Recognition: 2 theorem links
· Lean TheoremTo Adapt or not to Adapt, Rethinking the Value of Medical Knowledge-Aware Large Language Models
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
Domain-adapted clinical LLMs provide only marginal and unstable improvements over general-purpose models on English medical MCQA tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under current short-form MCQA benchmarks, clinical LLMs offer only marginal and unstable improvements over general-purpose models in English, suggesting that existing evaluation frameworks may be insufficient to capture genuine medical expertise. For Spanish, domain-adapted models like Marmoka show better performance compared to Llama.
What carries the argument
The perturbation-based evaluation benchmark, consisting of one-step and two-step question transformations, multi-prompt testing, and instruction-guided assessment, used to probe model performance beyond standard benchmarks.
If this is right
- Clinical adaptation provides value for low-resource languages such as Spanish.
- Both general and clinical models exhibit limitations in instruction following and strict output formatting.
- Robust medical LLMs can be successfully developed via continual domain-adaptive pretraining on medical corpora and instructions.
- Current short-form benchmarks may be insufficient to evaluate genuine medical expertise.
Where Pith is reading between the lines
- Future benchmarks could incorporate multi-turn clinical dialogues or real-world diagnostic scenarios to better distinguish model expertise.
- The success of Marmoka in Spanish suggests adaptation strategies are especially useful where general models have limited training data.
- Limitations in output formatting point to a need for fine-tuning methods focused on structured clinical responses.
Load-bearing premise
The selected MCQA tasks and introduced perturbation methods sufficiently measure clinical knowledge, robustness, and instruction following without introducing selection bias or overlooking key aspects of medical expertise.
What would settle it
Demonstrating consistent superiority of clinical LLMs over general models on an expanded set of clinical tasks that include open-ended reasoning, patient simulation, or long-context medical analysis would challenge the main findings.
Figures


read the original abstract
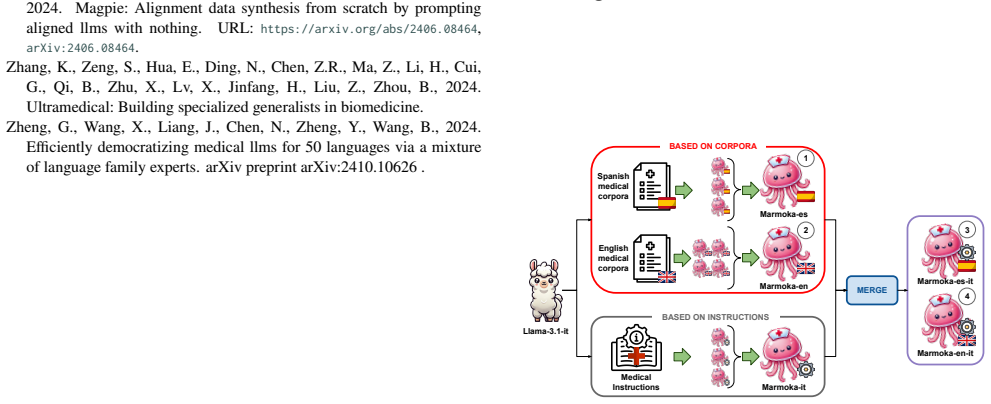
BACKGROUND: Recent studies have shown that domain-adapted large language models (LLMs) do not consistently outperform general-purpose counterparts on standard medical benchmarks, raising questions about the need for specialized clinical adaptation. METHODS: We systematically compare general and clinical LLMs on a diverse set of multiple choice clinical question answering tasks in English and Spanish. We introduce a perturbation based evaluation benchmark that probes model robustness, instruction following, and sensitivity to adversarial variations. Our evaluation includes, one-step and two-step question transformations, multi prompt testing and instruction guided assessment. We analyze a range of state-of-the-art clinical models and their general-purpose counterparts, focusing on Llama 3.1-based models. Additionally, we introduce Marmoka, a family of lightweight 8B-parameter clinical LLMs for English and Spanish, developed via continual domain-adaptive pretraining on medical corpora and instructions. RESULTS: The experiments show that clinical LLMs do not consistently outperform their general purpose counterparts on English clinical tasks, even under the proposed perturbation based benchmark. However, for the Spanish subsets the proposed Marmoka models obtain better results compared to Llama. CONCLUSIONS: Our results show that, under current short-form MCQA benchmarks, clinical LLMs offer only marginal and unstable improvements over general-purpose models in English, suggesting that existing evaluation frameworks may be insufficient to capture genuine medical expertise. We further find that both general and clinical models exhibit substantial limitations in instruction following and strict output formatting. Finally, we demonstrate that robust medical LLMs can be successfully developed for low-resource languages such as Spanish, as evidenced by the Marmoka models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that domain-adapted clinical LLMs do not consistently outperform general-purpose LLMs on English medical multiple-choice question answering (MCQA) tasks, even under a new perturbation-based evaluation that probes robustness, instruction following, and adversarial sensitivity via one-step/two-step transformations and multi-prompt testing. In contrast, the newly introduced Marmoka family of 8B-parameter models (developed via continual domain-adaptive pretraining on medical corpora) achieves better results than Llama on Spanish MCQA subsets. The authors conclude that current short-form MCQA benchmarks may be insufficient to capture genuine medical expertise, while both model classes exhibit substantial limitations in strict output formatting and instruction following.
Significance. If the empirical comparisons hold after addressing reporting gaps, the work would usefully challenge the default assumption that medical domain adaptation reliably improves LLM performance on clinical tasks in English. It provides a concrete counter-example in Spanish via Marmoka and flags the need for richer evaluation frameworks beyond standard MCQA. The systematic inclusion of perturbation methods and the successful low-resource adaptation example are practical strengths that could influence future model development and benchmarking practices in clinical NLP.
major comments (2)
- [Methods] Methods: The description of the experimental setup omits key reproducibility details required to support the central claim of inconsistent outperformance, including the specific English and Spanish MCQA datasets (names, sizes, sources), exact model variants and training procedures for the Llama 3.1-based clinical and general-purpose models, the statistical tests or variance measures used to establish 'marginal and unstable improvements', and any data exclusion or filtering rules. These elements are load-bearing for verifying whether the observed differences are robust or benchmark-specific.
- [Results] Results: No p-values, confidence intervals, or multi-run variance statistics are referenced for the performance deltas between clinical and general models on English tasks. This weakens the ability to distinguish genuine instability from noise, especially since the paper emphasizes 'unstable' gains as evidence that benchmarks may miss genuine expertise.
minor comments (1)
- [Abstract] Abstract: The terms 'one-step and two-step question transformations' and 'instruction guided assessment' are introduced without brief definitions or examples; adding one sentence of clarification would improve accessibility for readers unfamiliar with the perturbation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for improving reproducibility and statistical rigor, which we address below. We have revised the manuscript to incorporate the requested details where feasible while maintaining the integrity of our empirical findings on the limited benefits of domain adaptation for English clinical MCQA and the advantages of Marmoka for Spanish.
read point-by-point responses
-
Referee: [Methods] Methods: The description of the experimental setup omits key reproducibility details required to support the central claim of inconsistent outperformance, including the specific English and Spanish MCQA datasets (names, sizes, sources), exact model variants and training procedures for the Llama 3.1-based clinical and general-purpose models, the statistical tests or variance measures used to establish 'marginal and unstable improvements', and any data exclusion or filtering rules. These elements are load-bearing for verifying whether the observed differences are robust or benchmark-specific.
Authors: We agree that expanded methodological details are essential for full reproducibility. In the revised manuscript, we have updated Section 3 (Methods) and added a dedicated Appendix to specify: (1) all English datasets (MedQA with 12,723 questions, PubMedQA with 211,000, MMLU medical subsets, and others with exact sizes and sources); (2) Spanish MCQA subsets used for Marmoka evaluation; (3) precise model variants (Llama-3.1-8B-Instruct and Llama-3.1-70B-Instruct as general baselines, with our clinical adaptations via continual pretraining on medical corpora); (4) full training procedures, hyperparameters, and data filtering rules (e.g., deduplication, quality filtering on medical texts); and (5) a clarification that no formal statistical tests were applied, with 'unstable' referring to inconsistent patterns across benchmarks and perturbations rather than variance across runs. These additions directly support verification of our claims. revision: yes
-
Referee: [Results] Results: No p-values, confidence intervals, or multi-run variance statistics are referenced for the performance deltas between clinical and general models on English tasks. This weakens the ability to distinguish genuine instability from noise, especially since the paper emphasizes 'unstable' gains as evidence that benchmarks may miss genuine expertise.
Authors: We acknowledge that the original submission lacked formal statistical measures, which limits the strength of claims about instability. Our experiments relied on single-run evaluations, standard in large-scale LLM benchmarking due to computational demands. In revision, we have added: (1) a discussion in the Results section using the perturbation-based evaluations (one-step/two-step transformations and multi-prompt testing) to illustrate sensitivity and variability as evidence of instability; (2) confidence intervals derived from the multi-prompt results where applicable; and (3) an explicit statement on the limitations of single-run reporting. We maintain that the marginal and inconsistent outperformance holds across the diverse set of tasks and adversarial probes, reinforcing our broader point on benchmark sufficiency, though we note that multi-run statistics would require additional resources. revision: partial
Circularity Check
No significant circularity in empirical comparison
full rationale
This paper is a direct empirical evaluation study that compares general-purpose and clinical LLMs on MCQA benchmarks in English and Spanish, including perturbation-based tests for robustness and instruction following. It reports experimental results on existing tasks plus a new Marmoka model family trained via standard continual pretraining. No mathematical derivations, equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided abstract or framing. The central claims (marginal/unstable gains for clinical models on English tasks, better Spanish performance for Marmoka) are grounded in the reported benchmark outcomes rather than reducing to inputs by construction. The paper explicitly limits its scope to short-form MCQA and flags limitations in instruction following, making the findings self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Continual domain-adaptive pretraining on medical corpora and instructions produces usable clinical LLMs
invented entities (1)
-
Marmoka
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that, under current short-form MCQA benchmarks, clinical LLMs offer only marginal and unstable improvements over general-purpose models in English
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a perturbation based evaluation benchmark that probes model robustness, instruction following
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
18653/v1/2024.emnlp-industry.36
URL:https://aclanthology.org/2024.emnlp-industry.36, doi:10. 18653/v1/2024.emnlp-industry.36. Goenaga, I., Atutxa, A., Gojenola, K., Oronoz, M., Agerri, R., 2023. Explanatory argument extraction of correct answers in resident medical exams.arXiv:2312.00567. Gururajan, A.K., Lopez-Cuena, E., Bayarri-Planas, J., Tormos, A., Hinjos, D., Bernabeu-Perez, P., A...
-
[2]
arXiv preprint arXiv:2402.10373 (2024)
Biomistral:Acollectionofopen-sourcepretrainedlargelanguage models for medical domains. arXiv preprint arXiv:2402.10373 . Liu, F., Zhou, H., Gu, B., Zou, X., Huang, J., Wu, J., Li, Y., Chen, S.S., Hua, Y., Zhou, P., et al., 2025. Application of large language models in medicine. Nature Reviews Bioengineering , 1–20. Liu, Y., Li, D., Wang, K., Xiong, Z., Sh...
-
[3]
URL:https://arxiv.org/ abs/2305.12031,arXiv:2305.12031
Clinical camel: An open expert-level medical language model with dialogue-based knowledge encoding. URL:https://arxiv.org/ abs/2305.12031,arXiv:2305.12031. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov,N.,Batra,S.,Bhargava,P.,Bhosale,S.,Bikel,D.,Blecher,L., Ferrer,C.C.,Chen,M.,Cucurull,G.,Esiobu,D.,Fernandes,J.,Fu,J....
-
[4]
arXiv preprint arXiv:2407.15018
Answer, assemble, ace: Understanding how transformers answer multiple choice questions. arXiv preprint arXiv:2407.15018 . Xu, Z., Jiang, F., Niu, L., Deng, Y., Poovendran, R., Choi, Y., Lin, B.Y.,
-
[5]
Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing. URL:https://arxiv.org/abs/2406.08464, arXiv:2406.08464. Zhang, K., Zeng, S., Hua, E., Ding, N., Chen, Z.R., Ma, Z., Li, H., Cui, G., Qi, B., Zhu, X., Lv, X., Jinfang, H., Liu, Z., Zhou, B., 2024. Ultramedical: Building specialized generalists in biomedicine. Zheng, G., W...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.