Recognition: unknown
A Utility-preserving De-identification Pipeline for Cross-hospital Radiology Data Sharing
Pith reviewed 2026-05-10 18:01 UTC · model grok-4.3
The pith
A pipeline generates synthetic radiology images that remove privacy details while keeping diagnostic features for AI training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The UPDP pipeline compiles privacy blacklists and pathology whitelists to guide synthesis of privacy-filtered image counterparts and ID-filtered reports, such that models trained on the resulting data maintain competitive diagnostic accuracy while showing reduced identity inference accuracy and enable performance gains when combined with local data in cross-hospital settings.
What carries the argument
The generative filtering mechanism that synthesizes privacy-filtered and pathology-reserved image counterparts from original radiology images, guided by term blacklists and whitelists.
If this is right
- Models trained on the de-identified data maintain competitive diagnostic accuracy compared with those trained on the original data.
- Identity-related accuracy exhibits a marked decline on de-identified data, confirming privacy protection.
- De-identified data combined with local data yields better performance than local data alone in cross-hospital settings.
Where Pith is reading between the lines
- The approach could support creation of larger pooled radiology datasets for training more robust medical AI systems.
- Hospitals might adopt similar pipelines to meet privacy regulations while still advancing collaborative model development.
- The filtering technique could extend to other imaging modalities if the synthesis step generalizes beyond chest X-rays.
Load-bearing premise
The generative filtering mechanism can reliably synthesize image counterparts that eliminate privacy-sensitive information without introducing artifacts or altering pathology cues in ways that degrade downstream diagnostic model performance.
What would settle it
If models trained on the de-identified images show substantially lower accuracy on pathology detection tasks than models trained on the original images, or if identity-related accuracy does not decline, the utility-preserving claim would not hold.
Figures


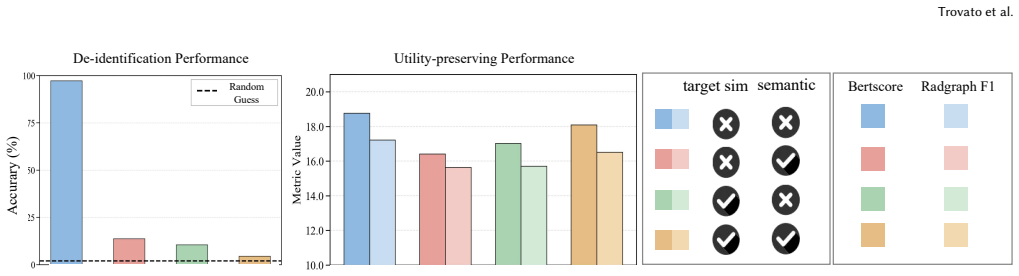
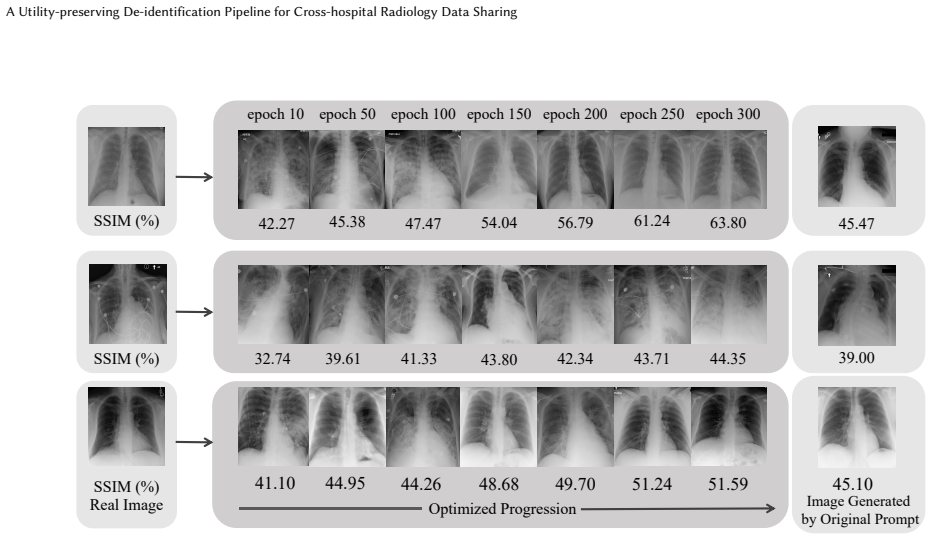

read the original abstract
Large-scale radiology data are critical for developing robust medical AI systems. However, sharing such data across hospitals remains heavily constrained by privacy concerns. Existing de-identification research in radiology mainly focus on removing identifiable information to enable compliant data release. Yet whether de-identified radiology data can still preserve sufficient utility for large-scale vision-language model training and cross-hospital transfer remains underexplored. In this paper, we introduce a utility-preserving de-identification pipeline (UPDP) for cross-hospital radiology data sharing. Specifically, we compile a blacklist of privacy-sensitive terms and a whitelist of pathology-related terms. For radiology images, we use a generative filtering mechanism that synthesis a privacy-filtered and pathology-reserved counterparts of the original images. These synthetic image counterparts, together with ID-filtered reports, can then be securely shared across hospitals for downstream model development and evaluation. Experiments on public chest X-ray benchmarks demonstrate that our method effectively removes privacy-sensitive information while preserving diagnostically relevant pathology cues. Models trained on the de-identified data maintain competitive diagnostic accuracy compared with those trained on the original data, while exhibiting a marked decline in identity-related accuracy, confirming effective privacy protection. In the cross-hospital setting, we further show that de-identified data can be combined with local data to yield better performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a utility-preserving de-identification pipeline (UPDP) for cross-hospital radiology data sharing. It compiles blacklists of privacy-sensitive terms and whitelists of pathology terms for reports, then applies a generative filtering mechanism to synthesize privacy-filtered image counterparts that aim to remove identity cues while preserving diagnostic pathology information. The de-identified images and filtered reports are intended for secure sharing. Experiments on public chest X-ray benchmarks are claimed to show that models trained on the de-identified data achieve competitive diagnostic accuracy relative to original data, with reduced identity-related accuracy, and that combining de-identified data with local data improves cross-hospital performance.
Significance. If the generative filtering reliably removes privacy-sensitive features without degrading pathology cues or introducing artifacts, the work could meaningfully advance privacy-compliant sharing of large radiology datasets, supporting better training of vision-language models and improved generalization across institutions. The dual focus on images and reports, plus the cross-hospital evaluation, addresses a practical barrier in medical AI.
major comments (3)
- [Abstract] Abstract: The central claims that de-identified data yields 'competitive diagnostic accuracy' and a 'marked decline in identity-related accuracy' (plus improved cross-hospital performance) are asserted without any quantitative numbers, baselines, error bars, statistical tests, or specific metrics. This absence prevents evaluation of whether the generative filtering mechanism actually achieves the stated privacy-utility tradeoff or if performance differences arise from other factors.
- [Method] Method (generative filtering description): No architecture, training objective, loss terms balancing privacy removal against pathology preservation, hyperparameters, or fidelity metrics (e.g., reconstruction error or feature similarity) are provided for the generative model that synthesizes image counterparts. Without these details the claim that synthetic images 'eliminate privacy-sensitive information without introducing artifacts or altering pathology cues' cannot be assessed and is load-bearing for all downstream empirical assertions.
- [Experiments] Experiments: No tables, figures, or specific results are referenced that report diagnostic accuracy, identity accuracy, dataset sizes, baselines (e.g., standard de-identification methods), or cross-hospital transfer numbers. The absence of such evidence undermines the experimental validation of the pipeline.
minor comments (2)
- [Abstract] Abstract: 'that synthesis a privacy-filtered' is grammatically incorrect and should read 'that synthesizes a privacy-filtered'.
- [Abstract] The abstract refers to 'public chest X-ray benchmarks' without naming the specific datasets (e.g., MIMIC-CXR, CheXpert) used; this should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the emphasis on providing quantitative evidence and methodological specifics to support the claims. We address each major comment below and have revised the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that de-identified data yields 'competitive diagnostic accuracy' and a 'marked decline in identity-related accuracy' (plus improved cross-hospital performance) are asserted without any quantitative numbers, baselines, error bars, statistical tests, or specific metrics. This absence prevents evaluation of whether the generative filtering mechanism actually achieves the stated privacy-utility tradeoff or if performance differences arise from other factors.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claims. In the revised manuscript, we have expanded the abstract to report specific metrics including diagnostic accuracy values with baselines, identity-related accuracy reductions, cross-hospital performance improvements, and references to error bars and statistical tests from the experiments. This allows direct evaluation of the privacy-utility tradeoff. revision: yes
-
Referee: [Method] Method (generative filtering description): No architecture, training objective, loss terms balancing privacy removal against pathology preservation, hyperparameters, or fidelity metrics (e.g., reconstruction error or feature similarity) are provided for the generative model that synthesizes image counterparts. Without these details the claim that synthetic images 'eliminate privacy-sensitive information without introducing artifacts or altering pathology cues' cannot be assessed and is load-bearing for all downstream empirical assertions.
Authors: We acknowledge that the original method description was high-level and omitted implementation specifics. The revised manuscript now includes the full architecture of the generative model, the training objective with explicit loss terms for privacy removal versus pathology preservation, all hyperparameters, and fidelity metrics such as reconstruction error and feature similarity. These additions enable assessment of the claims regarding artifact-free synthesis and pathology preservation. revision: yes
-
Referee: [Experiments] Experiments: No tables, figures, or specific results are referenced that report diagnostic accuracy, identity accuracy, dataset sizes, baselines (e.g., standard de-identification methods), or cross-hospital transfer numbers. The absence of such evidence undermines the experimental validation of the pipeline.
Authors: We agree that the experiments section requires concrete results for validation. The revised version now includes tables and figures reporting diagnostic accuracy, identity accuracy, dataset sizes, comparisons against standard de-identification baselines, and cross-hospital transfer numbers, along with the associated statistical details. This provides the empirical support for the pipeline's effectiveness. revision: yes
Circularity Check
No circularity in empirical pipeline
full rationale
The paper presents an empirical utility-preserving de-identification pipeline (UPDP) based on blacklists/whitelists for reports and a generative filtering mechanism for images, evaluated via experiments on public chest X-ray benchmarks. Claims rest on observed outcomes (competitive diagnostic accuracy, reduced identity accuracy, improved cross-hospital performance) rather than any derivation, equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps reduce to inputs by construction; the work is self-contained against external datasets with no mathematical derivation chain to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauff- mann, et al. 2024. Phi-4 technical report.arXiv preprint arXiv:2412.08905(2024)
work page internal anchor Pith review arXiv 2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. 65–72
2005
-
[4]
Roth, Andrea Borondy Kitts, Raym Geis, Carol C
Juan Carlos Batlle, Keith Dreyer, Bibb Allen, Tessa Cook, Christopher J. Roth, Andrea Borondy Kitts, Raym Geis, Carol C. Wu, Matt P. Lungren, Jay Patti, Adam Prater, Daniel Rubin, Safwan Halabi, Mike Tilkin, Tom Hoffman, Laura Coombs, and Christoph Wald. 2021. Data Sharing of Imaging in an Evolving Health Care World: Report of the ACR Data Sharing Workgro...
-
[5]
Christian Bluethgen, Pierre Chambon, Jean-Benoit Delbrouck, Rogier Van Der Sluijs, Małgorzata Połacin, Juan Manuel Zambrano Chaves, Tanishq Mathew Abraham, Shivanshu Purohit, Curtis P Langlotz, and Akshay S Chaudhari. 2025. A vision–language foundation model for the generation of realistic chest x-ray images.Nature Biomedical Engineering9, 4 (2025), 494–506
2025
-
[6]
David Carrell, Bradley Malin, John Aberdeen, Samuel Bayer, Cheryl Clark, Ben Wellner, and Lynette Hirschman. 2013. Hiding in plain sight: use of realistic surrogates to reduce exposure of protected health information in clinical text. Journal of the American Medical Informatics Association20, 2 (2013), 342–348. doi:10.1136/amiajnl-2012-001034
- [7]
-
[8]
Wenting Chen, Pengyu Wang, Hui Ren, Lichao Sun, Quanzheng Li, Yixuan Yuan, and Xiang Li. 2024. Medical image synthesis via fine-grained image-text alignment and anatomy-pathology prompting. InInternational conference on medical image computing and computer-assisted intervention. Springer, 240–250
2024
- [9]
-
[10]
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Sonya E Shooshan, Laritza Rodriguez, Sameer Antani, George R Thoma, and Clement J McDonald
-
[11]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association23, 2 (2015), 304–310
2015
-
[12]
Kohli, Marc B
Dina Demner-Fushman, Marc D. Kohli, Marc B. Rosenman, Sonya E. Shooshan, Luciano Rodriguez, Sameer Antani, George R. Thoma, and Clement J. McDonald
-
[13]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association (JAMIA)23, 2 (2016), 304–310. doi:10.1093/jamia/ocv080
- [14]
-
[15]
Khaled El Emam, Elizabeth Jonker, Luk Arbuckle, and Bradley Malin. 2011. A systematic review of re-identification attacks on health data.PloS one6, 12 (2011), e28071
2011
-
[16]
Maayan Frid-Adar, Idit Diamant, Eyal Klang, Michal Amitai, Jacob Goldberger, and Hayit Greenspan. 2018. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification.Neurocomputing 321 (2018), 321–331
2018
-
[17]
Abdullah Hosseini and Ahmed Serag. 2025. Is synthetic data generation effective in maintaining clinical biomarkers? Investigating diffusion models across diverse imaging modalities.Frontiers in Artificial Intelligence7 (2025), 1454441
2025
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[19]
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al
-
[20]
InProceedings of the AAAI conference on artificial intelligence, Vol
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 590–597
- [21]
-
[22]
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. 2019. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data6, 1 (2019), 317
2019
-
[23]
Kaissis, Marcus R
Georgios A. Kaissis, Marcus R. Makowski, Daniel Rückert, and Rickmer F. Braren
-
[24]
Secure, privacy-preserving and federated machine learning in medical imaging.Nature Machine Intelligence2, 6 (2020), 305–311. doi:10.1038/s42256- 020-0186-1
-
[25]
Aghiles Kebaili, Jérôme Lapuyade-Lahorgue, Pierre Vera, and Su Ruan. 2025. Multi-modal MRI synthesis with conditional latent diffusion models for data aug- mentation in tumor segmentation.Computerized Medical Imaging and Graphics 123 (2025), 102532
2025
-
[26]
Bardia Khosravi, Frank Li, Theo Dapamede, Pouria Rouzrokh, Cooper U Gamble, Hari M Trivedi, Cody C Wyles, Andrew B Sellergren, Saptarshi Purkayastha, Bradley J Erickson, et al. 2024. Synthetically enhanced: unveiling synthetic data’s potential in medical imaging research.EBioMedicine104 (2024)
2024
-
[27]
Lennart R Koetzier, Jie Wu, Domenico Mastrodicasa, Aline Lutz, Matthew Chung, W Adam Koszek, Jayanth Pratap, Akshay S Chaudhari, Pranav Rajpurkar, Matthew P Lungren, et al. 2024. Generating synthetic data for medical imaging. Radiology312, 3 (2024), e232471
2024
-
[28]
Ira Ktena, Olivia Wiles, Isabela Albuquerque, Sylvestre-Alvise Rebuffi, Ryutaro Tanno, Abhijit Guha Roy, Shekoofeh Azizi, Danielle Belgrave, Pushmeet Kohli, Taylan Cemgil, et al . 2024. Generative models improve fairness of medical classifiers under distribution shifts.Nature Medicine30, 4 (2024), 1166–1173
2024
-
[29]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
- [30]
-
[31]
Dima Mamdouh, Mariam Attia, Mohamed Osama, Nesma Mohamed, Abdelrah- man Lotfy, Tamer Arafa, Essam A Rashed, and Ghada Khoriba. 2025. Advance- ments in Radiology Report Generation: A Comprehensive Analysis.Bioengineer- ing12, 7 (2025), 693
2025
-
[32]
Deven McGraw. 2013. Building public trust in uses of Health Insurance Portability and Accountability Act de-identified data.Journal of the American Medical Informatics Association (JAMIA)20, 1 (2013), 29–34. doi:10.1136/amiajnl-2012- 000936
-
[33]
Maram Mahmoud A Monshi, Josiah Poon, and Vera Chung. 2020. Deep learning in generating radiology reports: A survey.Artificial Intelligence in Medicine106 (2020), 101878
2020
-
[34]
Stephen M Moore, David R Maffitt, Kirk E Smith, Justin S Kirby, Kenneth W Clark, John B Freymann, Bruce A Vendt, Lawrence R Tarbox, and Fred W Prior
-
[35]
De-identification of medical images with retention of scientific research value.Radiographics35, 3 (2015), 727–735
2015
-
[36]
Daniel I Morís, Joaquim de Moura, Jorge Novo, and Marcos Ortega. 2024. Adapted generative latent diffusion models for accurate pathological analysis in chest X-ray images.Medical & Biological Engineering & Computing62, 7 (2024), 2189– 2212
2024
-
[37]
Ishna Neamatullah, Margaret M Douglass, Li-Wei H Lehman, Andrew Reisner, Mauricio Villarroel, William J Long, Peter Szolovits, George B Moody, Roger G Mark, and Gari D Clifford. 2008. Automated de-identification of free-text medical records.BMC medical informatics and decision making8, 1 (2008), 32
2008
-
[38]
Ting Pang, Peigao Li, and Lijie Zhao. 2023. A survey on automatic generation of medical imaging reports based on deep learning.BioMedical Engineering OnLine 22, 1 (2023), 48
2023
-
[39]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
-
[40]
Yuning Qiu, Andong Wang, Chao Li, Haonan Huang, Guoxu Zhou, and Qibin Zhao. 2025. Steps: sequential probability tensor estimation for text-to-image hard prompt search. InProceedings of the Computer Vision and Pattern Recognition Conference. 28640–28650
2025
-
[41]
Christopher G. Schwarz, Walter K. Kremers, Terry M. Therneau, Richard R. Sharp, Jeffrey L. Gunter, Prashanthi Vemuri, Arvin Arani, Anthony J. Spychalla, Kejal Kantarci, David S. Knopman, Ronald C. Petersen, and Clifford R. Jack. 2019. Identi- fication of anonymous MRI research participants with face-recognition software. New England Journal of Medicine381...
-
[42]
Hoo-Chang Shin, Kirk Roberts, Le Lu, Dina Demner-Fushman, Jianhua Yao, and Ronald M Summers. 2016. Learning to read chest x-rays: Recurrent neural cascade model for automated image annotation. InProceedings of the IEEE conference on computer vision and pattern recognition. 2497–2506
2016
-
[43]
Ryutaro Tanno, David G. T. Barrett, Amanda Sellergren, et al. 2025. Collaboration between clinicians and vision–language models in radiology report generation. Nature Medicine31 (2025), 599–608. doi:10.1038/s41591-024-03302-1
-
[44]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. 2025. Gemma 3 technical report.arXiv preprint arXiv:2503.19786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
2017.The EU General Data Protection Regulation (GDPR): A Practical Guide
Paul Voigt and Axel von dem Bussche. 2017.The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer Cham. XII+339 pages. doi:10. Trovato et al. 1007/978-3-319-57959-7
2017
-
[46]
Shuxin Yang, Xian Wu, Shen Ge, S Kevin Zhou, and Li Xiao. 2022. Knowledge matters: Chest radiology report generation with general and specific knowledge. Medical image analysis80 (2022), 102510
2022
-
[47]
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu
-
[48]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mma-diffusion: Multimodal attack on diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7737–7746
-
[49]
Yue Yao, Zelin Wen, Yan Tong, Xinyu Tian, Xuqing Li, Xiao Ma, Dongliang Xu, and Tom Gedeon. 2026. Thought Graph Traversal for Test-time Scaling in Chest X- ray VLLMs.Pattern Recognition(2026), 113639. doi:10.1016/j.patcog.2026.113639
-
[50]
Yue Yao, Liang Zheng, Xiaodong Yang, Milind Napthade, and Tom Gedeon. 2023. Attribute descent: Simulating object-centric datasets on the content level and beyond.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 4 (2023), 2489–2505
2023
-
[51]
Di You, Fenglin Liu, Shen Ge, Xiaoxia Xie, Jing Zhang, and Xian Wu. 2021. Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 72–82
2021
-
[52]
Jianbo Yuan, Haofu Liao, Rui Luo, and Jiebo Luo. 2019. Automatic radiology report generation based on multi-view image fusion and medical concept enrichment. InInternational conference on medical image computing and computer-assisted intervention. Springer, 721–729
2019
-
[53]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. 2023. Biomed- clip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915(2023)
work page internal anchor Pith review arXiv 2023
-
[54]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.