embedding-based classifier chooses the most suitable reasoning structure for each individual task before execution.
If this is right
- Reasoning structures such as ReAct and CoT show large but opposing effects depending on the task.
- Oracle selection of the best paradigm per task outperforms any fixed paradigm by 17.1pp on average.
- The learned router recovers a substantial fraction of that oracle advantage without requiring oracle knowledge.
- Zero-shot self-routing by the LLM itself succeeds only for the strongest model and underperforms the trained router for others.
Where Pith is reading between the lines
- Embedding-based routing may need periodic retraining or adaptation when new task types emerge in deployment.
- Extending the router to select combinations or sequences of paradigms could yield further gains.
- Integrating this selection with model choice or tool use might create more adaptive agent systems.
- Validating the router on tasks outside the original ten benchmarks would test its robustness to distribution shift.
Load-bearing premise
A router trained on the specific benchmarks used in the study will continue to select effective paradigms when faced with new and different tasks.
What would settle it
Running the router on a fresh set of tasks from a different domain where its selected paradigms perform worse on average than the best single fixed paradigm would falsify the claim of reliable improvement.
Figures






read the original abstract
When an LLM-based agent improves on a task, is the gain from the model itself or from the reasoning paradigm wrapped around it? We study this question by comparing six inference-time paradigms, namely Direct, CoT, ReAct, Plan-Execute, Reflection, and ReCode, across four frontier LLMs and ten benchmarks, yielding roughly 18,000 runs. We find that reasoning structure helps dramatically on some tasks but hurts on others: ReAct improves over Direct by 44pp on GAIA, while CoT degrades performance by 15pp on HumanEval. No single paradigm dominates, and oracle per-task selection beats the best fixed paradigm by 17.1pp on average. Motivated by this complementarity, we propose a select-then-solve approach: before answering each task, a lightweight embedding-based router selects the most suitable paradigm. Across four models, the router improves average accuracy from 47.6% to 53.1%, outperforming the best fixed paradigm at 50.3% by 2.8pp and recovering up to 37% of the oracle gap. In contrast, zero-shot self-routing only works for GPT-5 at 67.1% and fails for weaker models, all trailing the learned router. Our results argue that reasoning paradigm selection should be a per-task decision made by a learned router, not a fixed architectural choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts an extensive empirical study of six inference-time reasoning paradigms—Direct, CoT, ReAct, Plan-Execute, Reflection, and ReCode—across four frontier LLMs and ten benchmarks, involving approximately 18,000 runs. It shows that paradigms have complementary strengths, with no single one dominating, and oracle per-task selection improving over the best fixed paradigm by 17.1pp on average. The authors introduce a select-then-solve paradigm where a lightweight embedding-based router chooses the suitable paradigm for each task before solving, achieving an average accuracy of 53.1% compared to 47.6% without routing and 50.3% for the best fixed paradigm, thus recovering up to 37% of the oracle gap. Zero-shot self-routing is compared and found inferior except for the strongest model.
Significance. If the router generalizes, the work provides valuable evidence that reasoning paradigm selection is a per-task decision best handled by a learned component rather than a fixed choice or zero-shot self-routing. The scale of the experiments (4 models, 10 benchmarks, 18k runs) offers a solid foundation for the complementarity claim and could influence practical agent design by showing a lightweight router can recover a meaningful fraction of the oracle gap.
major comments (3)
- [Router evaluation] Router evaluation section: The router is trained on performance labels from the same 10 benchmarks used to report the 2.8pp gain (53.1% vs. 50.3%). No held-out task set, leave-one-benchmark-out, or cross-distribution validation is described, so the headline improvement may be in-sample rather than evidence of a generalizable inference-time optimizer.
- [Experimental details] Experimental details: The manuscript provides insufficient information on router training (embedding model, label collection from the 18k runs, hyperparameters, loss, and selection mechanism). This prevents assessment of confounds such as task-difficulty correlation and makes reproduction impossible.
- [Results analysis] Results analysis: No statistical tests, confidence intervals, or variance estimates are reported for the key deltas (2.8pp router gain, 17.1pp oracle gap). With 18k runs these should be straightforward to compute and are needed to support claims of reliable improvement.
minor comments (3)
- [Abstract] Clarify model names in the abstract (reference to 'GPT-5' is unclear; list the exact four frontier LLMs used).
- Add a per-benchmark breakdown table or figure to visually support the complementarity claim and show where each paradigm wins or loses.
- [Introduction] Define each paradigm (especially ReCode) with a brief citation to the original work for readers new to the area.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the manuscript. We address each major comment below and have made revisions to improve clarity, reproducibility, and statistical rigor.
read point-by-point responses
-
Referee: Router evaluation section: The router is trained on performance labels from the same 10 benchmarks used to report the 2.8pp gain (53.1% vs. 50.3%). No held-out task set, leave-one-benchmark-out, or cross-distribution validation is described, so the headline improvement may be in-sample rather than evidence of a generalizable inference-time optimizer.
Authors: We agree that the absence of explicit held-out validation limits strong claims of generalization beyond the evaluated benchmarks. The ten benchmarks are diverse (spanning coding, reasoning, agentic, and knowledge tasks), but this does not substitute for cross-benchmark validation. In the revised manuscript, we will add a leave-one-benchmark-out (LOBO) evaluation: the router is retrained on nine benchmarks and tested on the held-out benchmark, with results averaged across all ten folds. We will report the average LOBO accuracy and compare it to the in-sample result to quantify generalization. revision: yes
-
Referee: Experimental details: The manuscript provides insufficient information on router training (embedding model, label collection from the 18k runs, hyperparameters, loss, and selection mechanism). This prevents assessment of confounds such as task-difficulty correlation and makes reproduction impossible.
Authors: We acknowledge the need for greater detail to enable reproduction and confound analysis. The revised manuscript will expand the router section with: (1) the embedding model (all-MiniLM-L6-v2), (2) label construction (binary accuracy per task-paradigm pair from the 18k runs, with majority vote for ties), (3) hyperparameters (learning rate 1e-4, 20 epochs, batch size 32, AdamW optimizer), (4) loss (cross-entropy over six paradigms), and (5) inference (argmax over softmax probabilities). We will also add a short analysis correlating router choices with task difficulty proxies (e.g., average Direct accuracy) to address potential confounds. revision: yes
-
Referee: Results analysis: No statistical tests, confidence intervals, or variance estimates are reported for the key deltas (2.8pp router gain, 17.1pp oracle gap). With 18k runs these should be straightforward to compute and are needed to support claims of reliable improvement.
Authors: We agree that statistical support is required. In the revised results section, we will report 95% bootstrap confidence intervals for the 2.8pp router gain and 17.1pp oracle gap, computed by resampling tasks within each benchmark (10,000 iterations). We will also add paired statistical tests (McNemar's test per benchmark, aggregated via Fisher's method) to assess whether the router significantly outperforms the best fixed paradigm and whether the oracle gap is reliably large. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper conducts ~18,000 experimental runs comparing six paradigms on ten benchmarks, collects performance labels, trains a lightweight embedding router on that data, and reports the resulting accuracy (47.6% to 53.1%). No mathematical derivation, equation, or first-principles claim reduces the reported gain to its inputs by construction. The router's selection is an empirical outcome on the evaluated tasks rather than a fitted quantity renamed as an independent prediction. No self-citations, uniqueness theorems, or ansatzes are load-bearing. Generalization concerns to unseen tasks are external validity issues, not internal circularity in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- router training hyperparameters
axioms (1)
- domain assumption The six listed paradigms are representative of distinct and complementary reasoning strategies.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a lightweight embedding-based router selects the most suitable paradigm... improves average accuracy from 47.6% to 53.1%
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
oracle per-task selection beats the best fixed paradigm by 17.1pp
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023a. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large...
work page internal anchor Pith review arXiv
-
[2]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
URLhttps://arxiv.org/abs/2304.11477. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.Interna- tional Conference on Learning Representations,
work page internal anchor Pith review arXiv
-
[3]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data. arXiv preprint arXiv:2406.18665,
work page internal anchor Pith review arXiv
-
[4]
11 Preprint. Under review. Long Phan et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249,
work page internal anchor Pith review arXiv
-
[5]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Tal Shnitzer, Anthony Ou, M ´ırian Silva, Kate Soule, Yuekai Sun, Justin Solomon, Neil Thompson, and Mikhail Yurochkin. Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789,
-
[7]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models, 2023a. URLhttps://arxiv.org/abs/2305.04091. Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. Mint: Evaluating llms in multi-turn i...
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023b. URLhttps://arxiv.org/abs/2203.11171. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought p...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2601.14192 , year=
Xiaofang Yang*, Lijun Li*, Heng Zhou*, Tong Zhu*, Xiaoye Qu, Yuchen Fan, Qianshan Wei, Rui Ye, Li Kang, Yiran Qin, et al. Toward efficient agents: Memory, tool learning, and planning.arXiv preprint arXiv:2601.14192,
-
[11]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao et al. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review arXiv
-
[12]
SATISFACTORY
Once you have enough information, provide your final answer. Put your final answer inside\boxed{}. Plan-then-Execute.Uses two prompts: a planning prompt that produces a numbered step list, followed by an execution prompt: [Planning] First, create a step-by-step plan to solve the problem. Output ONLY the plan as a numbered list. Do not solve the problem ye...
2000
-
[13]
India” based on parametric knowledge. Most strikingly, Reflection made 10 tool calls andstillanswered “India
all converged on the correct answer. ReAct’s trace shows it progressively refining its web queries from English to Polish-language searches before finding the correct actor and role. 17 Preprint. Under review. GPT-5 Gemini Qwen3-Max Qwen3-30B 0 20 40 60 80 100Distribution (%) Learned Router GPT-5 Gemini Qwen3-Max Qwen3-30B 0 20 40 60 80 100Distribution (%...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.