Recognition: no theorem link
Selective Neuron Amplification in Transformer Language Models
Pith reviewed 2026-05-12 04:23 UTC · model grok-4.3
The pith
Amplifying task-relevant neurons at inference time improves language model performance on uncertain cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large language models often fail on tasks they seem to already understand. In our experiments, this appears to be less about missing knowledge and more about certain internal circuits not being strongly activated during inference. We explore Selective Neuron Amplification, which increases the influence of task relevant neurons without changing the model's parameters. The method works at inference time and does not permanently alter the model. SNA helps mainly when the model is uncertain, while having low effect when the model is already confident. This suggests that some model failures are due to weak activation rather than lack of capability.
What carries the argument
Selective Neuron Amplification (SNA), a method that identifies task-relevant neurons and increases their influence during inference without altering model weights.
If this is right
- LLMs can recover from some failures by boosting weak but present knowledge circuits at runtime.
- Performance gains occur primarily in low-confidence scenarios, suggesting targeted use rather than blanket application.
- Models do not need parameter updates to address activation-related shortcomings.
- Task understanding can be present but under-expressed in the forward pass.
Where Pith is reading between the lines
- This approach might reduce the need for fine-tuning in some deployment scenarios.
- Similar amplification could be explored in other neural network architectures beyond transformers.
- Identifying task-relevant neurons reliably remains a key challenge for scaling the method.
Load-bearing premise
Task-relevant neurons can be reliably identified and amplified at inference without introducing new errors or unintended side effects in model behavior.
What would settle it
Observing that selective amplification causes the model to perform worse or generate errors on tasks where it was previously correct would challenge the central claim.
Figures

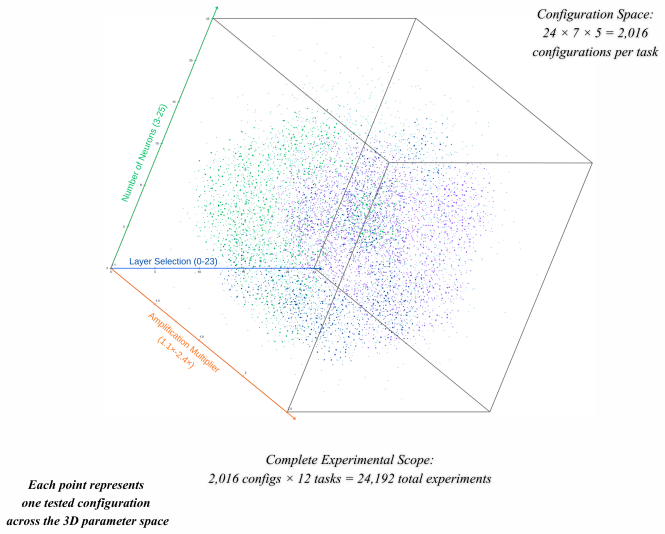

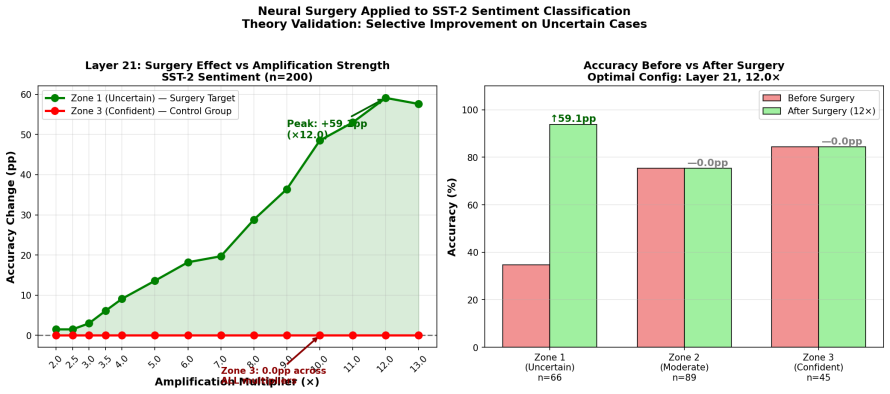
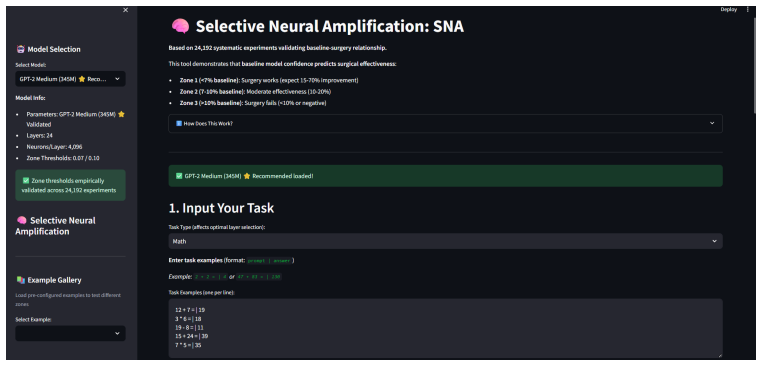
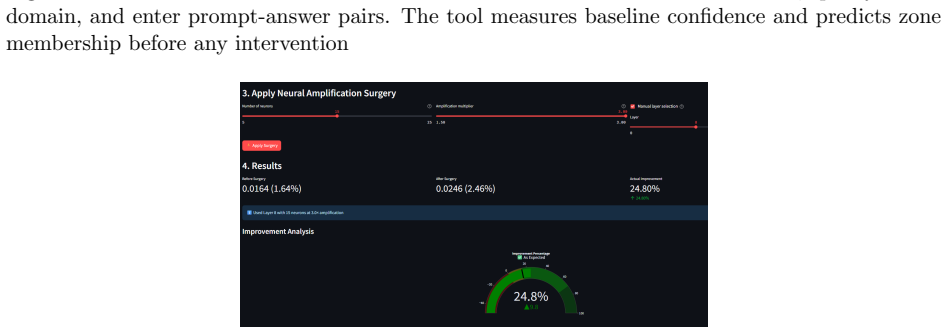

read the original abstract
Large language models often fail on tasks they seem to already understand. In our experiments, this appears to be less about missing knowledge and more about certain internal circuits not being strongly activated during inference. We explore Selective Neuron Amplification, which increases the influence of task relevant neurons without changing the model's parameters. The method works at inference time and does not permanently alter the model. SNA helps mainly when the model is uncertain, while having low effect when the model is already confident. This suggests that some model failures are due to weak activation rather than lack of capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM failures on tasks the model appears to understand often stem from weak activation of task-relevant internal circuits rather than missing capability or knowledge. It introduces Selective Neuron Amplification (SNA), an inference-time intervention that selectively increases the influence of identified task-relevant neurons without altering model parameters. Experiments reportedly show SNA improves performance primarily on uncertain predictions while having negligible effect on already-confident ones, supporting the weak-activation interpretation of failures.
Significance. If the empirical results and neuron-selection procedure can be validated, the work would be significant for mechanistic interpretability and reliable LLM deployment. It offers a lightweight, reversible way to probe and mitigate activation-strength failures, potentially distinguishing capability gaps from inference-time under-activation and inspiring new steering techniques that avoid retraining.
major comments (2)
- The manuscript provides no description of the neuron-identification procedure (gradient attribution, activation analysis, or circuit discovery), which is load-bearing for the central claim that SNA selectively amplifies task-relevant neurons without introducing new errors or unintended side effects on other inputs.
- No quantitative results, baselines, uncertainty metrics, or experimental controls are reported, so it is impossible to assess whether SNA's reported benefit is confined to uncertain cases or whether the effect sizes are large enough to support the interpretation that failures are due to weak activation rather than capability.
Simulated Author's Rebuttal
Thank you for the detailed and constructive referee report. We appreciate the emphasis on the need for methodological transparency and empirical rigor in validating the core claims of Selective Neuron Amplification. We address each major comment below and will revise the manuscript to incorporate the requested details and results.
read point-by-point responses
-
Referee: The manuscript provides no description of the neuron-identification procedure (gradient attribution, activation analysis, or circuit discovery), which is load-bearing for the central claim that SNA selectively amplifies task-relevant neurons without introducing new errors or unintended side effects on other inputs.
Authors: We agree that the neuron-identification procedure is central to the paper's claims and should have been described in detail. The revised manuscript will add a dedicated methods subsection explaining the gradient attribution approach used to identify task-relevant neurons, including the specific attribution metric, thresholding criteria, and validation steps. We will also include ablation experiments showing that SNA does not degrade performance on unrelated tasks or introduce new errors, thereby supporting the selectivity claim. revision: yes
-
Referee: No quantitative results, baselines, uncertainty metrics, or experimental controls are reported, so it is impossible to assess whether SNA's reported benefit is confined to uncertain cases or whether the effect sizes are large enough to support the interpretation that failures are due to weak activation rather than capability.
Authors: We acknowledge that the initial submission presented results primarily in qualitative terms. The revised version will include comprehensive quantitative evaluations: performance deltas with and without SNA across multiple tasks, comparisons to baselines such as random amplification and temperature scaling, uncertainty metrics (e.g., predictive entropy and token-level confidence), and control experiments on high-confidence cases. These additions will quantify effect sizes and demonstrate that gains are concentrated on uncertain predictions. revision: yes
Circularity Check
No circularity; empirical observations only
full rationale
The paper makes no mathematical derivations, equations, or load-bearing self-citations. All claims are framed as direct experimental observations (e.g., SNA improves performance mainly on uncertain inputs). No step reduces a prediction or result to a fitted parameter, self-definition, or prior author work by construction. The central interpretation—that failures stem from weak activation—is presented as an empirical suggestion without any formal chain that collapses to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: A suite for analyzing large language models across training and scaling. InProceedings of the 40th International ...
work page 2023
-
[3]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495. Association for Computational Linguistics, 2021
work page 2021
-
[4]
Neel Nanda and Joseph Bloom. TransformerLens, 2022. A Library for Mechanistic Inter- pretability of GPT-Style Language Models
work page 2022
-
[5]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020
work page 2020
-
[6]
Steering Llama 2 via contrastive activation addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering Llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 15504–15522. Association for Computational Linguistics, 2024. 27
work page 2024
-
[7]
Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
work page 2019
-
[8]
Activation scaling for steering and interpreting language models
Niklas Stoehr, Kevin Du, V´ esteinn Snæbjarnarson, Robert West, Ryan Cotterell, and Aaron Schein. Activation scaling for steering and interpreting language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 2024
work page 2024
-
[9]
Confidence regulation neurons in language models.arXiv preprint arXiv:2406.16254, 2024
Alessandro Stolfo, Benjie Wu, Wes Gurnee, Yonatan Belinkov, Xingyi Song, Mrinmaya Sachan, and Neel Nanda. Confidence regulation neurons in language models.arXiv preprint arXiv:2406.16254, 2024
-
[10]
Streamlit: The fastest way to build and share data apps, 2023
Streamlit Inc. Streamlit: The fastest way to build and share data apps, 2023
work page 2023
-
[11]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, David Leike, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
GLUE: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355. Association for Computational Linguistics, 2018
work page 2018
-
[13]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[14]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to AI ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.