Recognition: unknown
SemEval-2026 Task 3: Dimensional Aspect-Based Sentiment Analysis (DimABSA)
Pith reviewed 2026-05-10 17:18 UTC · model grok-4.3
The pith
The SemEval-2026 shared task models aspect-based sentiment and stance using continuous valence-arousal dimensions instead of categorical labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The SemEval-2026 shared task on Dimensional Aspect-Based Sentiment Analysis improves traditional ABSA by modeling sentiment along valence-arousal dimensions rather than categorical polarity labels. Track A covers dimensional aspect sentiment regression, triplet extraction, and quadruplet extraction; Track B reformulates stance detection as valence-arousal regression over stance targets. A continuous F1 metric jointly evaluates structured output and dimensional accuracy. The organizers report baselines, top system performance, and design insights from 112 submissions.
What carries the argument
Valence-arousal (VA) dimensional regression applied to aspects and stance targets, evaluated with a continuous F1 metric that combines extraction structure and numeric VA accuracy.
If this is right
- Aspect sentiment can be expressed as numeric coordinates rather than positive/negative/neutral classes.
- Stance detection on political or climate topics becomes a regression problem in the same VA space.
- A single continuous F1 score can rank systems on both extraction structure and dimensional precision.
- Public-issue discourse gains a uniform dimensional treatment alongside consumer-review ABSA.
Where Pith is reading between the lines
- Dimensional outputs may integrate more naturally with psychological or physiological models of emotion.
- Regression-based training could reduce label noise that arises when annotators force borderline cases into discrete categories.
- The same VA framework might later support cross-lingual or multimodal extensions where categorical labels are harder to align.
Load-bearing premise
That representing sentiment and stance in continuous valence-arousal space will yield more useful models than traditional categorical labels for both consumer reviews and public-issue discourse.
What would settle it
An experiment on an existing downstream task such as review summarization or stance-based prediction that shows equivalent or worse performance when systems are trained on the new VA-annotated data versus standard categorical ABSA annotations.
Figures


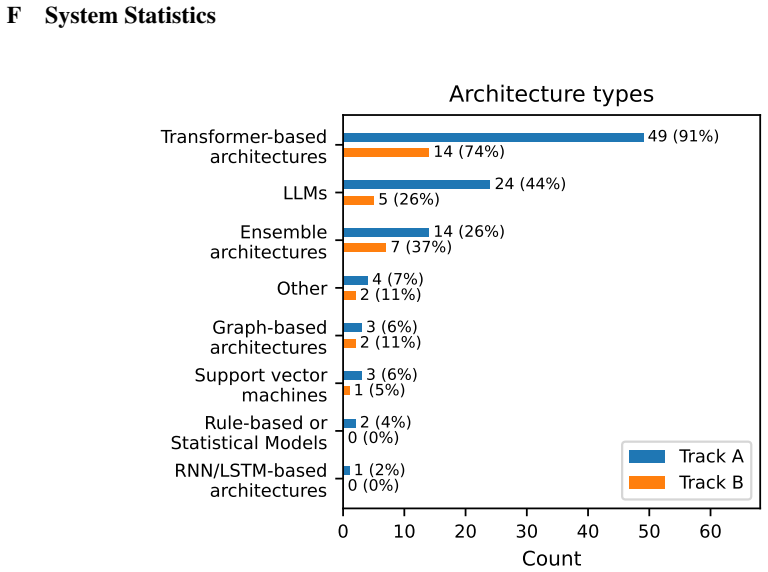




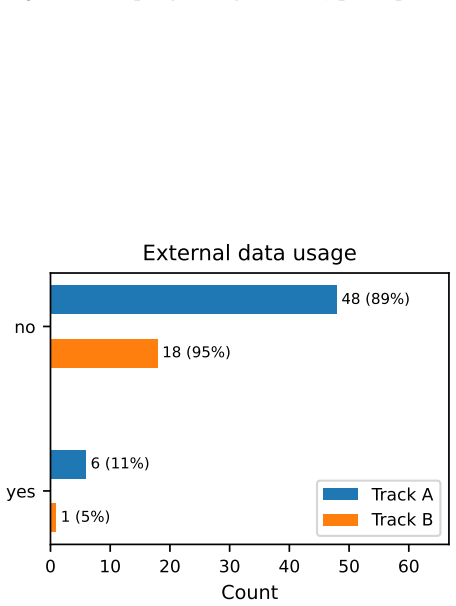
read the original abstract
We present the SemEval-2026 shared task on Dimensional Aspect-Based Sentiment Analysis (DimABSA), which improves traditional ABSA by modeling sentiment along valence-arousal (VA) dimensions rather than using categorical polarity labels. To extend ABSA beyond consumer reviews to public-issue discourse (e.g., political, energy, and climate issues), we introduce an additional task, Dimensional Stance Analysis (DimStance), which treats stance targets as aspects and reformulates stance detection as regression in the VA space. The task consists of two tracks: Track A (DimABSA) and Track B (DimStance). Track A includes three subtasks: (1) dimensional aspect sentiment regression, (2) dimensional aspect sentiment triplet extraction, and (3) dimensional aspect sentiment quadruplet extraction, while Track B includes only the regression subtask for stance targets. We also introduce a continuous F1 (cF1) metric to jointly evaluate structured extraction and VA regression. The task attracted more than 400 participants, resulting in 112 final submissions and 42 system description papers. We report baseline results, discuss top-performing systems, and analyze key design choices to provide insights into dimensional sentiment analysis at the aspect and stance-target levels. All resources are available on our GitHub repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the SemEval-2026 shared task on Dimensional Aspect-Based Sentiment Analysis (DimABSA). It claims to improve traditional ABSA by replacing categorical polarity labels with continuous valence-arousal (VA) regression, introduces DimStance for stance targets in public-issue discourse, defines two tracks (Track A with regression/triplet/quadruplet subtasks; Track B with regression only), a continuous F1 (cF1) metric, and reports baselines, top systems, and design insights from 112 submissions by 400+ participants.
Significance. If the dimensional VA formulation yields richer aspect-level representations than categorical labels, the task could advance nuanced sentiment and stance analysis beyond consumer reviews into political and issue-based discourse. The release of resources, large participation, and analysis of system design choices provide a useful benchmark and community resource for the field.
major comments (2)
- [Abstract, §1] Abstract and §1: The central claim that DimABSA 'improves traditional ABSA by modeling sentiment along valence-arousal (VA) dimensions rather than using categorical polarity labels' is not supported by any controlled comparison. The manuscript defines the task, subtasks, and cF1 metric and reports participant results, but contains no experiments measuring whether VA regression produces higher downstream utility, better human agreement, or richer insights than an equivalent categorical ABSA setup on the same aspects and texts.
- [§4] §4 (or metric definition section): The continuous F1 (cF1) metric is introduced to jointly evaluate structured extraction and VA regression, but the manuscript does not provide a formal justification or sensitivity analysis showing why this particular continuous formulation is preferable to standard F1 on discretized VA bins or to existing ABSA metrics; this choice is load-bearing for all reported results.
minor comments (2)
- [§3] Ensure all dataset statistics (e.g., number of aspects, VA distribution) are reported with exact counts and splits in a dedicated table.
- [§2] Clarify whether the DimStance track reuses the same texts and annotation guidelines as DimABSA or introduces new data; this affects claims about extending to public-issue discourse.
Simulated Author's Rebuttal
Thank you for the detailed review of our SemEval-2026 DimABSA task paper. We respond to the major comments below, noting that this is a shared task description rather than an empirical methods paper.
read point-by-point responses
-
Referee: [Abstract, §1] The central claim that DimABSA 'improves traditional ABSA by modeling sentiment along valence-arousal (VA) dimensions rather than using categorical polarity labels' is not supported by any controlled comparison. The manuscript defines the task, subtasks, and cF1 metric and reports participant results, but contains no experiments measuring whether VA regression produces higher downstream utility, better human agreement, or richer insights than an equivalent categorical ABSA setup on the same aspects and texts.
Authors: This manuscript is the official description of the SemEval-2026 shared task. The phrasing in the abstract and §1 is motivational, drawing on prior literature showing dimensional models capture nuance better than categorical labels. We do not include a controlled comparison because the paper's scope is task definition, resource release, and analysis of the 112 submissions from 400+ participants. The scale of participation and design insights provide community-level validation. We will revise the introduction to clarify that direct comparative experiments are encouraged as future work using the released data. revision: partial
-
Referee: [§4] The continuous F1 (cF1) metric is introduced to jointly evaluate structured extraction and VA regression, but the manuscript does not provide a formal justification or sensitivity analysis showing why this particular continuous formulation is preferable to standard F1 on discretized VA bins or to existing ABSA metrics; this choice is load-bearing for all reported results.
Authors: We agree a more detailed justification strengthens the paper. cF1 was designed to preserve the continuous VA information without arbitrary discretization thresholds and to unify extraction and regression evaluation via distance-based partial matching. In the revision we will add a sensitivity analysis subsection (or appendix) comparing cF1 against binned F1 variants and standard ABSA metrics on the development and test sets to show robustness and rationale. revision: yes
Circularity Check
Task proposal paper contains no derivations, predictions, or self-referential reductions
full rationale
The manuscript is a shared-task description that defines subtasks (regression, triplet/quadruplet extraction), a cF1 metric, tracks, and reports baselines plus participant outcomes. No equations, fitted parameters, or predictions appear that could reduce to their own inputs by construction. The motivational claim that VA modeling 'improves' categorical ABSA is an untested assumption for task design, not a derived result. No self-citations function as load-bearing uniqueness theorems or ansatzes. The paper is self-contained as a definitional proposal and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Rafif Alshawi, Amit Raj, Aleksey Kudelya, and Alexan- der Shirnin
Association for Computational Linguistics. Rafif Alshawi, Amit Raj, Aleksey Kudelya, and Alexan- der Shirnin. 2026. The Classics at SemEval-2026 9 Task 3: Combining Transformer Models and LLM- Generated Annotations for Dimensional Aspect- Based Sentiment Analysis. InProceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San ...
2026
-
[3]
Politikweli: A swahili-english code-switched twitter political misinformation classification dataset. InSpeech and Language Technologies for Low- Resource Languages, pages 3–17, Cham. Springer Nature Switzerland. Georgios Arampatzis and Avi Arampatzis. 2026. DUTH at SemEval-2026 Task 3: Multilingual Trans- former Models for Dimensional Stance Prediction A...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Knowmis-absa: an overview and a reference model for applications of sentiment analysis and aspect-based sentiment analysis.Artificial Intelli- gence Review, 55(7):5543–5574. A.J.W. De Vink, Filippos Karolos Ventirozos, Natalia Amat-Lefort, and Lifeng Han. 2026. QuadAI at SemEval-2026 Task 3: Ensemble Learning of Hy- brid RoBERTa and LLMs for Dimensional A...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
LoRA: Low-Rank Adaptation of Large Language Models
NYCU Speech Lab at SemEval-2026 Task 3: Heterogeneous Model Ensemble with Adap- tive Weighted V oting for Dimensional Aspect Senti- ment Quadruplet Extraction. InProceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California. Association for Computational Linguistics. 11 Edward J. Hu, Yelong Shen, Phillip Walli...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
In Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California
UNF-BMI at SemEval-2026 Task 3: Research Domain Criteria-Guided Large Language Models for Dimensional Aspect-Based Sentiment Analysis. In Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California. Association for Computational Linguis- tics. Svetlana Kiritchenko, Saif Mohammad, and Moham- mad Salameh. 2016...
2026
-
[7]
Chinese emobank: Building valence-arousal resources for dimensional sentiment analysis.ACM Transactions on Asian and Low-Resource Language Information Processing, 21(4):65. Lung-Hao Lee, Liang-Chih Yu, Natalia Loukashe- vich, Ilseyar Alimova, Alexander Panchenko, Tzu- Mi Lin, Zhe-Yu Xu, Jian-Yu Zhou, Guangmin Zheng, Jin Wang, Sharanya Awasthi, Jonas Becke...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
RPI Team at SemEval-2026 Task 3: An LLM-Encoder Ensemble for Coarse-to-Fine Valence- Arousal Sentiment Prediction. InProceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California. Association for Computational Linguistics. Saif Mohammad. 2018. Obtaining reliable human rat- ings of valence, arousal, and dominan...
-
[9]
AfriSenti: A Twitter sentiment analysis bench- mark for African languages. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13968–13981, Singa- pore. Association for Computational Linguistics. Shamsuddeen Hassan Muhammad, Nedjma Ousid- houm, Idris Abdulmumin, Jan Philip Wahle, Terry Ruas, Meriem Beloucif, Chr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
InProceedings of the 9th International WorkshoponSemantic Evaluation, pages 451–463
SemEval-2015 task 10: Sentiment analysis in twitter. InProceedings of the 9th International WorkshoponSemantic Evaluation, pages 451–463. Zhihao Ruan, Kaifeng Yang, Cheng Chen, Wenwen Dai, and Wenjia Mao. 2026. PAI at SemEval-2026 Task 3: An LLM and Data Redistribution Adaptation-Based Predictive Strategy for Valence-Arousal Scores. In Proceedings of the ...
2015
-
[11]
Journal of the Association for Information Science and Technology, 63(1):163–173
Sentiment strength detection for the social web. Journal of the Association for Information Science and Technology, 63(1):163–173. Vishal Thenuwara, Widanalage Mario Yomal De Mel, and Nisansa De Silva. 2026. Team VYN at SemEval- 2026 Task 3: Dimensional Aspect-Based Sentiment Analysis. InProceedings of the 20th International Workshop on Semantic Evaluatio...
-
[12]
Takoyaki at SemEval-2026 Task 3: En- sembling LLM Predictions using Demonstration Retrieval for Dimensional Aspect-based Sentiment 14 Analysis. InProceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California. Association for Computa- tional Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 580–595, Suzhou, China
T-MAD: Target-driven multimodal alignment for stance detection. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 580–595, Suzhou, China. Association for Computational Linguistics. Chenye Zhao and Cornelia Caragea. 2024. EZ- STANCE: A large dataset for English zero-shot stance detection. InProceedings of the...
2025
-
[14]
InFindings of the Association for Computa- tional Linguistics: EMNLP 2025, pages 5337–5356
What media frames reveal about stance: A dataset and study about memes in climate change dis- course. InFindings of the Association for Computa- tional Linguistics: EMNLP 2025, pages 5337–5356. Yan Zhou, Wangshicheng Shicheng Wang, Shiquan Wang, Mengjiao Bao, Ruiyu Fang, Shuangyong Song, Yongxiang Li, and Xuelong Li. 2026a. TeleAI at SemEval-2026 Task 3: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.