Recognition: no theorem link
Gemma 4, Phi-4, and Qwen3: Accuracy-Efficiency Tradeoffs in Dense and MoE Reasoning Language Models
Pith reviewed 2026-05-10 17:44 UTC · model grok-4.3
The pith
Accuracy-efficiency tradeoffs in reasoning LLMs depend jointly on architecture, prompting protocol, and task rather than sparse activation alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
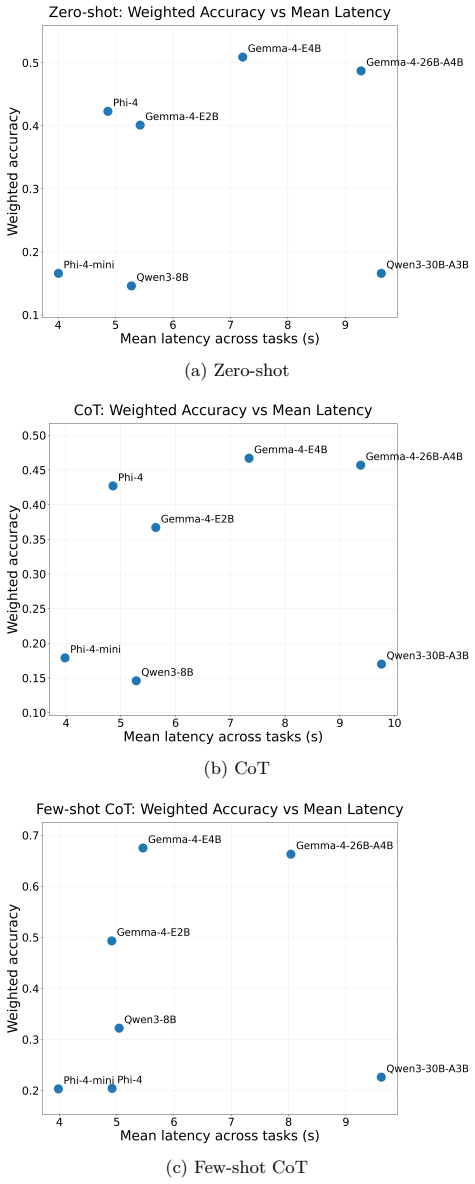
Across 8400 evaluations the paper establishes that sparse activation alone does not guarantee the best practical operating point; observed accuracy-efficiency tradeoffs depend jointly on architecture, prompting protocol, and task composition. Gemma-4-E4B reached weighted accuracy 0.675 at 14.9 GB VRAM, while the MoE Gemma-4-26B-A4B scored 0.663 at 48.1 GB VRAM. Task-level results showed Gemma models leading on ARC and Math, Phi models leading on TruthfulQA, and GSM8K exhibiting sharp prompt-dependent drops.
What carries the argument
Controlled multi-model, multi-benchmark, multi-prompt evaluation that records accuracy, peak VRAM, approximate FLOPs per token, and latency for dense versus MoE reasoning models.
If this is right
- Gemma-4-E4B with few-shot chain-of-thought delivers the strongest weighted accuracy at moderate memory cost.
- Larger MoE models can match or approach dense accuracy while consuming substantially more VRAM.
- Performance rankings shift by task, with Phi variants strongest on TruthfulQA and Gemma variants strongest on ARC and Math.
- GSM8K accuracy can drop sharply for some models when switching from chain-of-thought to few-shot chain-of-thought.
- End-to-end metrics under realistic constraints matter more than activation sparsity in isolation.
Where Pith is reading between the lines
- Deployment teams should benchmark prompting strategies alongside model selection rather than defaulting to MoE for efficiency gains.
- Extending the evaluation to include multi-turn conversations or domain-specific workloads could reveal additional operating-point differences.
- The observed prompt sensitivity suggests that prompt optimization remains a high-leverage lever even for instruction-tuned reasoning models.
- Hybrid dense-MoE routing policies might be tested to capture the accuracy of dense small models with the conditional compute of larger MoE variants.
Load-bearing premise
The four chosen benchmarks and three prompting strategies are representative enough of real-world reasoning workloads to support general claims about accuracy-efficiency tradeoffs.
What would settle it
A follow-up study on a broader set of reasoning tasks or under batch-inference hardware constraints that shows MoE models consistently achieving higher accuracy per unit memory or per unit latency than the dense winners here.
Figures



read the original abstract
Mixture-of-experts (MoE) language models are often expected to offer better quality-efficiency tradeoffs than dense models because only a subset of parameters is activated per token, but the practical value of that advantage depends on end-to-end behavior under realistic inference constraints. We present a controlled empirical benchmark of seven recent reasoning-oriented instruction-tuned models spanning dense and MoE designs, namely Gemma-4-E2B, Gemma-4-E4B, Gemma-4-26B-A4B, Phi-4-mini-reasoning, Phi-4-reasoning, Qwen3-8B, and Qwen3-30B-A3B, evaluated on four benchmarks -- ARC-Challenge, GSM8K, Math Level 1-3, and TruthfulQA MC1 -- under three prompting strategies: zero-shot, chain-of-thought, and few-shot chain-of-thought. The study covers 8,400 total model-dataset-prompt evaluations and records accuracy, latency, peak GPU memory usage (VRAM), and an approximate floating-point operations (FLOPs)-per-token proxy. Across the weighted multi-task summary, Gemma-4-E4B with few-shot chain-of-thought achieved the best overall result, reaching weighted accuracy 0.675 with mean VRAM 14.9 GB, while Gemma-4-26B-A4B was close in accuracy at 0.663 but substantially more memory intensive at 48.1 GB. At the task level, Gemma models dominated ARC and Math, Phi models were strongest on TruthfulQA, and GSM8K showed the largest prompt sensitivity, including a sharp drop for Phi-4-reasoning from 0.67 under chain-of-thought to 0.11 under few-shot chain-of-thought. These results show that sparse activation alone does not guarantee the best practical operating point: observed accuracy-efficiency tradeoffs depend jointly on architecture, prompting protocol, and task composition. We release a reproducible benchmark pipeline, aggregated results, and paired statistical analyses to support deployment-oriented evaluation of reasoning LLMs under real resource constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical benchmark of seven reasoning-oriented instruction-tuned LLMs spanning dense (Gemma-4-E2B, Gemma-4-E4B, Phi-4-mini-reasoning, Phi-4-reasoning, Qwen3-8B) and MoE (Gemma-4-26B-A4B, Qwen3-30B-A3B) designs. It evaluates them on ARC-Challenge, GSM8K, Math Level 1-3, and TruthfulQA MC1 under zero-shot, chain-of-thought, and few-shot chain-of-thought prompting, for a total of 8400 model-dataset-prompt runs. Metrics include accuracy, latency, peak VRAM, and an approximate FLOPs-per-token proxy. The central claim is that the dense Gemma-4-E4B with few-shot CoT attains the highest weighted multi-task accuracy-efficiency score (0.675 accuracy at 14.9 GB VRAM), outperforming the MoE Gemma-4-26B-A4B (0.663 accuracy at 48.1 GB VRAM), demonstrating that sparse activation alone does not guarantee the best practical operating point and that tradeoffs depend jointly on architecture, prompting protocol, and task composition. The authors release a reproducible benchmark pipeline, aggregated results, and paired statistical analyses.
Significance. If the empirical observations hold, the work supplies deployment-relevant evidence that MoE designs do not automatically deliver superior accuracy-efficiency tradeoffs under realistic inference constraints. The scale (8400 runs), inclusion of hardware metrics (VRAM and latency), and release of the full reproducible pipeline plus statistical analyses constitute clear strengths that enable verification and extension by practitioners and researchers.
major comments (2)
- [Abstract] Abstract and results summary: the weighted multi-task accuracy (0.675 for Gemma-4-E4B) is the load-bearing quantity for the claim that this model achieves the best overall operating point, yet the weighting scheme across the four benchmarks is not defined or justified; alternative weightings could alter the ranking relative to the MoE models.
- [Abstract] Abstract: the reported accuracy and VRAM figures are given without error bars, standard deviations, or any reference to statistical tests or run-to-run variability, which leaves open the possibility of selection effects in the 8400 evaluations and weakens the direct comparison between dense and MoE models.
minor comments (2)
- [Title] The model naming in the title ('Gemma 4') is inconsistent with the abstract ('Gemma-4-E2B', 'Gemma-4-E4B'); standardize nomenclature throughout.
- A compact summary table listing all seven models with their key metrics (weighted accuracy, VRAM, latency) under the best prompting strategy would improve readability of the cross-model comparison.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The two comments on the abstract concern clarity and statistical robustness; we address both directly below with targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results summary: the weighted multi-task accuracy (0.675 for Gemma-4-E4B) is the load-bearing quantity for the claim that this model achieves the best overall operating point, yet the weighting scheme across the four benchmarks is not defined or justified; alternative weightings could alter the ranking relative to the MoE models.
Authors: We agree that the abstract should explicitly define the weighting. Section 3.3 of the manuscript states that the weighted multi-task accuracy is the simple average of the four task accuracies (equal weight 0.25 each), chosen to treat the benchmarks as equally important for a balanced reasoning evaluation. We will insert a one-sentence definition into the abstract. To address sensitivity to alternative weightings, we will add a short appendix table showing that the ranking of Gemma-4-E4B over Gemma-4-26B-A4B is preserved under (i) weighting by dataset size and (ii) weighting by average task difficulty. All per-task accuracies remain fully reported in Tables 2–5, so readers can recompute any custom weighting. revision: yes
-
Referee: [Abstract] Abstract: the reported accuracy and VRAM figures are given without error bars, standard deviations, or any reference to statistical tests or run-to-run variability, which leaves open the possibility of selection effects in the 8400 evaluations and weakens the direct comparison between dense and MoE models.
Authors: We accept that the abstract’s point estimates would benefit from a variability reference. The main text (Section 4.2) and supplementary material already contain paired Wilcoxon signed-rank tests and standard deviations for the subset of evaluations run with multiple seeds. In the revision we will (a) add a sentence in the abstract directing readers to these analyses and (b) include error bars on the key summary plots and tables. Because of the scale of the 8400-run benchmark, not every configuration was re-run with additional seeds; the existing statistical tests nevertheless quantify variability across tasks and prompts. These changes will strengthen the dense-vs-MoE comparisons without changing the reported conclusions. revision: partial
Circularity Check
No significant circularity: purely empirical measurements
full rationale
The paper conducts a controlled empirical benchmark of seven LLMs across four tasks and three prompting protocols, recording direct observations of accuracy, latency, VRAM, and FLOPs. No derivations, equations, fitted parameters, or predictions are present; the central claim (dense model outperforming MoE on weighted accuracy-efficiency) follows immediately from the tabulated results without reduction to self-defined quantities or self-citation chains. All load-bearing steps are external data collection and aggregation, not internal redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected benchmarks (ARC-Challenge, GSM8K, Math Level 1-3, TruthfulQA) validly measure reasoning capability
Forward citations
Cited by 2 Pith papers
-
Simple Self-Conditioning Adaptation for Masked Diffusion Models
SCMDM adapts trained masked diffusion models to condition denoising steps on their own prior clean predictions, cutting generative perplexity nearly in half on open-web text while improving discretized image, molecule...
-
From Natural Language to Verified Code: Toward AI Assisted Problem-to-Code Generation with Dafny-Based Formal Verification
Open-weight LLMs reach 81-91% success generating formally verified Dafny code for complex algorithmic problems when given structural signatures and self-healing verifier feedback.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical 19 report.arXiv preprint arXiv:2412.08905, 2024. URLhttps://arxiv.org/abs/2412.08905
work page internal anchor Pith review arXiv 2024
-
[2]
Phi-4-reasoning technical report, 2025
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, et al. Phi-4-reasoning technical report.arXiv preprint arXiv:2504.21318, 2025. URLhttps://arxiv. org/abs/2504.21318
-
[3]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Ab- basi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. Lessons from the trenches on reproducible evaluation of language models.arXiv preprint arXiv:2405.14782, 2024. URLhttps://arxiv.org/abs/2405.14782
-
[4]
A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[5]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024. URLhttps: //jmlr.org/papers/v25/23-0870.html
2024
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. URLhttps://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. URLhttps://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022. URLhttps://jmlr.org/papers/v23/21-0998.html
2022
-
[9]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URLhttps://openreview.net/forum?id=7Bywt2mQsCe
2021
-
[10]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
2022
-
[11]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. URLhttps://arxiv.org/abs/2001.08361. 20
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D Manning, Christopher Re, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu ...
2023
-
[13]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022. URLhttps://aclanthology.org/ 2022.acl-long.229/
2022
-
[14]
Outrageously large neural networks: The sparsely-gated mixture-of- experts layer
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. InInternational Conference on Learning Representations, 2017. URLhttps: //openreview.net/forum?id=B1ckMDqlg
2017
-
[16]
URLhttps://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Efficient large language models: A survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, et al. Efficient large language models: A survey.arXiv preprint arXiv:2312.03863, 2023. URLhttps://arxiv.org/abs/2312.03863
-
[18]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[19]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, et al. A survey on efficient inference for large language models.arXiv preprint arXiv:2404.14294, 2024. URLhttps://arxiv.org/abs/2404.14294
work page internal anchor Pith review arXiv 2024
-
[21]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. ST-MoE: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906, 2022. URLhttps://arxiv.org/abs/2202.08906. 21 A Reproducibility Package To support reproducibility, we release the complete evaluation package at https://...
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.