Recognition: no theorem link
Towards foundation-style models for energy-frontier heterogeneous neutrino detectors via self-supervised pre-training
Pith reviewed 2026-05-10 17:33 UTC · model grok-4.3
The pith
Self-supervised pre-training on sparse vision transformers learns reusable representations from heterogeneous neutrino detector data that improve flavour identification, momentum regression, and vertex reconstruction while reducing labelled
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that self-supervised pre-training of a sparse ViT encoder on heterogeneous detector data, using masked reconstruction together with relational voxel objectives for hierarchy, ghost, and particle identification, produces representations that, after joint fine-tuning, consistently outperform randomly initialised models on neutrino flavour and charm identification, momentum regression, and vertex reconstruction; the same pre-trained encoder matches the flavour-classification performance of a scratch-trained model when given only about one-tenth the labelled events, and the learned features transfer effectively to benchmarks with different detector technologies.
What carries the argument
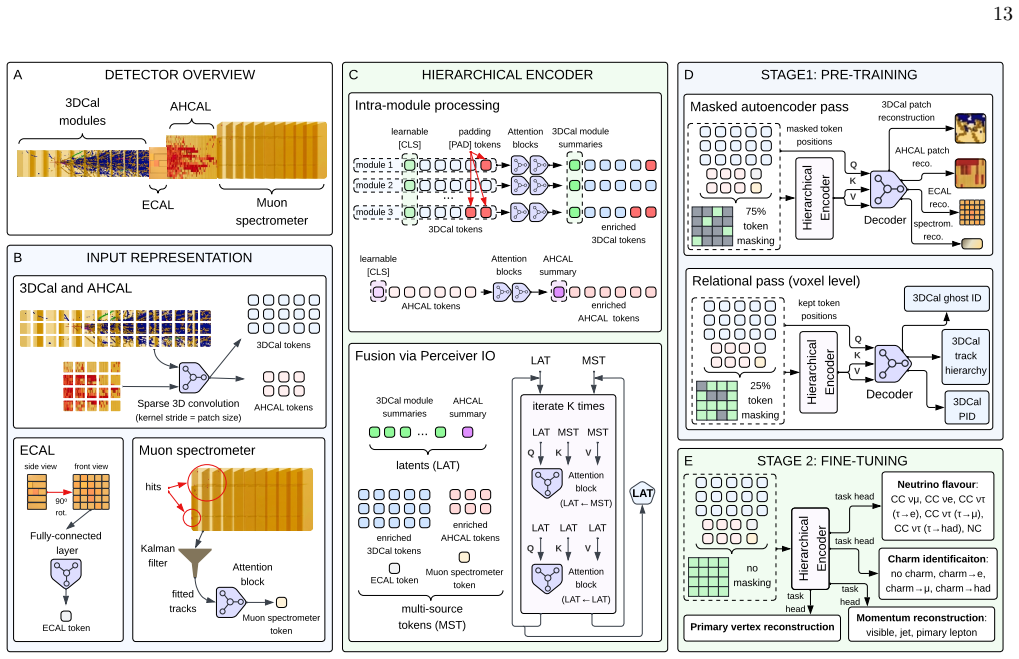
Sparse ViT encoder pre-trained with masked autoencoder reconstruction plus relational voxel-level objectives that encode hierarchy, ghost, and particle identification before joint fine-tuning across classification and regression heads.
If this is right
- Pre-training improves neutrino flavour and charm-quark identification, momentum regression, and vertex reconstruction over training from scratch.
- Relational voxel objectives produce additional gains precisely in the topologically most complex channels.
- Roughly one thousand labelled events allow the pre-trained encoder to reach the flavour-classification accuracy of a randomly initialised model trained on an order of magnitude more data.
- The learned representations transfer to publicly available benchmarks that use different detector technologies and energy scales.
- Detector-subsystem ablations recover channel-dependent roles for the heterogeneous inputs that align with physical expectations.
Where Pith is reading between the lines
- If the simulation-to-real gap proves small, the same pre-training recipe could be applied to other proposed energy-frontier neutrino detectors to reduce labelling costs.
- The more structured latent space observed after pre-training may allow physicists to inspect which detector subsystems drive each downstream decision.
- Success on multimodal sparse data suggests the approach could be tested on hybrid detectors that combine tracking, calorimetry, and timing in a single volume.
Load-bearing premise
Performance gains measured on simulated FASERCal events will generalise to real experimental data without large domain shift, and the relational objectives will reflect physically meaningful structure rather than simulation-specific patterns.
What would settle it
Train the same pre-trained encoder on real data collected from a heterogeneous neutrino detector such as FASERCal and measure whether its flavour-classification accuracy with one thousand labelled events still equals or exceeds a scratch-trained model that uses ten thousand labelled real events.
Figures






read the original abstract
Accelerator-based neutrino physics is entering an energy-frontier regime in which interactions reach the TeV scale and produce exceptionally dense, overlapping detector signatures. In this regime, event interpretation becomes impractical for conventional reconstruction approaches, particularly when labelled data are scarce and the analysis spans diverse downstream objectives. We present a sparse ViT framework for learning reusable representations from heterogeneous detector data. Self-supervised pre-training combines masked autoencoder reconstruction with relational voxel-level objectives for hierarchy, ghost and particle identification, and the resulting shared encoder is then jointly fine-tuned across classification and regression tasks. Evaluated on simulated events from the proposed FASERCal concept at the LHC, we find that pre-training consistently improves neutrino flavour and charm-quark identification, momentum regression, and vertex reconstruction over training from scratch, with the addition of relational objectives yielding further gains in the most topologically complex channels. Interpretability analyses further show that pre-training yields a more structured latent space, while detector-subsystem ablations recover physically plausible channel-dependent roles for the heterogeneous inputs. A data-efficiency study shows that, with roughly $10^3$ labelled events, the pre-trained encoder already matches the flavour-classification performance of a randomly initialised model trained on an order of magnitude more data. The learned representations also transfer effectively to publicly available benchmarks spanning different detector technologies and energy scales, matching or exceeding published baselines. These results support self-supervised pre-training on multimodal detector data as a scalable route towards reusable representations for neutrino and particle-detector analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a sparse Vision Transformer (ViT) architecture for self-supervised pre-training on heterogeneous neutrino detector data. Pre-training combines masked autoencoder reconstruction with relational voxel-level objectives (hierarchy, ghost/particle identification). The shared encoder is fine-tuned jointly on classification and regression tasks. On simulated FASERCal events at the LHC, pre-training yields consistent gains in neutrino flavour identification, charm-quark tagging, momentum regression, and vertex reconstruction relative to training from scratch; relational objectives add further benefit in topologically complex channels. A data-efficiency experiment shows that a pre-trained model reaches the flavour-classification performance of a randomly initialised model trained on an order of magnitude more labelled events (roughly 10^3 vs. 10^4 events). The representations also transfer to other public simulated benchmarks spanning different detector technologies and energy scales. Interpretability analyses and detector-subsystem ablations are presented to support the physical plausibility of the learned features.
Significance. If the empirical claims hold under more stringent controls, the work would be significant for energy-frontier neutrino experiments where labelled data are scarce and events are dense and overlapping. The demonstration of data-efficient transfer across tasks and detector technologies, together with the use of relational objectives that explicitly target topological structure, points toward reusable foundation-style encoders for multimodal particle-detector data. The interpretability and ablation results further strengthen the case that the learned representations capture detector-relevant hierarchies rather than simulation artifacts.
major comments (3)
- [data-efficiency study] Data-efficiency study (abstract and associated results section): the reported 10× reduction in labelled events required to match scratch-model flavour-classification performance is obtained entirely within the same FASERCal simulation sample. Because both pre-training and fine-tuning draw from identical event distributions, the scaling advantage could shrink or disappear under modest domain shifts (different neutrino energy spectrum, altered charm fragmentation, or added realistic noise). A concrete test—e.g., fine-tuning on events generated with varied beam energies or with an independent simulation package—would be required to substantiate the claim for real experimental data.
- [results on flavour identification, momentum regression, vertex reconstruction] Baseline and statistical reporting (results sections on flavour identification, momentum regression, and vertex reconstruction): the manuscript states consistent improvements but does not provide (i) the exact architecture and hyper-parameters of the “training from scratch” baselines, (ii) the number of independent training runs or statistical error bars on the reported metrics, or (iii) the precise train/validation/test splits used for the 10^3-event regime. These omissions make it impossible to judge whether the observed gains exceed run-to-run variance or arise from differences in optimisation schedule.
- [transfer experiments] Transfer experiments (final results paragraph): the claim that representations “transfer effectively to publicly available benchmarks spanning different detector technologies” is supported only by other simulated datasets. While this is a useful internal consistency check, it does not address the domain-shift concern raised above; the paper should clarify whether any of the transfer benchmarks incorporate independent modelling assumptions or real data.
minor comments (2)
- [methods] Notation: the precise definition of the relational loss weights and the masking ratio schedule should be stated explicitly in the methods section rather than left to supplementary material.
- [interpretability analyses] Figure clarity: several latent-space visualisation panels would benefit from explicit axis labels indicating the physical quantities being projected (e.g., energy, angle, or particle type).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript accordingly to improve clarity, reproducibility, and discussion of limitations.
read point-by-point responses
-
Referee: [data-efficiency study] Data-efficiency study (abstract and associated results section): the reported 10× reduction in labelled events required to match scratch-model flavour-classification performance is obtained entirely within the same FASERCal simulation sample. Because both pre-training and fine-tuning draw from identical event distributions, the scaling advantage could shrink or disappear under modest domain shifts (different neutrino energy spectrum, altered charm fragmentation, or added realistic noise). A concrete test—e.g., fine-tuning on events generated with varied beam energies or with an independent simulation package—would be required to substantiate the claim for real experimental data.
Authors: We agree that the data-efficiency results are obtained within a single simulated distribution. This is the standard controlled setting for such studies in particle physics, where the primary goal is to quantify sample-efficiency gains from pre-training before addressing real-data domain shifts. In the revised manuscript we will add an explicit limitations paragraph in the discussion section noting that the reported factor-of-10 improvement is specific to the FASERCal simulation and may be affected by changes in energy spectrum, fragmentation, or noise. While we cannot perform new cross-simulator experiments in the current revision cycle, the relational objectives are deliberately designed to capture topology rather than simulation-specific features, providing a plausible basis for broader applicability. revision: partial
-
Referee: [results on flavour identification, momentum regression, vertex reconstruction] Baseline and statistical reporting (results sections on flavour identification, momentum regression, and vertex reconstruction): the manuscript states consistent improvements but does not provide (i) the exact architecture and hyper-parameters of the “training from scratch” baselines, (ii) the number of independent training runs or statistical error bars on the reported metrics, or (iii) the precise train/validation/test splits used for the 10^3-event regime. These omissions make it impossible to judge whether the observed gains exceed run-to-run variance or arise from differences in optimisation schedule.
Authors: We acknowledge these omissions and will correct them in the revised manuscript. We will add: (i) the precise architecture and hyper-parameter settings (including optimizer, learning-rate schedule, and batch size) for all training-from-scratch baselines; (ii) results from five independent random seeds with mean and standard-error bars on every metric; and (iii) the exact train/validation/test splits, including the random-subsampling procedure used to create the 10^3-event fine-tuning sets. These additions will allow direct assessment of statistical significance and reproducibility. revision: yes
-
Referee: [transfer experiments] Transfer experiments (final results paragraph): the claim that representations “transfer effectively to publicly available benchmarks spanning different detector technologies” is supported only by other simulated datasets. While this is a useful internal consistency check, it does not address the domain-shift concern raised above; the paper should clarify whether any of the transfer benchmarks incorporate independent modelling assumptions or real data.
Authors: The transfer benchmarks are drawn from publicly released simulated datasets (MINERvA and NOvA-style geometries) that employ independent Monte Carlo generators, different detector response models, and distinct energy ranges. We will revise the text to state explicitly that all transfer results remain within simulation and that no real data are used. This clarifies the scope of the generalization claim while preserving the value of the cross-technology consistency test. revision: yes
Circularity Check
No circularity: purely empirical ML performance measurements on simulated data
full rationale
The paper presents results from self-supervised pre-training and fine-tuning of a sparse ViT on simulated FASERCal events, reporting measured improvements in classification, regression, and data-efficiency metrics against explicit scratch-training baselines. All load-bearing claims (e.g., pre-training matching 10x more data with ~10^3 labels, relational objectives adding gains in complex channels) are direct empirical observations on held-out simulation samples, with no derivations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled in. The work is self-contained against external benchmarks via reported transfer performance; no step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- masking ratio and relational objective weights
axioms (1)
- domain assumption Simulated events from the FASERCal concept accurately model real detector responses and physics processes at TeV scales
Reference graph
Works this paper leans on
-
[1]
We introduce a sparse encoder for heterogeneous 3 detector data that combines sparse convolutional patch embeddings, module-aware self-attention, and Perceiver-IO fusion across calorimetric and tracking streams
-
[2]
We formulate a multimodal pre-training strat- egy that augments masked reconstruction with relational voxel-level targets (ghost identifica- tion, interaction hierarchy and particle category), and show that this composite objective improves downstream performance beyond MAE-only pre- training, with the largest gains in the most chal- lenging channels
-
[3]
We demonstrate that the learned representation improves performance and data efficiency across a multi-task fine-tuning suite, and transfers beyond the source domain to publicly available benchmarks spanning different detector technologies and energy regimes. We evaluate this framework first on simulated events from theF ASERCalconcept as an energy-fronti...
-
[4]
FASER Collaboration, Detecting and studying high- energy collider neutrinos with FASER at the LHC, The European Physical Journal C80, 61 (2020)
2020
-
[5]
FASER Collaboration, First direct observation of collider neutrinos with FASER at the LHC, Physical Review Let- ters131, 031801 (2023)
2023
-
[6]
FASER Collaboration, First measurement of theν e and νµ interaction cross sections at the LHC with FASER’s emulsion detector, Physical Review Letters133, 021802 (2024)
2024
-
[7]
J. M. Cruz-Martinez, M. Fieg, T. Giani, P. Krack, T. M¨ akel¨ a, T. R. Rabemananjara, and J. Rojo, The LHC as a neutrino-ion collider, The European Physical Jour- nal C84, 369 (2024)
2024
-
[8]
R. Mammen Abrahamet al.(FASER), First Measure- ment of the Muon Neutrino Interaction Cross Section and Flux as a Function of Energy at the LHC with FASER, Phys. Rev. Lett.134, 211801 (2025), arXiv:2412.03186 [hep-ex]
- [9]
-
[10]
Radovic, M
A. Radovic, M. Williams, D. Rousseau, M. Kagan, D. Bonacorsi, A. Himmel, A. Aurisano, K. Terao, and T. Wongjirad, Machine learning at the energy and inten- sity frontiers of particle physics, Nature560, 41 (2018)
2018
-
[11]
C. N. Coelho, A. Kuusela, S. Li, H. Zhuang, J. Ngadi- uba, T. K. Aarrestad, V. Loncar, M. Pierini, A. A. Pol, and S. Summers, Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors, Nature Machine Intelligence 3, 675 (2021)
2021
-
[12]
Karagiorgi, G
G. Karagiorgi, G. Kasieczka, S. Kravitz, B. Nachman, and D. Shih, Machine learning in the search for new fun- damental physics, Nature Reviews Physics4, 399 (2022)
2022
-
[13]
Govorkova, E
E. Govorkova, E. Puljak, T. K. Aarrestad, T. James, V. Loncar, M. Pierini, A. A. Pol, S. Summers, J. Nga- diuba, T. Q. Nguyen, J. Duarte, Z. Wu,et al., Autoen- coders on field-programmable gate arrays for real-time, unsupervised new physics detection at 40 MHz at the Large Hadron Collider, Nature Machine Intelligence4, 154 (2022)
2022
-
[14]
Belis, K
V. Belis, K. A. Wo´ zniak, E. Puljak,et al., Quantum anomaly detection in the latent space of proton colli- sion events at the LHC, Communications Physics7, 334 (2024)
2024
-
[15]
J. Pata, E. Wulff, F. Mokhtar, D. Southwick, M. Zhang, M. Girone, and J. Duarte, Improved particle-flow event reconstruction with scalable neural networks for current and future particle detectors, Communications Physics 7, 107 (2024)
2024
-
[16]
A. Aurisano, A. Radovic, D. Rocco, A. Himmel, M. D. Messier, E. Niner, G. Pawloski, F. Psihas, A. Sousa, and P. Vahle, A convolutional neural network neutrino event classifier, JINST11(09), P09001, arXiv:1604.01444 [hep- ex]
- [17]
-
[18]
Psihas, M
F. Psihas, M. Groh, C. Tunnell, and K. Warburton, A review on machine learning for neutrino experiments, In- ternational Journal of Modern Physics A35, 2043005 (2020)
2020
-
[19]
B. Abiet al.(DUNE Collaboration), Neutrino interaction classification with a convolutional neural network in the DUNE far detector, Phys. Rev. D102, 092003 (2020), arXiv:2006.15052 [physics.ins-det]
-
[20]
L. Domin´ e and K. Terao, Scalable deep convolutional neural networks for sparse, locally dense liquid argon time projection chamber data, Phys. Rev. D102, 012005 (2020), arXiv:1903.05663 [hep-ex]
-
[21]
P. Abratenkoet al.(MicroBooNE Collaboration), Se- mantic segmentation with a sparse convolutional neural network for event reconstruction in MicroBooNE, Phys. Rev. D103, 052012 (2021), arXiv:2012.08513 [hep-ex]
-
[22]
Alonso-Monsalve, D
S. Alonso-Monsalve, D. Douqa, C. Jes´ us-Valls, T. Lux, S. Pina-Otey, F. S´ anchez, D. Sgalaberna, and L. H. Whitehead, Graph neural network for 3D classification of ambiguities and optical crosstalk in scintillator-based neutrino detectors, Phys. Rev. D103, 032005 (2021)
2021
-
[23]
F. m. c. Drielsma, Q. Lin, P. C. de Soux, L. Domin´ e, R. Itay, D. H. Koh, B. J. Nelson, K. Terao, K. V. Tsang, and T. L. Usher (DeepLearnPhysics Collabora- tion), Clustering of electromagnetic showers and parti- cle interactions with graph neural networks in liquid ar- gon time projection chambers, Phys. Rev. D104, 072004 (2021)
2021
-
[24]
Alonso-Monsalve, D
S. Alonso-Monsalve, D. Sgalaberna, X. Zhao, A. Molines, C. McGrew, and A. Rubbia, Deep-learning-based decom- position of overlapping-sparse images: application at the vertex of simulated neutrino interactions, Communica- tions Physics7, 173 (2024)
2024
-
[25]
Alonso-Monsalve, C
S. Alonso-Monsalve, C. Cavanagh, F. Cufino, U. Kose, A. Masciellani, A. Rubbia, D. Sgalaberna, E. Villa, X. Zhao, K. Axiotis,et al.,FASERCal Conceptual De- sign Report, Tech. Rep. CERN-FASER-NOTE-2026-004 (CERN, 2026)
2026
-
[26]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, inProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), edited by J. Burstein, C. Doran, and T. Sol...
2019
-
[27]
K. He, X. Chen, S. Xie, Y. Li, P. Doll´ ar, and R. Gir- shick, Masked autoencoders are scalable vision learners, inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)(2022) pp. 16 16000–16009
2022
-
[28]
Z. Xie, Z. Zhang, Y. Cao, Y. Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu, SimMIM: A simple framework for masked image modeling, inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)(2022) pp. 9653–9663
2022
-
[29]
Baevski, W.-N
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, data2vec: A general framework for self- supervised learning in speech, vision and language, in Proceedings of the 39th International Conference on Ma- chine Learning, Proceedings of Machine Learning Re- search, Vol. 162, edited by K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sa...
-
[30]
X. Yu, L. Tang, Y. Rao, T. Huang, J. Zhou, and J. Lu, Point-BERT: Pre-training 3d point cloud trans- formers with masked point modeling, inProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)(2022) pp. 19313–19322
2022
-
[31]
Z. Hou, X. Liu, Y. Cen, Y. Dong, H. Yang, C. Wang, and J. Tang, GraphMAE: Self-supervised masked graph autoencoders, arXiv preprint arXiv:2205.10803 10.48550/arXiv.2205.10803 (2022)
-
[32]
Chappell and L
A. Chappell and L. H. Whitehead, Application of transfer learning to neutrino interaction classification, The Euro- pean Physical Journal C82, 1099 (2022)
2022
-
[33]
Babicz, S
M. Babicz, S. Alonso-Monsalve, S. Dolan, and K. Terao, Adversarial methods to reduce simulation bias in neu- trino interaction event filtering at liquid argon time pro- jection chambers, Phys. Rev. D105, 112009 (2022)
2022
-
[34]
Adapting Vision-Language Models for Neutrino Event Classification in High-Energy Physics
D. Sagar, K. Yu, A. Yankelevich, J. Bian, and P. Baldi, Adapting vision-language models for neutrino event clas- sification in high-energy physics (2025), arXiv:2509.08461 [cs.LG]
work page internal anchor Pith review arXiv 2025
- [35]
-
[36]
Wilkinson, R
A. Wilkinson, R. Radev, and S. Alonso-Monsalve, Con- trastive learning for robust representations of neutrino data, Physical Review D111, 092011 (2025)
2025
-
[37]
F. Yu, N. Kamp, and C. Arg¨ uelles, Reducing simula- tion dependence in neutrino telescopes with masked point modeling, inProceedings of 39th International Cosmic Ray Conference — PoS(ICRC2025), Vol. 501 (2025) p. 1218
2025
-
[38]
Graph neural networks in particle physics
S. Young, Y. jae Jwa, and K. Terao, Particle trajectory representation learning with masked point modeling, Ma- chine Learning: Science and Technology 10.1088/2632- 2153/ae47b8 (2026)
-
[39]
J. L. Bonilla, K. M. Graczyk, A. M. Ankowski, R. D. Banerjee, B. E. Kowal, H. Prasad, and J. T. Sobczyk, Transfer learning for neutrino scattering: Domain adap- tation with generative adversarial networks, Physical Re- view D113, 053001 (2026)
2026
-
[40]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, An im- age is worth 16x16 words: Transformers for image recog- nition at scale, inInternational Conference on Learning Representations(2021)
2021
-
[41]
Alonso-Monsalve, D
S. Alonso-Monsalve, D. Sgalaberna, X. Zhao, C. Mc- Grew, and A. Rubbia, Artificial intelligence for improved fitting of trajectories of elementary particles in dense ma- terials immersed in a magnetic field, Communications Physics6, 119 (2023)
2023
- [42]
-
[43]
D. H. Koh, A. Mishra, and K. Terao, Deep neural net- work uncertainty quantification for LArTPC reconstruc- tion, Journal of Instrumentation18(12), P12013
-
[44]
Harris, J
P. Harris, J. Krupa, M. Kagan, B. Maier, and N. Wood- ward, Resimulation-based self-supervised learning for pretraining physics foundation models, Phys. Rev. D 111, 032010 (2025)
2025
-
[45]
Heinrich, T
L. Heinrich, T. Golling, M. Kagan, S. Klein, M. Leigh, M. Osadchy, and J. A. Raine, Masked particle model- ing on sets: towards self-supervised high energy physics foundation models, Machine Learning: Science and Tech- nology5, 035074 (2024)
2024
-
[46]
J. Birk, A. Hallin, and G. Kasieczka, Omnijet- alpha: the first cross-task foundation model for particle physics, Machine Learning: Science and Technology5, 035031 (2024)
2024
-
[47]
M. Vigl, N. Hartman, and L. Heinrich, Finetuning foun- dation models for joint analysis optimization, Machine Learning: Science and Technology5, 025075 (2024)
2024
- [48]
-
[49]
Andreopoulos, A
C. Andreopoulos, A. Bell, D. Bhattacharya, F. Cavanna, S. Dytman, H. Gallagher, P. Guzowski, R. Hatcher, P. Kehayias, A. Meregaglia, D. Naples, G. Pearce, A. Poskanzer, R. Raboanary, A. Technical, M. Wilking, et al., The GENIE neutrino Monte Carlo generator, Nu- clear Instruments and Methods in Physics Research Sec- tion A614, 87 (2010)
2010
-
[50]
Bierlich, S
C. Bierlich, S. Chakraborty, N. Desai, L. Gellersen, I. He- lenius, P. Ilten, L. L¨ onnblad, S. Mrenna, S. Prestel, C. T. Preuss, T. Sj¨ ostrand, P. Skands, M. Utheim, and R. Ver- ber´ ek, A comprehensive guide to the physics and usage of PYTHIA 8.3, SciPost Physics Codebases8, r8.3 (2022)
2022
-
[51]
Agostinelli, J
S. Agostinelli, J. Allison, K. Amako, J. Apostolakis, H. Araujo, P. Arce, M. Asai, D. Axen, S. Banerjee, G. Barrand,et al., Geant4: a simulation toolkit, Nuclear Instruments and Methods in Physics Research Section A 506, 250 (2003)
2003
-
[52]
Yan, Spconv: Spatially sparse convolution library, https://github.com/traveller59/spconv(2020)
Y. Yan, Spconv: Spatially sparse convolution library, https://github.com/traveller59/spconv(2020)
2020
-
[53]
Graham, M
B. Graham, M. Engelcke, and L. van der Maaten, 3D semantic segmentation with submanifold sparse convolu- tional networks, inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (2018) pp. 9224–9232
2018
-
[54]
Bowen Jing, Bonnie Berger, and Tommi Jaakkola
A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhamer, O. H´ enaff, M. M. Botvinick, A. Zisser- man, O. Vinyals, and J. Carreira, Perceiver IO: A gen- eral architecture for structured inputs & outputs (2022) arXiv:2107.14795 [cs.LG]
-
[55]
Cipolla, Y
R. Cipolla, Y. Gal, and A. Kendall, Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(2018) pp. 7482–7491. 17
2018
-
[56]
H. Fan, H. Su, and L. J. Guibas, A point set generation network for 3d object reconstruction from a single image, inProceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition(2017) pp. 605–613
2017
-
[57]
Loshchilov and F
I. Loshchilov and F. Hutter, Decoupled weight decay regularization, inInternational Conference on Learning Representations(2019)
2019
-
[58]
H. Bao, L. Dong, S. Piao, and F. Wei, BEit: BERT pre- training of image transformers, inInternational Confer- ence on Learning Representations(2022)
2022
-
[59]
B. T. Polyak and A. B. Juditsky, Acceleration of stochastic approximation by averaging, SIAM Jour- nal on Control and Optimization30, 838 (1992), https://doi.org/10.1137/0330046. Appendix A: Supplementary architectural details
-
[60]
The detector is organised into ten modules, so each module spans two patch planes in depth
Tokenisation and latent structure In the configuration used for the main experiments, the3DCalis tokenised into 12×12×10 voxel patches, yielding a 4×4×20 patch grid. The detector is organised into ten modules, so each module spans two patch planes in depth. TheAHCALis tokenised into 6×6×5 voxel patches, yielding a 3×3×8 patch grid. Only occupied patches a...
-
[61]
The base learning rate is linearly scaled by the effective batch size divided by 256 inside the training framework; the values listed are the unscaled base rates
Hyperparameters Table III summarises the key training hyperparame- ters for all model variants. The base learning rate is linearly scaled by the effective batch size divided by 256 inside the training framework; the values listed are the unscaled base rates. Per-step warm-up and cosine- annealing schedules are computed from the trainer state (number of de...
-
[62]
Fine-tuning further uses layer-wise learning-rate decay [55], exponential moving averages of the model parameters [56] and uncertainty- based multi-task weighting [52]
Optimisation All stages use the AdamW optimiser [54] with the pa- rameters listed in Table III. Fine-tuning further uses layer-wise learning-rate decay [55], exponential moving averages of the model parameters [56] and uncertainty- based multi-task weighting [52]. Checkpoint selection, early-stopping criteria and any differences between the headline exper...
-
[63]
Data splits and data-efficiency protocol The mainF ASERCalexperiments use one canonical 85/5/10 train/validation/test split. The data-efficiency study reuses the same validation and test partitions and subsamples only the training partition at budgets of 100, 300, 1,000, 3,000, 10,000, 30,000 and 100,000 events, with three seeds per budget. Because the po...
-
[64]
Pre-training targets Masked reconstruction predicts voxel occupancy and charge for masked3DCalandAHCALpatches, to- gether with maskedECALand muon-spectrometer sum- maries when those inputs are dropped. The rela- tional pass predicts ghost labels (binary), hierarchy la- bels (three classes: background, primary, secondary) and particle-category labels (thre...
-
[65]
Fine-tuning targets Fine-tuning jointly predicts a six-way flavour label, a four-way charm label, visible momentum, jet momen- tum, and the primary vertex. Theν τ classes are defined from the primary tau-decay products:ν τ CC→eandν τ CC→µrequire an electron or muon, respectively, while all remainingν τ CC events are assigned toν τ CC→had. Charm labels are...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.