Recognition: no theorem link
DTCRS: Dynamic Tree Construction for Recursive Summarization
Pith reviewed 2026-05-10 17:58 UTC · model grok-4.3
The pith
DTCRS dynamically decides when to build summary trees in RAG and seeds clusters with sub-question embeddings to cut redundancy and construction time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
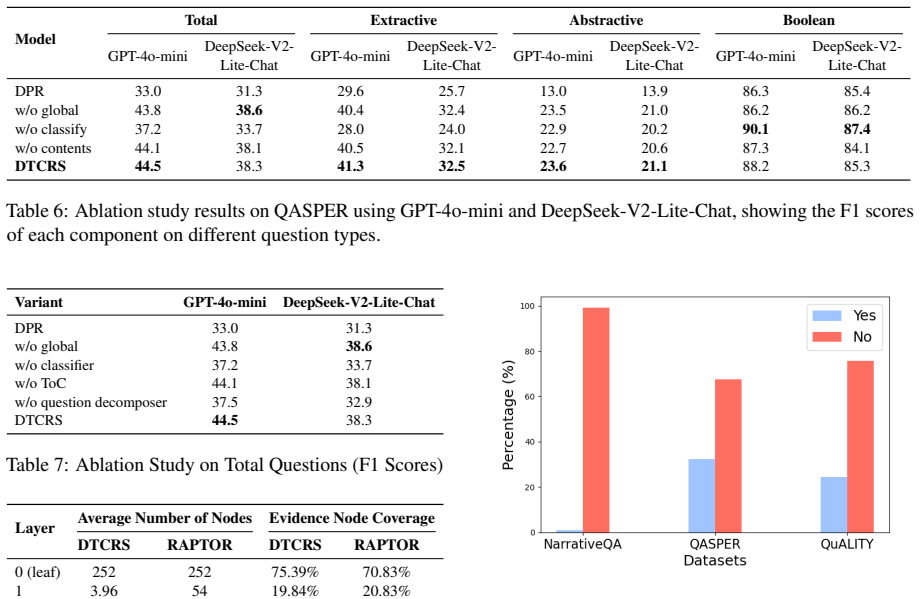
DTCRS determines whether a summary tree is necessary by analyzing the question type. It then decomposes the question and uses the embeddings of sub-questions as initial cluster centers, reducing redundant summaries while improving the relevance between summaries and the question. This approach significantly reduces summary tree construction time and achieves substantial improvements across three QA tasks, while also mapping which question types benefit from recursive summarization.
What carries the argument
Dynamic decision procedure that classifies question type to gate tree construction and seeds the clustering step with embeddings of decomposed sub-questions.
If this is right
- Summary tree construction time drops substantially compared with standard recursive summarization.
- Answer accuracy rises on three distinct question-answering tasks.
- The number of redundant summary nodes inside each tree decreases.
- Summaries become more directly relevant to the original question.
- Recursive summarization proves useful only for certain question types, giving a map for when to skip the tree step.
Where Pith is reading between the lines
- RAG pipelines could route simple factual questions to flat retrieval and reserve tree construction for multi-hop questions, saving compute at scale.
- The same question-decomposition and embedding-seeding idea might be applied to other hierarchical retrieval or planning methods that currently build fixed structures.
- Refining the question-type classifier on more varied domains could further reduce unnecessary tree builds without harming coverage.
Load-bearing premise
Question-type classification can accurately predict when a summary tree is useful and that seeding clusters with sub-question embeddings will remove redundancy without dropping key facts.
What would settle it
A controlled run on the same three QA benchmarks in which DTCRS produces no measurable drop in tree build time or no gain in answer quality, or in which the question-type classifier frequently chooses the wrong tree-or-no-tree decision.
Figures










read the original abstract
Retrieval-Augmented Generation (RAG) mitigates the hallucination problem of Large Language Models (LLMs) by incorporating external knowledge. Recursive summarization constructs a hierarchical summary tree by clustering text chunks, integrating information from multiple parts of a document to provide evidence for abstractive questions involving multi-step reasoning. However, summary trees often contain a large number of redundant summary nodes, which not only increase construction time but may also negatively impact question answering. Moreover, recursive summarization is not suitable for all types of questions. We introduce DTCRS, a method that dynamically generates summary trees based on document structure and query semantics. DTCRS determines whether a summary tree is necessary by analyzing the question type. It then decomposes the question and uses the embeddings of sub-questions as initial cluster centers, reducing redundant summaries while improving the relevance between summaries and the question. Our approach significantly reduces summary tree construction time and achieves substantial improvements across three QA tasks. Additionally, we investigate the applicability of recursive summarization to different question types, providing valuable insights for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DTCRS, a dynamic approach to recursive summarization in RAG systems. It analyzes question type to decide whether to build a hierarchical summary tree, decomposes the question into sub-questions, and seeds clustering with sub-question embeddings to reduce redundant nodes while improving relevance for multi-step reasoning. The method is claimed to cut construction time substantially and deliver improvements on three QA tasks, while also providing analysis of when recursive summarization applies to different question types.
Significance. If the empirical claims hold with proper validation, DTCRS could make hierarchical summarization more efficient and query-adaptive in RAG pipelines, addressing redundancy that inflates compute and potentially harms downstream multi-hop QA accuracy. The investigation into question-type applicability would add practical guidance for when such trees are worthwhile.
major comments (2)
- [Abstract] Abstract: The central claims of 'significantly reduces summary tree construction time' and 'substantial improvements across three QA tasks' are stated without any quantitative metrics, baselines, error bars, statistical tests, or implementation details. This absence makes it impossible to assess the magnitude or reliability of the reported gains.
- [Method] Method (dynamic tree construction): The approach rests on the assumptions that question-type classification reliably gates tree construction and that seeding clusters with sub-question embeddings reduces redundancy without dropping cross-chunk evidence needed for multi-hop reasoning. No ablation studies, error analysis on the classifier, or information-preservation checks are described to support these load-bearing mechanisms.
minor comments (2)
- [Abstract] The abstract would be clearer if it named the three QA tasks and datasets used for evaluation.
- Notation for embeddings and cluster initialization could be formalized with a short equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'significantly reduces summary tree construction time' and 'substantial improvements across three QA tasks' are stated without any quantitative metrics, baselines, error bars, statistical tests, or implementation details. This absence makes it impossible to assess the magnitude or reliability of the reported gains.
Authors: We agree that the abstract would be more informative with specific quantitative details. The experimental results in the paper include these metrics (e.g., time reductions and accuracy gains with baselines), but they are not summarized in the abstract. In the revised version, we will update the abstract to include key quantitative results, such as the percentage reduction in construction time, the specific improvements on the three QA tasks, and references to baselines, error bars, and statistical tests. revision: yes
-
Referee: [Method] Method (dynamic tree construction): The approach rests on the assumptions that question-type classification reliably gates tree construction and that seeding clusters with sub-question embeddings reduces redundancy without dropping cross-chunk evidence needed for multi-hop reasoning. No ablation studies, error analysis on the classifier, or information-preservation checks are described to support these load-bearing mechanisms.
Authors: We acknowledge that additional empirical support for these mechanisms would strengthen the claims. The manuscript already includes an analysis of question-type applicability, but we agree that dedicated ablations, classifier error analysis, and information-preservation checks are valuable. We will add these experiments in the revised manuscript to validate the gating decision and the seeding strategy's impact on redundancy and multi-hop evidence retention. revision: yes
Circularity Check
No circularity: empirical method with no self-referential derivations or fitted predictions
full rationale
The paper introduces DTCRS as an algorithmic procedure that analyzes question type to decide on tree construction and seeds clusters with sub-question embeddings. No equations, predictions, or first-principles results appear that reduce claimed time savings or QA gains to inputs by construction. The approach is presented as a design choice justified by empirical outcomes rather than tautological definitions or self-citation chains. Central claims rest on the method's mechanics and reported experiments, which remain independent of the inputs they process.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Question type can be analyzed automatically to decide whether recursive summarization is appropriate
- domain assumption Sub-question embeddings provide better initial cluster centers than random or document-only seeding
Reference graph
Works this paper leans on
-
[1]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Hybrid hierarchical retrieval for open-domain question answering. InFindings of the Association for Computational Linguistics: ACL 2023, pages 10680–10689. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511. Iz Beltag...
work page internal anchor Pith review arXiv 2023
-
[2]
InEu- ropean Conference on Information Retrieval, pages 264–278
Colisa: inner interaction via contrastive learn- ing for multi-choice reading comprehension. InEu- ropean Conference on Information Retrieval, pages 264–278. Springer. Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen
-
[3]
arXiv preprint arXiv:2305.14627 , year=
Enabling large language models to generate text with citations.arXiv preprint arXiv:2305.14627. Mandy Guo, Joshua Ainslie, David Uthus, Santiago On- tanon, Jianmo Ni, Yun-Hsuan Sung, and Yinfei Yang
-
[4]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasu- pat, and Mingwei Chang
Longt5: Efficient text-to-text transformer for long sequences.arXiv preprint arXiv:2112.07916. Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasu- pat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. InInternational confer- ence on machine learning, pages 3929–3938. PMLR. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2...
-
[5]
Recursively summarizing books with human feedback,
Recursively summarizing books with human feedback.arXiv preprint arXiv:2109.10862. Yumo Xu and Mirella Lapata. 2020. Coarse-to-fine query focused multi-document summarization. In Proceedings of the 2020 Conference on empirical methods in natural language processing (EMNLP), pages 3632–3645. Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.