Recognition: no theorem link
Instance-Adaptive Parametrization for Amortized Variational Inference
Pith reviewed 2026-05-10 19:09 UTC · model grok-4.3
The pith
IA-VAE adds a hypernetwork that generates input-specific modulations to a shared encoder, expanding the variational family so that optimal ELBO is guaranteed to be at least as good as standard amortized inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
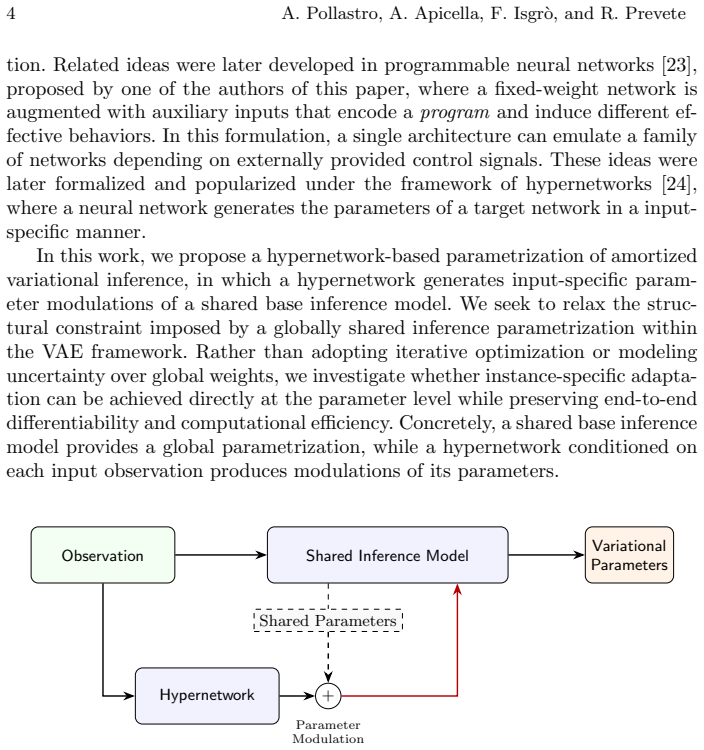
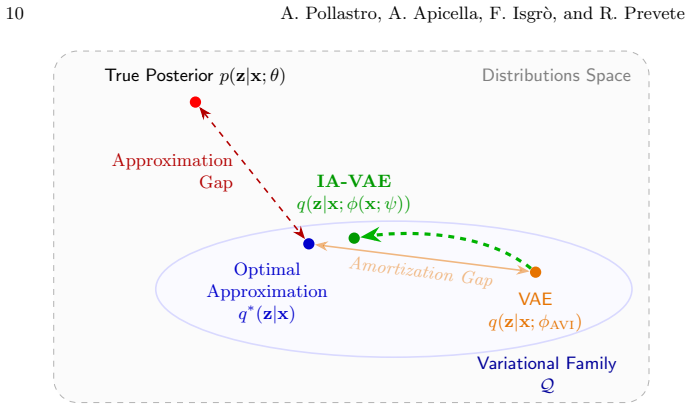
By letting a hypernetwork output instance-specific modulations that are applied to the weights of a shared encoder, IA-VAE induces a variational family that strictly contains the family of ordinary amortized inference. Consequently the optimal ELBO achieved by IA-VAE is at least as high as that of a standard VAE, and the approach yields more accurate posterior approximations on synthetic data and statistically significant ELBO gains on image data while using model capacity more efficiently.
What carries the argument
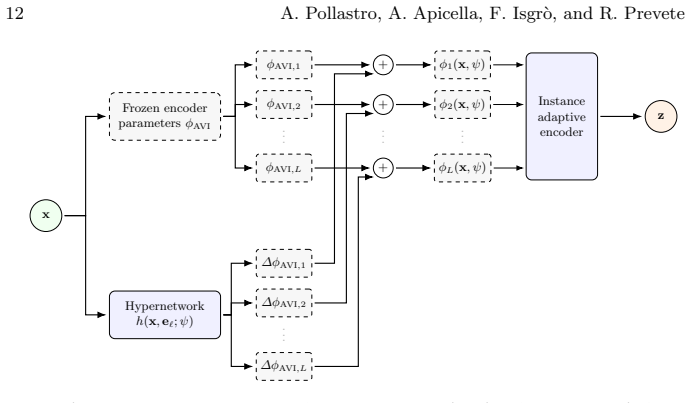
The hypernetwork that produces input-dependent modulations applied to the parameters of a shared encoder, thereby creating an instance-specific variational distribution in one forward pass.
If this is right
- The optimal ELBO of IA-VAE is guaranteed to be at least as high as that of standard amortized inference.
- Fewer total parameters can suffice for performance comparable to or better than a full conventional encoder.
- The amortization gap is reduced on data where the true posterior can be computed exactly.
- Held-out ELBO improves consistently across multiple runs on standard image benchmarks with statistical significance.
Where Pith is reading between the lines
- The same hypernetwork modulation idea could be applied to other amortized models such as normalizing flows or diffusion processes.
- Instance-specific adjustments might help capture multimodal or highly input-dependent posteriors that shared encoders struggle with.
- The added capacity of the hypernetwork trades off against the reduction in encoder size, suggesting an optimal balance point that may vary by dataset complexity.
Load-bearing premise
The hypernetwork must be able to learn input-dependent modulations that meaningfully enlarge the variational family in practice without introducing training instability or requiring substantially more data or compute.
What would settle it
On a synthetic dataset whose true posterior is analytically known, measure whether the ELBO or posterior KL divergence of IA-VAE is ever worse than that of an otherwise identical standard amortized VAE after comparable training.
Figures





read the original abstract
Variational autoencoders (VAEs) rely on amortized variational inference to enable efficient posterior approximation, but this efficiency comes at the cost of a shared parametrization, giving rise to the amortization gap. We propose the instance-adaptive variational autoencoder (IA-VAE), an amortized inference framework in which a hypernetwork generates input-dependent modulations of a shared encoder. This enables input-specific adaptation of the inference model while preserving the efficiency of a single forward pass. From a theoretical perspective, we show that the variational family induced by IA-VAE contains that of standard amortized inference, implying that IA-VAE cannot yield a worse optimal ELBO. By leveraging instance-specific parameter modulations, the proposed approach can achieve performance comparable to standard encoders with substantially fewer parameters, indicating a more efficient use of model capacity. Experiments on synthetic data, where the true posterior is known, show that IA-VAE yields more accurate posterior approximations and reduces the amortization gap. Similarly, on standard image benchmarks, IA-VAE consistently improves held-out ELBO over baseline VAEs, with statistically significant gains across multiple runs. These results suggest that increasing the flexibility of the inference parametrization through instance-adaptive modulation is an effective strategy for mitigating amortization-induced suboptimality in deep generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Instance-Adaptive Variational Autoencoder (IA-VAE), in which a hypernetwork generates input-dependent modulations of a shared encoder's parameters for amortized variational inference in VAEs. The central theoretical claim is a set-inclusion result showing that the variational family induced by IA-VAE contains the standard amortized family, implying that IA-VAE cannot achieve a worse optimal ELBO. Experiments on synthetic data (with known posteriors) and image benchmarks report improved ELBO values, reduced amortization gap, and comparable performance using substantially fewer parameters than baseline VAEs, with statistical significance across runs.
Significance. The set-inclusion proof is a clear strength, as it supplies a guarantee that the proposed method is at least as powerful as standard amortization at the level of optimal ELBO, independent of any fitted values. If the empirical gains hold, the approach offers a practical route to mitigating amortization suboptimality while preserving single-forward-pass efficiency and improving parameter utilization. The paper explicitly credits the containment argument and reports statistical testing on benchmarks, both of which aid assessment of the claims.
minor comments (3)
- [Abstract and §5] Abstract and experimental section: the statement that gains are 'statistically significant across multiple runs' should be accompanied by the exact number of independent runs performed and the specific test (e.g., paired t-test) used to establish significance.
- [Theoretical Analysis] Theoretical development: while the containment argument is stated clearly, the manuscript should explicitly note the architectural conditions (scale = 1, shift = 0) under which the hypernetwork realizes the constant function that recovers any fixed encoder parameters ϕ, and confirm this is preserved under the chosen modulation form.
- [Experiments] Experimental details: the relative size of the hypernetwork versus the base encoder, the modulation dimension, and the precise training protocol (including any additional regularization) should be reported to substantiate the 'substantially fewer parameters' claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. The review accurately highlights the value of the set-inclusion result as a guarantee that IA-VAE cannot underperform standard amortization at the level of optimal ELBO, as well as the empirical improvements in held-out ELBO, reduced amortization gap, and parameter efficiency on both synthetic and image data.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central theoretical claim is a set-inclusion proof showing that the IA-VAE variational family contains the standard amortized family (hence cannot have worse optimal ELBO). This holds by direct construction: the hypernetwork can output constant modulations (scale=1, shift=0) that recover any fixed encoder parameters ϕ for all inputs, which is a standard architectural property rather than a self-referential reduction or fitted input renamed as prediction. No equations reduce by definition to their own inputs, no load-bearing self-citations justify uniqueness, and experiments compare against external baselines on held-out ELBO rather than self-defined quantities. The derivation chain is therefore independent and self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- hypernetwork size and modulation dimension
axioms (1)
- domain assumption The variational family of IA-VAE contains the standard amortized inference family
invented entities (1)
-
instance-adaptive modulation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Practical variational inference for neural networks.Advances in neural information processing systems, 24, 2011
Alex Graves. Practical variational inference for neural networks.Advances in neural information processing systems, 24, 2011
2011
-
[2]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
2017
-
[4]
Stochastic back- propagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic back- propagation and approximate inference in deep generative models. InInternational conference on machine learning, pages 1278–1286. PMLR, 2014
2014
-
[5]
Andrea Pollastro, Francesco Isgr` o, and Roberto Prevete. Sincvae: A new semi- supervised approach to improve anomaly detection on eeg data using sincnet and variational autoencoder.Computer Methods and Programs in Biomedicine Update, page 100213, 2025
2025
-
[6]
Semi- supervised detection of structural damage using variational autoencoder and a one-class support vector machine.IEEE access, 11:67098–67112, 2023
Andrea Pollastro, Giusiana Testa, Antonio Bilotta, and Roberto Prevete. Semi- supervised detection of structural damage using variational autoencoder and a one-class support vector machine.IEEE access, 11:67098–67112, 2023. Instance-Adaptive Parametrization for Amortized Variational Inference 25
2023
-
[7]
Maximilian Kapsecker, Matthias C M¨ oller, and Stephan M Jonas. Disentan- gled representational learning for anomaly detection in single-lead electrocardio- gram signals using variational autoencoder.Computers in Biology and Medicine, 184:109422, 2025
2025
-
[8]
scvaeder: integrating deep diffusion mod- els and variational autoencoders for single-cell transcriptomics analysis.Genome Biology, 26(1):64, 2025
Mehrshad Sadria and Anita Layton. scvaeder: integrating deep diffusion mod- els and variational autoencoders for single-cell transcriptomics analysis.Genome Biology, 26(1):64, 2025
2025
-
[9]
Precision phenotyping of type 2 diabetes in chinese populations using a variational autoencoder-informed tree model.Nature Communications, 2026
Tong Yue, Wenhao Zhang, Yu Ding, Xueying Zheng, Yunjie Ma, Juliana CN Chan, Eric SH Lau, Juliana NM Lui, Guoxi Jin, Wen Xu, et al. Precision phenotyping of type 2 diabetes in chinese populations using a variational autoencoder-informed tree model.Nature Communications, 2026
2026
-
[10]
Reducing diverse sources of noise in ventricular electrical sig- nals using variational autoencoders.Expert Systems with Applications, 300:130185, 2026
Samuel Ruip´ erez-Campillo, Alain Ryser, Thomas M Sutter, Brototo Deb, Ruibin Feng, Prasanth Ganesan, Kelly A Brennan, Albert J Rogers, Maarten ZH Kolk, Fleur VY Tjong, et al. Reducing diverse sources of noise in ventricular electrical sig- nals using variational autoencoders.Expert Systems with Applications, 300:130185, 2026
2026
-
[11]
Multi-channel causal variational autoencoder for multimodal biomedical causal disentanglement.Journal of Biomedical Informatics, page 104995, 2026
Safaa Al-Ali, Irene Balelli, Alzheimer’s Disease Neuroimaging Initiative, et al. Multi-channel causal variational autoencoder for multimodal biomedical causal disentanglement.Journal of Biomedical Informatics, page 104995, 2026
2026
-
[12]
Ai-driven music composition: Melody generation using recurrent neural networks and variational autoencoders.Alexandria Engineering Journal, 120:258–270, 2025
Hanbing Zhao, Siran Min, Jianwei Fang, and Shanshan Bian. Ai-driven music composition: Melody generation using recurrent neural networks and variational autoencoders.Alexandria Engineering Journal, 120:258–270, 2025
2025
-
[13]
Xinyu Shang, Haobo Qiu, Pei Liang, Jie Shang, Chen Jiang, and Liang Gao. Data generation with meta fine-tuned degradation-informed variational autoencoder for remaining useful life prediction under data-scarce scenarios.Advanced Engineering Informatics, 70:104120, 2026
2026
-
[14]
Hamed Fathnejat and Vincenzo Nava. From augmentation to translation: Data generation by conditional hierarchical variational autoencoder, enhancing monitor- ing mooring systems in floating offshore wind turbines.Engineering Applications of Artificial Intelligence, 163:112951, 2026
2026
-
[15]
Parameter estimation of microlensed gravitational waves with conditional variational autoencoders.Physical Review D, 111(8):084067, 2025
Roberto Bada Nerin, Oleg Bulashenko, Osvaldo Gramaxo Freitas, and Jos´ e A Font. Parameter estimation of microlensed gravitational waves with conditional variational autoencoders.Physical Review D, 111(8):084067, 2025
2025
-
[16]
Expanding the chemical space of ionic liquids using conditional variational autoen- coders.Chemical Science, 2026
Gaopeng Ren, Austin M Mroz, Frederik Philippi, Tom Welton, and Kim E Jelfs. Expanding the chemical space of ionic liquids using conditional variational autoen- coders.Chemical Science, 2026
2026
-
[17]
Inference suboptimality in varia- tional autoencoders
Chris Cremer, Xuechen Li, and David Duvenaud. Inference suboptimality in varia- tional autoencoders. InInternational conference on machine learning, pages 1078–
-
[18]
Iterative amortized inference
Joe Marino, Yisong Yue, and Stephan Mandt. Iterative amortized inference. In International Conference on Machine Learning, pages 3403–3412. PMLR, 2018
2018
-
[19]
Amortized variational inference: A systematic review.Journal of Artificial Intelligence Research, 78:167– 215, 2023
Ankush Ganguly, Sanjana Jain, and Ukrit Watchareeruetai. Amortized variational inference: A systematic review.Journal of Artificial Intelligence Research, 78:167– 215, 2023
2023
-
[20]
Stochastic variational inference.Journal of machine learning research, 2013
Matthew D Hoffman, David M Blei, Chong Wang, and John Paisley. Stochastic variational inference.Journal of machine learning research, 2013
2013
-
[21]
Semi-amortized variational autoencoders
Yoon Kim, Sam Wiseman, Andrew Miller, David Sontag, and Alexander Rush. Semi-amortized variational autoencoders. InInternational Conference on Machine Learning, pages 2678–2687. PMLR, 2018
2018
-
[22]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
J¨ urgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992. 26 A. Pollastro, A. Apicella, F. Isgr` o, and R. Prevete
1992
-
[23]
Programming in the brain: a neural network theoretical framework.Connection Science, 24(2- 3):71–90, 2012
Francesco Donnarumma, Roberto Prevete, and Giuseppe Trautteur. Programming in the brain: a neural network theoretical framework.Connection Science, 24(2- 3):71–90, 2012
2012
-
[24]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks.arXiv preprint arXiv:1609.09106, 2016
work page internal anchor Pith review arXiv 2016
-
[25]
Iterative refinement of the approximate posterior for directed belief networks.Advances in neural information processing systems, 29, 2016
Devon Hjelm, Russ R Salakhutdinov, Kyunghyun Cho, Nebojsa Jojic, Vince Cal- houn, and Junyoung Chung. Iterative refinement of the approximate posterior for directed belief networks.Advances in neural information processing systems, 29, 2016
2016
-
[26]
Minyoung Kim and Vladimir Pavlovic. Reducing the amortization gap in vari- ational autoencoders: A bayesian random function approach.arXiv preprint arXiv:2102.03151, 2021
-
[27]
The elements of statistical learning: data mining, inference, and prediction, vol- ume 2
Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman. The elements of statistical learning: data mining, inference, and prediction, vol- ume 2. Springer, 2009
2009
-
[28]
Amortized inference regularization.Advances in Neural Information Processing Systems, 31, 2018
Rui Shu, Hung H Bui, Shengjia Zhao, Mykel J Kochenderfer, and Stefano Ermon. Amortized inference regularization.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[29]
Variational hyper-encoding networks
Phuoc Nguyen, Truyen Tran, Sunil Gupta, Santu Rana, Hieu-Chi Dam, and Svetha Venkatesh. Variational hyper-encoding networks. InJoint European Confer- ence on Machine Learning and Knowledge Discovery in Databases, pages 100–115. Springer, 2021
2021
-
[30]
Bayesian hypernetworks.arXiv preprint arXiv:1710.04759, 2017
David Krueger, Chin-Wei Huang, Riashat Islam, Ryan Turner, Alexandre Lacoste, and Aaron Courville. Bayesian hypernetworks.arXiv preprint arXiv:1710.04759, 2017
-
[31]
Don’t push the button! exploring data leakage risks in machine learning and transfer learning.Artificial Intelligence Review, 58(11):339, 2025
Andrea Apicella, Francesco Isgr` o, and Roberto Prevete. Don’t push the button! exploring data leakage risks in machine learning and transfer learning.Artificial Intelligence Review, 58(11):339, 2025
2025
-
[32]
Human- level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. Human- level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
2015
-
[33]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278– 2324, 2002
Yann LeCun, L´ eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278– 2324, 2002
2002
-
[34]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review arXiv 2017
-
[35]
A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
2024
-
[36]
Johannes Von Oswald, Christian Henning, Benjamin F Grewe, and Jo˜ ao Sacra- mento. Continual learning with hypernetworks.arXiv preprint arXiv:1906.00695, 2019
-
[37]
Weakly-supervised disentanglement without compromises
Francesco Locatello, Ben Poole, Gunnar R¨ atsch, Bernhard Sch¨ olkopf, Olivier Bachem, and Michael Tschannen. Weakly-supervised disentanglement without compromises. InInternational conference on machine learning, pages 6348–6359. PMLR, 2020
2020
-
[38]
Concvae: concep- tual representation learning.IEEE Transactions on Neural Networks and Learning Systems, 36(4):7529–7541, 2024
Ren Togo, Nao Nakagawa, Takahiro Ogawa, and Miki Haseyama. Concvae: concep- tual representation learning.IEEE Transactions on Neural Networks and Learning Systems, 36(4):7529–7541, 2024. Instance-Adaptive Parametrization for Amortized Variational Inference 27
2024
-
[39]
Toward the application of xai methods in eeg-based systems
Andrea Apicella, Francesco Isgr` o, Andrea Pollastro, and Roberto Prevete. Toward the application of xai methods in eeg-based systems. volume 3277, page 1 – 15, 2022
2022
-
[40]
Strategies to exploit xai to improve classification systems
Andrea Apicella, Luca Di Lorenzo, Francesco Isgr` o, Andrea Pollastro, and Roberto Prevete. Strategies to exploit xai to improve classification systems. InWorld Conference on Explainable Artificial Intelligence, pages 147–159. Springer, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.