Recognition: unknown
ARuleCon: Agentic Security Rule Conversion
Pith reviewed 2026-05-10 17:37 UTC · model grok-4.3
The pith
ARuleCon converts SIEM security rules between vendor formats using agents and runtime checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
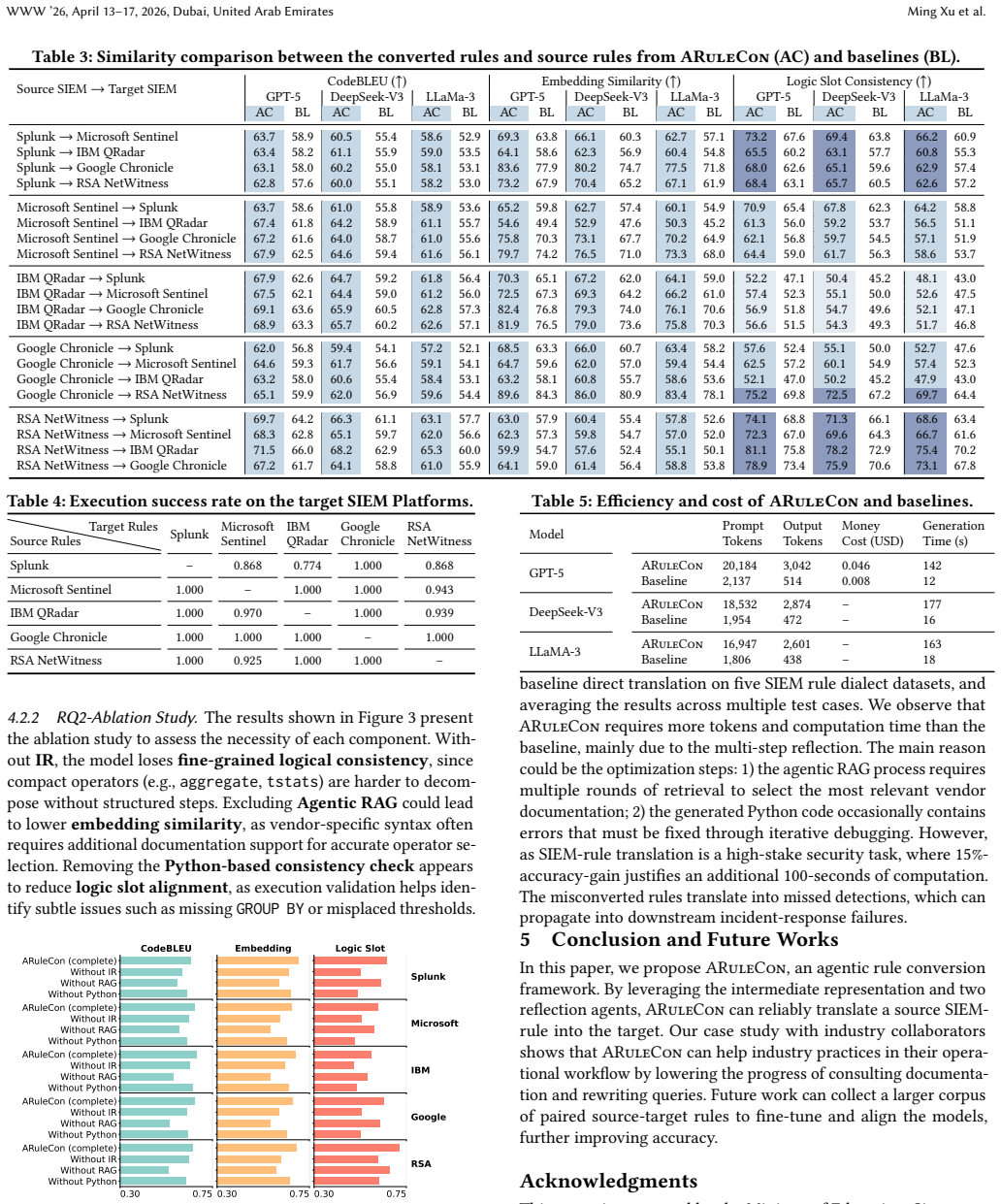
ARuleCon is an agentic framework that converts SIEM rules such as Splunk SPL into targets like Microsoft KQL by handling conversion and schema mismatches automatically, then applies a Python-based consistency check that runs both source and target rules against test data to catch semantic drifts, achieving 15 percent higher average fidelity than direct LLM prompting in textual alignment and execution success.
What carries the argument
Agentic pipeline that combines LLM-driven translation with mismatch resolution and parallel execution verification in sandboxed test environments.
If this is right
- Security teams can reuse existing detection rules when migrating between SIEM platforms.
- The time required to understand cross-vendor documentation and remap logic drops substantially.
- Rule conversion success rates rise compared with direct use of large language models.
- Proven detection logic retains its value across heterogeneous environments.
Where Pith is reading between the lines
- The same agent-plus-verification pattern could be tested on additional SIEM languages beyond the ones evaluated.
- Embedding the consistency checks into live data pipelines might allow continuous validation after deployment.
- Similar methods may help translate other security artifacts such as alert playbooks or compliance queries.
Load-bearing premise
That executing the source and converted rules against the same test data will reliably expose any important behavioral differences.
What would settle it
A set of real-world events where the converted rule produces a different set of alerts than the original rule despite both passing the consistency checks.
Figures





read the original abstract
Security Information and Event Management (SIEM) systems make it possible for detecting intrusion anomalies in real-time manner by their applied security rules. However, the heterogeneity of vendor-specific rules (e.g., Splunk SPL, Microsoft KQL, IBM AQL, Google YARA-L, and RSA ESA) makes cross-platform rule reuse extremely difficult, requiring deep domain knowledge for reliable conversion. As a result, an autonomous and accurate rule conversion framework can significantly lead to effort savings, preserving the value of existing rules. In this paper, we propose ARuleCon, an agentic SIEM-rule conversion approach. Using ARuleCon, the security professionals do not need to distill the source rules' logic, the documentation of the target rules and ARuleCon can purposely convert to the target vendors without more intervention. To achieve this, ARuleCon is equipped with conversion/schema mismatches, and Python-based consistency check that running both source and target rules in controlled test environments to mitigate subtle semantic drifts. We present a comprehensive evaluation of ARuleCon ranging from textual alignment and the execution success, showcasing ARuleCon can convert rules with high fidelity, outperforming the baseline LLM model by 15% averagely. Finally, we perform case studies and interview with our industry collaborators in Singtel Singapore, which showcases that ARuleCon can significantly save expert's time on understanding cross-SIEM's documentation and remapping logic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARuleCon, an agentic framework for converting SIEM security rules across heterogeneous vendors (Splunk SPL, Microsoft KQL, IBM AQL, Google YARA-L, RSA ESA). It uses LLM-based agents to handle conversion and schema mismatches without requiring users to distill source logic or target documentation, augmented by a Python-based consistency check that executes both source and target rules in controlled test environments. The central claims are high-fidelity conversion (textual alignment plus execution success) that outperforms a baseline LLM by 15% on average, plus time savings demonstrated via case studies and interviews with Singtel collaborators.
Significance. If the evaluation claims hold under rigorous testing, ARuleCon would offer a practical advance in automating cross-SIEM rule reuse, reducing expert effort in security operations centers where rule heterogeneity currently blocks reuse. The combination of agentic conversion with execution-based verification is a concrete step beyond pure prompting approaches; reproducible code or open test suites would further strengthen its impact.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim of a 15% average improvement in fidelity is presented without any reported test-set size, rule-selection criteria, number of conversion pairs, statistical tests, confidence intervals, or precise baseline prompting strategy (including temperature, few-shot examples, or model version). This prevents verification of the data-to-claim link and makes the performance delta impossible to reproduce or compare.
- [ARuleCon framework / Evaluation] Consistency-check description (Python-based execution in controlled environments): the method assumes that running source and target rules on the same test data will detect semantic drifts, yet the manuscript provides no evidence that the test scenarios cover edge cases such as null-value handling, time-window boundary conditions, aggregation over sparse logs, or vendor-specific schema quirks. Without such coverage metrics or failure-case analysis, the high-fidelity claim rests on an unverified assumption.
minor comments (2)
- [Introduction] Notation for rule languages (SPL, KQL, etc.) is introduced without a compact comparison table; adding one would improve readability for readers unfamiliar with all five dialects.
- [Case studies] The industry-interview protocol and participant count are mentioned only in passing; a brief description of interview questions or anonymized quotes would strengthen the qualitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each major comment below and revised the paper to improve the transparency and rigor of the evaluation.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim of a 15% average improvement in fidelity is presented without any reported test-set size, rule-selection criteria, number of conversion pairs, statistical tests, confidence intervals, or precise baseline prompting strategy (including temperature, few-shot examples, or model version). This prevents verification of the data-to-claim link and makes the performance delta impossible to reproduce or compare.
Authors: We agree that these experimental details were insufficiently reported in the original manuscript, which limits reproducibility. We have revised the Evaluation section to include the test-set size and rule-selection criteria, the number of conversion pairs evaluated, the statistical tests and confidence intervals used, and the precise baseline prompting strategy (model version, temperature, and few-shot examples). The test rules and prompts have also been added to the supplementary material to enable independent verification of the 15% average improvement. revision: yes
-
Referee: [ARuleCon framework / Evaluation] Consistency-check description (Python-based execution in controlled environments): the method assumes that running source and target rules on the same test data will detect semantic drifts, yet the manuscript provides no evidence that the test scenarios cover edge cases such as null-value handling, time-window boundary conditions, aggregation over sparse logs, or vendor-specific schema quirks. Without such coverage metrics or failure-case analysis, the high-fidelity claim rests on an unverified assumption.
Authors: We acknowledge that the original consistency-check description lacked explicit discussion of edge-case coverage and failure analysis. We have revised the manuscript to add a dedicated subsection describing the test scenarios, which now explicitly include null-value handling, time-window boundaries, sparse log aggregation, and vendor-specific schema differences. We also include a failure-case analysis with concrete examples of detected semantic drifts. While exhaustive coverage of all possible edge cases is not feasible, these additions provide evidence supporting the check's effectiveness. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external execution checks
full rationale
The paper's central claims of high-fidelity rule conversion (15% average improvement over baseline LLM) are supported by empirical evaluation metrics: textual alignment, execution success rates, and a Python-based consistency check that executes both source and target rules in controlled test environments. These steps constitute external validation against observable behavior rather than any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, ansatzes, or uniqueness theorems are invoked that reduce the result to the inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can accurately parse and rewrite security rule logic across heterogeneous vendor syntaxes without human intervention.
- domain assumption Execution of rules in controlled Python environments can detect and correct subtle semantic drifts introduced during conversion.
invented entities (1)
-
ARuleCon agentic conversion framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
meta-llama/Llama-3.1-405B·Hugging Face — huggingface.co
2022. meta-llama/Llama-3.1-405B·Hugging Face — huggingface.co. https: //huggingface.co/meta-llama/Llama-3.1-405B
2022
-
[2]
text-embedding-ada-002
2022. text-embedding-ada-002. https://platform.openai.com/docs/guides/ embeddings/what-are-embeddings
2022
-
[3]
deepseek-ai/DeepSeek-V3·Hugging Face — huggingface.co
2024. deepseek-ai/DeepSeek-V3·Hugging Face — huggingface.co. https:// huggingface.co/deepseek-ai/DeepSeek-V3
2024
-
[4]
Andi Albrecht and contributors. [n. d.]. sqlparse: non-validating SQL parser for Python. https://pypi.org/project/sqlparse/
-
[5]
Ariel Query Language Guide [n. d.]. https://www.ibm.com/docs/en/SS42VS_7.4/ pdf/b_qradar_aql.pdf. Ariel Query Language Guide
-
[6]
Sandeep N. Bhatt, Pratyusa K. Manadhata, and Loai Zomlot. 2014. The Operational Role of Security Information and Event Management Systems.IEEE Secur. Priv. 12, 5 (2014), 35–41. doi:10.1109/MSP.2014.103
-
[7]
Zijun Cheng, Qiujian Lv, Jinyuan Liang, Yan Wang, Degang Sun, Thomas Pasquier, and Xueyuan Han. 2023. Kairos: Practical Intrusion Detection and Investigation using Whole-system Provenance.CoRRabs/2308.05034 (2023). arXiv:2308.05034 doi:10.48550/ARXIV.2308.05034
-
[8]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trevo...
2020
-
[9]
Google Cloud [n. d.]. https://cloud.google.com/chronicle/docs/detection/yara-l- 2-0-syntax. YARA-L 2.0 language syntax
-
[10]
Google Security Operations (SecOps) [n. d.]. https://cloud.google.com/security/ products/security-operations?hl=en. Google SecOps’ cloud-native security operations platform empowers security teams to better detect, investigate, and respond to cybersecurity threats
-
[11]
Google YARA-L Rules [n. d.]. https://github.com/chronicle/detection-rules/tree/ main/rules/community. Google YARA-L Rule Dataset
-
[12]
Wajih Ul Hassan, Adam Bates, and Daniel Marino. 2020. Tactical Provenance Analysis for Endpoint Detection and Response Systems. In2020 IEEE Symposium on Security and Privacy, SP 2020, San Francisco, CA, USA, May 18-21, 2020. IEEE, 1172–1189. doi:10.1109/SP40000.2020.00096
-
[13]
IBM. 2024. SPL To KQL Application
2024
-
[14]
IBM AQL Rules [n. d.]. https://github.com/Xboarder56/QRCE-Rules. IBM QRadar AQL Rule Dataset
-
[15]
Cohen’s Kappa. [n. d.]. A measure of agreement between two dependent cate- gorical samples. https://datatab.net/tutorial/cohens-kappa
-
[16]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv:2412.05579 [cs.CL] https://arxiv.org/abs/2412.05579
work page internal anchor Pith review arXiv 2024
-
[17]
Ruishi Li, Bo Wang, Tianyu Li, Prateek Saxena, and Ashish Kundu. 2025. Trans- lating C To Rust: Lessons from a User Study. In32nd Annual Network and Dis- tributed System Security Symposium, NDSS 2025, San Diego, California, USA, Feb- ruary 24-28, 2025. The Internet Society. https://www.ndss-symposium.org/ndss- paper/translating-c-to-rust-lessons-from-a-us...
2025
-
[18]
Jiawei Liu, Nirav Diwan, Zhe Wang, Haoyu Zhai, Xiaona Zhou, Kiet A. Nguyen, Tianjiao Yu, Muntasir Wahed, Yinlin Deng, Hadjer Benkraouda, Yuxiang Wei, Lingming Zhang, Ismini Lourentzou, and Gang Wang. 2025. PurpCode: Reasoning for Safer Code Generation. arXiv:2507.19060 [cs.CR] https://arxiv.org/abs/2507. 19060
-
[19]
Zhengxiong Luo, Huan Zhao, Dylan Wolff, Cristian Cadar, and Abhik Roychoud- hury. 2026. Agentic Concolic Execution. In2026 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 1–19
2026
-
[20]
Microsoft. 2025. Microsoft Sentinel - Cloud-native SIEM Solution | Microsoft Azure — azure.microsoft.com. https://azure.microsoft.com/en-us/products/ microsoft-sentinel
2025
-
[21]
Microsoft Ignite [n. d.]. https://learn.microsoft.com/en-us/kusto/query/?view= microsoft-fabric. Kusto Query Language overview
-
[22]
Microsoft KQL Rules [n. d.]. https://github.com/Azure/Azure-Sentinel/tree/ master/Detections. Microsoft Sentinel KQL Rule Dataset
-
[23]
Amadou Latyr Ngom and Tim Kraska. 2024. Mallet: SQL Dialect Translation with LLM Rule Generation. InProceedings of the Seventh International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM 2024, Santiago, Chile, 14 June 2024. ACM, 3:1–3:5. doi:10.1145/3663742.3663973
-
[24]
Binhang Qi, Yun Lin, Xinyi Weng, Yuhuan Huang, Chenyan Liu, Hailong Sun, Zhi Jin, and Jin Song Dong. 2025. Intention-driven generation of project-specific test cases.arXiv preprint arXiv:2507.20619(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sun- daresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis.CoRRabs/2009.10297 (2020). arXiv:2009.10297 https://arxiv.org/abs/2009.10297
work page internal anchor Pith review arXiv 2020
-
[26]
RSA ESA Rules [n. d.]. https://github.com/netwitness/nw-esa. RSA NetWitness ESA Rule Dataset
-
[27]
Rule SyntaxRule Syntax [n. d.]. https://community.netwitness.com/s/article/ RuleSyntax. NetWitness Community
-
[28]
2016.Artificial intelligence: a modern approach
Stuart J Russell and Peter Norvig. 2016.Artificial intelligence: a modern approach. Pearson
2016
-
[29]
SIEM Migration [n. d.]. https://cardinalops.com/blog/siem-migration-challenges- strategies/. SIEM Migration: Challenges and Strategies
-
[30]
Kirill Simonov and contributors. [n. d.]. PyYAML: YAML parser and emitter for Python. https://pypi.org/project/PyYAML/
-
[31]
Splunk [n. d.]. https://help.splunk.com/en/splunk-enterprise/search/spl-search- reference/9.4/introduction/welcome-to-the-search-reference. Splunk Enterprise
-
[32]
Splunk cisco company [n. d.]. https://shorturl.at/dgTsP. State of Security 2024: The Race to Harness AI
2024
-
[33]
Splunk SPL Rules [n. d.]. https://github.com/splunk/security_content/tree/ develop/detections. Splunk SPL Rule Dataset
-
[34]
Threat Report [n. d.]. https://www.cloudwards.net/cyber-security-statistics/ ?utm_source=chatgpt.com. 67 Cyber Security Statistics, Facts and Trends: Data on Attacks, Breaches and Threats for 2025
2025
-
[35]
Rafael Uetz, Marco Herzog, Louis Hackländer, Simon Schwarz, and Martin Henze
-
[36]
You Cannot Escape Me: Detecting Evasions of SIEM Rules in Enterprise Networks.CoRRabs/2311.10197 (2023). arXiv:2311.10197 doi:10.48550/ARXIV. 2311.10197
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[37]
Mati Ur Rehman, Hadi Ahmadi, and Wajih Ul Hassan. 2024. Flash: A Compre- hensive Approach to Intrusion Detection via Provenance Graph Representa- tion Learning. In2024 IEEE Symposium on Security and Privacy (SP). 3552–3570. doi:10.1109/SP54263.2024.00139
-
[38]
VirusTotal. [n. d.]. yara-python: The Python interface for YARA. https://pypi. org/project/yara-python/
-
[39]
Hongtai Wang, Ming Xu, Yanpei Guo, Weili Han, Hoon Wei Lim, and Jin Song Dong. 2025. RulePilot: An LLM-Powered Agent for Security Rule Generation. CoRRabs/2511.12224 (2025). arXiv:2511.12224 doi:10.48550/ARXIV.2511.12224
-
[40]
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I. Wang. 2025. SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Soft- ware Evolution. arXiv:2502.18449 [cs.SE] https://arxiv.org/abs/2502.18449
-
[41]
Why SIEM Migration [n. d.]. DemystifyingSIEMmigration: Pitfallstoavoidandtipsforensuringsuccess. Demystifying SIEM migration: Pitfalls to avoid and tips for ensuring success
-
[42]
Pengfei Wu, Jianting Ning, Wu Luo, Xinyi Huang, and Debiao He. 2021. Exploring dynamic task loading in SGX-based distributed computing.IEEE Transactions on Services Computing16, 1 (2021), 288–301
2021
-
[43]
You are a security analyst specializing in Microsoft Sentinel KQL
Wei Zhou, Guoliang Li, Haoyu Wang, Yuxing Han, Xufei Wu, Fan Wu, and Xuanhe Zhou. 2025. PARROT: A Benchmark for Evaluating LLMs in Cross-System SQL Translation. arXiv:2509.23338 [cs.DB] https://arxiv.org/abs/2509.23338 A Discussion Constraint Translation.Agentic AI offers a promising paradigm for constraint translation (e.g., translating the C programming...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.