Recognition: 2 theorem links
· Lean TheoremAccuracy Improvement of Semi-Supervised Segmentation Using Supervised ClassMix and Sup-Unsup Feature Discriminator
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
Supervised ClassMix pasting and feature alignment improve semi-supervised segmentation accuracy by 2.07% mIoU on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that pasting class labels and image regions taken directly from labeled data onto unlabeled images and their pseudo-labels, together with training a discriminator to make predictions on unlabeled images match those on labeled images, raises segmentation accuracy in the semi-supervised setting.
What carries the argument
Supervised ClassMix, which pastes accurate labels from labeled images instead of relying only on pseudo-labels, and the Sup-Unsup Feature Discriminator, which aligns feature predictions between labeled and unlabeled images.
If this is right
- Pseudo-label errors have less effect on final model accuracy.
- Feature representations become more consistent between the labeled and unlabeled portions of the training set.
- Segmentation models achieve higher mIoU without collecting additional pixel-level annotations.
- Training becomes more stable when only a small fraction of the data is labeled.
Where Pith is reading between the lines
- The same pasting and alignment steps could be tried on natural-image segmentation benchmarks to test whether the gains generalize beyond medical data.
- The feature-alignment idea might help other semi-supervised tasks that suffer from domain shift between labeled and unlabeled examples.
- Pairing the approach with existing pseudo-label refinement methods could produce still larger improvements.
Load-bearing premise
The pseudo-labels produced for the unlabeled images are accurate enough that adding supervised labels and forcing feature alignment will produce a net gain.
What would settle it
Re-running the method on a non-medical dataset such as Cityscapes and measuring no mIoU gain or a loss relative to the baseline would show the two modifications do not deliver the claimed benefit outside the tested cases.
Figures


read the original abstract
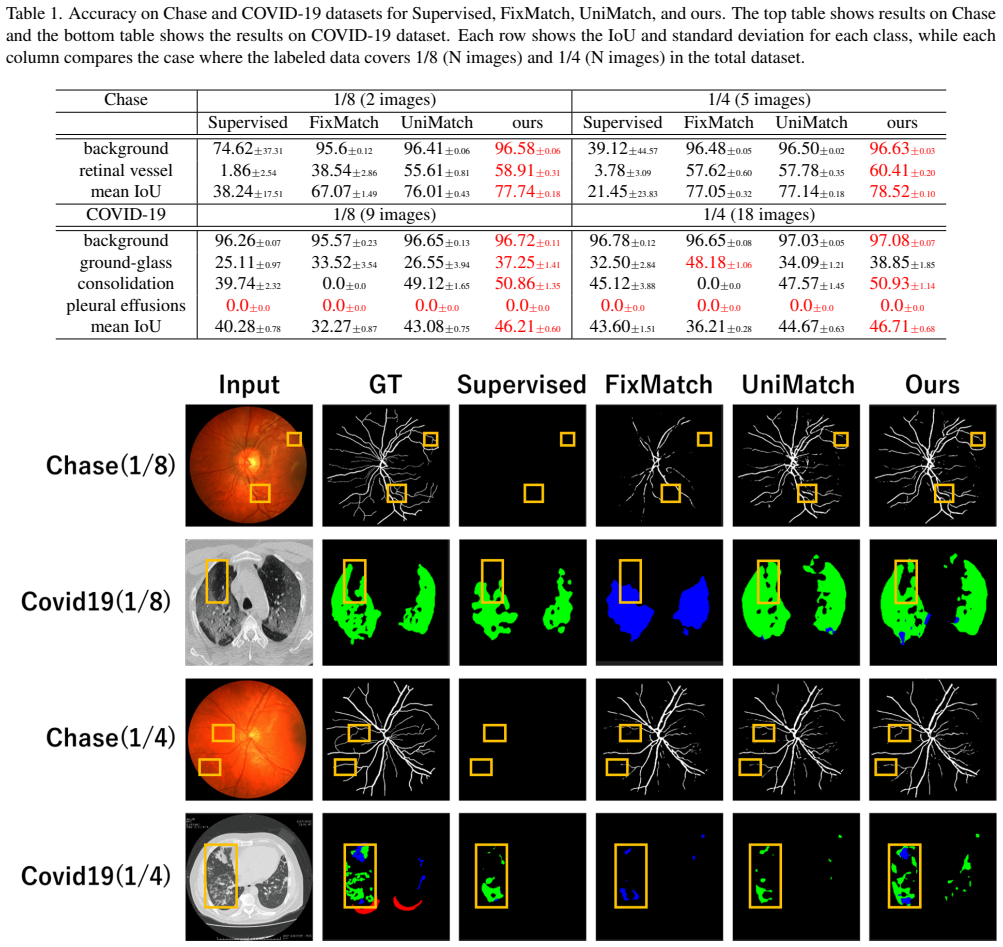
In semantic segmentation, the creation of pixel-level labels for training data incurs significant costs. To address this problem, semi-supervised learning, which utilizes a small number of labeled images alongside unlabeled images to enhance the performance, has gained attention. A conventional semi-supervised learning method, ClassMix, pastes class labels predicted from unlabeled images onto other images. However, since ClassMix performs operations using pseudo-labels obtained from unlabeled images, there is a risk of handling inaccurate labels. Additionally, there is a gap in data quality between labeled and unlabeled images, which can impact the feature maps. This study addresses these two issues. First, we propose a method where class labels from labeled images, along with the corresponding image regions, are pasted onto unlabeled images and their pseudo-labeled images. Second, we introduce a method that trains the model to make predictions on unlabeled images more similar to those on labeled images. Experiments on the Chase and COVID-19 datasets demonstrated an average improvement of 2.07% in mIoU compared to conventional semi-supervised learning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two modifications to ClassMix for semi-supervised semantic segmentation: supervised ClassMix, which pastes labeled image regions and their ground-truth labels onto unlabeled images (and their pseudo-labels), and a Sup-Unsup Feature Discriminator that aligns feature maps between labeled and unlabeled images via an adversarial loss. Experiments on the Chase and COVID-19 datasets report an average 2.07% mIoU gain over conventional semi-supervised baselines.
Significance. If the gains prove robust, the modifications offer a lightweight, practical extension to ClassMix that directly targets pseudo-label noise and domain gap between labeled/unlabeled data. The ideas are simple to implement and could be useful in medical imaging where annotation cost is high. However, the narrow scope (two medical datasets only) and absence of component ablations limit the strength of the contribution.
major comments (1)
- [Experiments] Experiments section: The headline 2.07% mIoU improvement is presented as the joint effect of supervised ClassMix and the feature discriminator, yet no ablation studies isolate each component (e.g., baseline ClassMix vs. ClassMix + supervised pasting only vs. ClassMix + discriminator only). Without these controls it is impossible to determine whether both proposed mechanisms are load-bearing or whether the gain arises from hyper-parameter re-tuning around the baseline. This directly undermines the central empirical claim.
minor comments (2)
- [Abstract] Abstract and §4: The baselines are referred to only as 'conventional semi-supervised learning methods' without naming them (e.g., standard ClassMix, Mean Teacher, FixMatch) or providing the exact mIoU numbers for each. This makes the reported average improvement difficult to interpret.
- [Method] §3.2: The architecture and training objective of the Sup-Unsup Feature Discriminator are described at a high level; the precise loss formulation, discriminator network details, and how its output is combined with the segmentation loss should be given explicitly (ideally with an equation).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that ablation studies are required to isolate the contributions of supervised ClassMix and the Sup-Unsup Feature Discriminator and will add them to the revised manuscript.
read point-by-point responses
-
Referee: Experiments section: The headline 2.07% mIoU improvement is presented as the joint effect of supervised ClassMix and the feature discriminator, yet no ablation studies isolate each component (e.g., baseline ClassMix vs. ClassMix + supervised pasting only vs. ClassMix + discriminator only). Without these controls it is impossible to determine whether both proposed mechanisms are load-bearing or whether the gain arises from hyper-parameter re-tuning around the baseline. This directly undermines the central empirical claim.
Authors: We agree that the absence of component-wise ablations limits the strength of the empirical claims. In the revised manuscript we will add a dedicated ablation table that evaluates four controlled variants on both Chase and COVID-19 datasets while keeping all hyper-parameters identical: (1) standard ClassMix baseline, (2) ClassMix augmented only with supervised pasting, (3) ClassMix augmented only with the Sup-Unsup Feature Discriminator, and (4) the full combination. These results will quantify the incremental mIoU gain attributable to each mechanism and will rule out hyper-parameter re-tuning as the source of the reported improvement. revision: yes
Circularity Check
No circularity: purely empirical method with external baselines
full rationale
The paper introduces two algorithmic modifications (supervised ClassMix pasting and a supervised-unsupervised feature discriminator) to an existing semi-supervised segmentation baseline and reports measured mIoU gains on two external medical datasets. No derivation, equations, predictions, or first-principles claims are present that could reduce by construction to author-defined inputs, fitted parameters, or self-citations. All performance claims rest on direct experimental comparison against conventional methods, satisfying the default expectation of non-circularity for empirical work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a method where class labels from labeled images... are pasted onto unlabeled images... Second, we introduce a method that trains the model to make predictions on unlabeled images more similar to those on labeled images.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on the Chase and COVID-19 datasets demonstrated an average improvement of 2.07% in mIoU
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ganomaly: Semi-supervised anomaly detection via adversarial training
Samet Akcay, Amir Atapour-Abarghouei, and Toby P Breckon. Ganomaly: Semi-supervised anomaly detection via adversarial training. InComputer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part III 14, pages 622–637. Springer, 2019. 3
2018
-
[2]
Segnet: A deep convolutional encoder-decoder architecture for image segmentation.IEEE transactions on pattern anal- ysis and machine intelligence, 39(12):2481–2495, 2017
Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation.IEEE transactions on pattern anal- ysis and machine intelligence, 39(12):2481–2495, 2017. 1
2017
-
[3]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018. 1, 3, 6
2018
-
[4]
Semantic seg- mentation using generative adversarial network
Wenxin Chen, Ting Zhang, and Xing Zhao. Semantic seg- mentation using generative adversarial network. In2021 40th Chinese Control Conference (CCC), pages 8492–8495,
-
[5]
Semi-supervised semantic segmentation with cross pseudo supervision
Xiaokang Chen, Yuhui Yuan, Gang Zeng, and Jingdong Wang. Semi-supervised semantic segmentation with cross pseudo supervision. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2613–2622, 2021. 2
2021
-
[6]
Terrance Devries and Graham W. Taylor. Improved regular- ization of convolutional neural networks with cutout.ArXiv, abs/1708.04552, 2017. 2
work page internal anchor Pith review arXiv 2017
-
[7]
Rudnicka, Christo- pher G
Muhammad Moazam Fraz, Paolo Remagnino, Andreas Hoppe, Bunyarit Uyyanonvara, Alicja R. Rudnicka, Christo- pher G. Owen, and Sarah A. Barman. Chase db1: Retinal vessel reference dataset, 2012. 2
2012
-
[8]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 2, 3
2014
-
[9]
Chase: A large-scale and pragmatic chinese dataset for cross-database context-dependent text-to-sql
Jiaqi Guo, Ziliang Si, Yu Wang, Qian Liu, Ming Fan, Jian-Guang Lou, Zijiang Yang, and Ting Liu. Chase: A large-scale and pragmatic chinese dataset for cross-database context-dependent text-to-sql. InProceedings of the 59th An- nual Meeting of the Association for Computational Linguis- tics and the 11th International Joint Conference on Natural Language Pr...
2021
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 6
2016
-
[11]
Consistency-based semi-supervised learning for object de- tection
Jisoo Jeong, Seungeui Lee, Jeesoo Kim, and Nojun Kwak. Consistency-based semi-supervised learning for object de- tection. InAdvances in Neural Information Processing Sys- tems. Curran Associates, Inc., 2019. 2
2019
-
[12]
Pseudo-label: The simple and effi- cient semi-supervised learning method for deep neural net- works
Dong-Hyun Lee et al. Pseudo-label: The simple and effi- cient semi-supervised learning method for deep neural net- works. InWorkshop on challenges in representation learn- ing, ICML, page 896. Atlanta, 2013. 1
2013
-
[13]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 3431–3440, 2015. 1
2015
-
[14]
Classmix: Segmentation-based data aug- mentation for semi-supervised learning
Viktor Olsson, Wilhelm Tranheden, Juliano Pinto, and Lennart Svensson. Classmix: Segmentation-based data aug- mentation for semi-supervised learning. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 1369–1378, 2021. 1, 2, 3 8
2021
-
[15]
Covid-19 ct segmentation dataset.https: / / www
QMENTA. Covid-19 ct segmentation dataset.https: / / www . qmenta . com / blog / covid - 19 - ct - segmentation- dataset, 2020. Accessed: 2024-09-
2020
-
[16]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015. 1
2015
-
[17]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015. 6
2015
-
[18]
Unsupervised anomaly detection with generative adversarial networks to guide marker discovery
Thomas Schlegl, Philipp Seeb ¨ock, Sebastian M Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. InInternational conference on in- formation processing in medical imaging, pages 146–157. Springer, 2017. 3
2017
-
[19]
Fixmatch: Simplifying semi-supervised learning with consistency and confidence
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in neural information processing systems, 33:596– 608, 2020. 5
2020
-
[20]
Semi supervised semantic segmentation using generative ad- versarial network
Nasim Souly, Concetto Spampinato, and Mubarak Shah. Semi supervised semantic segmentation using generative ad- versarial network. InProceedings of the IEEE international conference on computer vision, pages 5688–5696, 2017. 3
2017
-
[21]
Cell image segmentation by integrating pix2pixs for each class
Hiroki Tsuda and Kazuhiro Hotta. Cell image segmentation by integrating pix2pixs for each class. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2019. 3
2019
-
[22]
Revisiting weak-to-strong consistency in semi-supervised semantic segmentation
Lihe Yang, Lei Qi, Litong Feng, Wayne Zhang, and Yinghuan Shi. Revisiting weak-to-strong consistency in semi-supervised semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7236–7246, 2023. 2, 6
2023
-
[23]
Cutmix: Regu- larization strategy to train strong classifiers with localizable features
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regu- larization strategy to train strong classifiers with localizable features. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 6023–6032, 2019. 2
2019
-
[24]
Ef- ficient gan-based anomaly detection.arXiv preprint arXiv:1802.06222, 2018
Houssam Zenati, Chuan Sheng Foo, Bruno Lecouat, Gau- rav Manek, and Vijay Ramaseshan Chandrasekhar. Ef- ficient gan-based anomaly detection.arXiv preprint arXiv:1802.06222, 2018. 3
-
[25]
Dauphin, and David Lopez-Paz
Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimiza- tion. InInternational Conference on Learning Representa- tions, 2018. 2
2018
-
[26]
Random erasing data augmentation
Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. Random erasing data augmentation. InProceed- ings of the AAAI conference on artificial intelligence, pages 13001–13008, 2020. 2
2020
-
[27]
Pseudoseg: Designing pseudo labels for semantic segmentation
Yuliang Zou, Zizhao Zhang, Han Zhang, Chun-Liang Li, Xiao Bian, Jia-Bin Huang, and Tomas Pfister. Pseudoseg: Designing pseudo labels for semantic segmentation. InIn- ternational Conference on Learning Representations, 2021. 2 9
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.