Recognition: 2 theorem links
· Lean TheoremCritical Inker: Scaffolding Critical Thinking in AI-Assisted Writing Through Socratic Questioning
Pith reviewed 2026-05-10 17:19 UTC · model grok-4.3
The pith
Critical Inker uses Socratic questions and visual highlights to help writers identify and correct logical errors in AI-assisted drafts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Critical Inker implements a Socratic chatbot and a visual feedback layer that together analyze a writer's text for its underlying arguments and logical validity, then deliver either questions that prompt the user to recognize and fix errors or direct highlights that flag those errors without requiring conversation. The system is built on technical components for argument extraction and validity checking, which are evaluated against ground-truth annotations, and is further explored through a small-scale pilot that gathers early user reactions.
What carries the argument
Socratic chatbot paired with visual feedback that performs logical analysis on the text to surface errors through questions or highlights.
Load-bearing premise
The reported accuracy numbers and pilot observations will continue to support effective scaffolding when the tool is used by many different writers on varied, real-world documents.
What would settle it
A larger user study that measures whether participants using Critical Inker produce drafts with fewer logical errors or show greater independent detection of flaws compared with participants using standard AI writing assistance.
Figures



read the original abstract
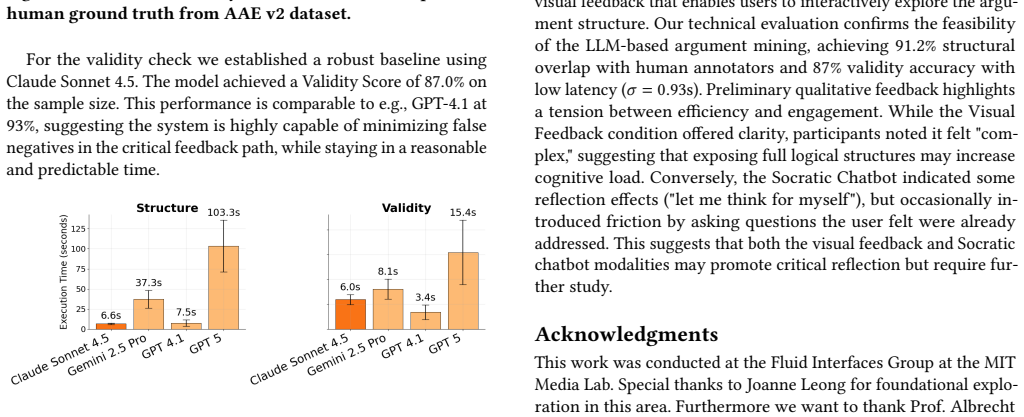
As Large Language Models (LLMs) increasingly automate writing tasks, there is a growing risk of cognitive deskilling where users offload critical thinking to the system. To address this, we introduce Critical Inker, a writing tool designed to scaffold critical reflection during writing through logical analysis and socratic feedback. We present two methods: (1) A Socratic chatbot using questions to help them realize and fix logical errors in their writing and (2) Visual Feedback, which highlights logical errors in the text without dialog. We detail the technical implementation of the system and evaluate its argument extraction and logical validity accuracy. Our evaluation shows a 91.2% argument overlap with ground truth argument annotations and 87% validity accuracy. Finally, we conducted a small-scale pilot and discuss early qualitative results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Critical Inker, a writing assistance tool that combines a Socratic chatbot for questioning logical errors and visual feedback highlighting such errors to scaffold critical thinking and mitigate cognitive deskilling from LLM use. It describes the system's technical implementation for argument extraction and validity checking, reports evaluation results showing 91.2% argument overlap with ground-truth annotations and 87% validity accuracy, and presents a small-scale pilot study with qualitative results on user experience.
Significance. If the scaffolding claim holds, the work addresses a timely HCI concern about over-reliance on AI writing tools by offering concrete mechanisms for prompting user reflection. The reported technical accuracies indicate a functional backend for argument analysis that could serve as a foundation for future systems, though the absence of direct outcome measures limits immediate impact.
major comments (2)
- [Abstract] Abstract and evaluation description: The central claim that Socratic questioning and visual feedback scaffold critical thinking is not supported by evidence linking the feedback mechanisms to user outcomes. The 91.2% argument overlap and 87% validity accuracy validate only the extraction and checking modules against annotations; no pre/post measures of argument quality, revision depth, or critical-thinking rubric scores are reported to establish the causal scaffolding effect.
- [Pilot Study] Pilot study description: The small-scale pilot supplies only qualitative anecdotes without quantitative metrics (e.g., blinded ratings of critical reflection or controlled comparison of writing with vs. without the feedback), leaving the generalization of the scaffolding benefit untested beyond the technical accuracies.
minor comments (1)
- [Evaluation] Evaluation details such as test-set size, inter-annotator agreement, error analysis, and statistical tests are not provided, which would improve assessment of the reported 91.2% and 87% figures.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between technical validation and evidence of user-level scaffolding effects. We address each point below and will revise the manuscript to better align claims with the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: The central claim that Socratic questioning and visual feedback scaffold critical thinking is not supported by evidence linking the feedback mechanisms to user outcomes. The 91.2% argument overlap and 87% validity accuracy validate only the extraction and checking modules against annotations; no pre/post measures of argument quality, revision depth, or critical-thinking rubric scores are reported to establish the causal scaffolding effect.
Authors: We agree that the reported 91.2% argument overlap and 87% validity accuracy evaluate only the backend modules for argument extraction and logical validity checking. The manuscript positions Critical Inker as a system that implements Socratic questioning and visual feedback to scaffold reflection, supported by the technical feasibility of these components and qualitative observations from the pilot. No pre/post or controlled outcome measures of critical thinking are present. We will revise the abstract and evaluation summary to state that the work demonstrates a functional implementation with technical accuracies and preliminary qualitative user feedback, while explicitly noting the absence of direct causal evidence on critical-thinking outcomes. revision: yes
-
Referee: [Pilot Study] Pilot study description: The small-scale pilot supplies only qualitative anecdotes without quantitative metrics (e.g., blinded ratings of critical reflection or controlled comparison of writing with vs. without the feedback), leaving the generalization of the scaffolding benefit untested beyond the technical accuracies.
Authors: The manuscript already describes the pilot as small-scale and limited to qualitative results. We did not perform blinded ratings, pre/post assessments, or controlled comparisons, which would require a separate experimental design. We will expand the pilot study and limitations sections to clarify its exploratory purpose, report the number of participants and session details more precisely, and outline the need for future controlled studies to quantify effects on revision depth and critical reflection. revision: yes
- Quantitative pre/post measures or controlled comparisons demonstrating causal effects on critical thinking or argument quality, as these require new user studies outside the scope of the current system-description and pilot work.
Circularity Check
No circularity; evaluations use external ground truth and qualitative pilot
full rationale
The paper presents a system implementation for argument extraction, validity checking, Socratic chatbot, and visual feedback. It reports 91.2% argument overlap and 87% validity accuracy measured against separate ground-truth annotations on documents, plus qualitative observations from a small pilot study. No equations, parameter fitting, self-citations, or uniqueness theorems are used in any load-bearing derivation. The technical accuracies are independent benchmarks, and the scaffolding claim rests on descriptive system design plus pilot anecdotes rather than any reduction to fitted inputs or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Argument structures and logical validity can be reliably extracted and judged from natural-language writing drafts by current LLMs.
invented entities (1)
-
Critical Inker system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe present two methods: (1) A Socratic chatbot using questions to help them realize and fix logical errors in their writing and (2) Visual Feedback, which highlights logical errors in the text without dialog. ... 91.2% argument overlap ... 87% validity accuracy.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery from Law of Logic unclearThe system extracts the argument structure using a LLM pipeline ... Structure Extraction, Logical Evaluation, and Socratic Intervention.
Reference graph
Works this paper leans on
-
[1]
Writing is thinking.Nature Reviews Bioengineering3, 6 (2025), 431–431
2025. Writing is thinking.Nature Reviews Bioengineering3, 6 (2025), 431–431. doi:10.1038/s44222-025-00323-4
-
[2]
Dhruv Agarwal, Mor Naaman, and Aditya Vashistha. 2025. AI suggestions homogenize writing toward western styles and diminish cultural nuances. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–21
2025
-
[3]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Man- ning. 2015. A large annotated corpus for learning natural language inference. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics
2015
-
[4]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychol- ogy.Qualitative Research in Psychology3, 2 (1 2006), 77–101. doi:10.1191/ 1478088706qp063oa
2006
-
[5]
Virginia Braun and Victoria Clarke. 2019. Reflecting on reflexive thematic analysis. Qualitative Research in Sport Exercise and Health11, 4 (6 2019), 589–597. doi:10. 1080/2159676x.2019.1628806 Critical Inker: Scaffolding Critical Thinking in AI-Assisted Writing Through Socratic Questioning , ,
-
[6]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-computer Interaction5, CSCW1 (2021), 1–21
2021
-
[7]
Krzysztof Budzyń, Marcin Romańczyk, Diana Kitala, Paweł Kołodziej, Marek Bugajski, Hans O Adami, Johannes Blom, Marek Buszkiewicz, Natalie Halvorsen, Cesare Hassan, et al. 2025. Endoscopist deskilling risk after exposure to artificial intelligence in colonoscopy: a multicentre, observational study.The Lancet Gastroenterology & Hepatology10, 10 (2025), 896–903
2025
-
[8]
John M Carroll and Caroline Carrithers. 1984. Training wheels in a user interface. Commun. ACM27, 8 (1984), 800–806
1984
-
[9]
Michelene TH Chi, Miriam Bassok, Matthew W Lewis, Peter Reimann, and Robert Glaser. 1989. Self-explanations: How students study and use examples in learning to solve problems.Cognitive science13, 2 (1989), 145–182
1989
-
[10]
Michelene TH Chi, Nicholas De Leeuw, Mei-Hung Chiu, and Christian LaVancher
-
[11]
Eliciting self-explanations improves understanding.Cognitive science18, 3 (1994), 439–477
1994
-
[12]
Valdemar Danry, Pat Pataranutaporn, Yaoli Mao, and Pattie Maes. 2023. Don’t just tell me, ask me: Ai systems that intelligently frame explanations as questions improve human logical discernment accuracy over causal ai explanations. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–13
2023
-
[13]
Yizhou Fan, Luzhen Tang, Huixiao Le, Kejie Shen, Shufang Tan, Yueying Zhao, Yuan Shen, Xinyu Li, and Dragan Gašević. 2025. Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance.British Journal of Educational Technology56, 2 (2025), 489–530
2025
-
[14]
Radha Firaina and Dwi Sulisworo. 2023. Exploring the usage of ChatGPT in higher education: Frequency and impact on productivity.Buletin Edukasi Indonesia2, 01 (2023), 39–46
2023
-
[15]
Linda Flower and John R Hayes. 1981. A cognitive process theory of writing. College Composition & Communication32, 4 (1981), 365–387
1981
-
[16]
Fyfe and Bethany Rittle-Johnson
Emily R. Fyfe and Bethany Rittle-Johnson. 2015. Feedback both helps and hinders learning: The causal role of prior knowledge.Journal of Educational Psychology 108, 1 (6 2015), 82–97. doi:10.1037/edu0000053
-
[17]
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman
-
[18]
In Proceedings of the 2023 CHI conference on human factors in computing systems
Co-writing with opinionated language models affects users’ views. In Proceedings of the 2023 CHI conference on human factors in computing systems. 1–15
2023
- [19]
-
[20]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. 2025. Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task.arXiv preprint arXiv:2506.088724 (2025)
-
[21]
Nguyen-Thinh Le. 2019. How do technology-enhanced learning tools support critical thinking?. InFrontiers in Education, Vol. 4. Frontiers Media SA, 126
2019
-
[22]
Mina Lee, Percy Liang, and Qian Yang. 2022. Coauthor: Designing a human- ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI conference on human factors in computing systems. 1–19
2022
- [23]
-
[24]
Roxana Moreno. 2004. Decreasing Cognitive Load for Novice Students: Effects of Explanatory versus Corrective Feedback in Discovery-Based Multimedia.Instruc- tional Science32, 1-2 (1 2004), 99–113. doi:10.1023/b:truc.0000021811.66966.1d
-
[25]
Seyed Parsa Neshaei, Antonia Tolzin, Yvonne Berkle, Miriam Leuchter, Jan Marco Leimeister, Andreas Janson, and Thiemo Wambsganss. 2025. Leveraging Learner Errors in Digital Argumentation Learning: How ALure Helps Students Learn from their Mistakes and Write Better Arguments.Proc. ACM Hum.-Comput. Interact.9, 2, Article CSCW125 (May 2025), 32 pages. doi:10...
-
[26]
Jakob Nielsen. 2006. Progressive disclosure.Nielsen Norman Group1 (2006)
2006
-
[27]
Richard Paul and Linda Elder. 2008. Critical thinking: The art of Socratic ques- tioning.Journal of developmental education31, 3 (2008), 34–35
2008
-
[28]
Roy D Pea and D Midian Kurland. 1987. Cognitive technologies for writing. Review of research in education14 (1987), 277–326
1987
-
[29]
Colin Porlezza. 2019. Accuracy in journalism.Oxford Research Encyclopedia of Communication(2019)
2019
-
[30]
Anku Rani, Valdemar Danry, Paul Pu Liang, Andrew B Lippman, and Pattie Maes
- [31]
-
[32]
Kirk B Redwine. 2003. The importance of the police report.Criminal Justice Institute School of Law Enforcement Supervision, Session XXII. Retrieved from http://www. cji. edu/site/assets/files/1921/importance_of_police_reports. pdf(last accessed July 2014)(2003)
2003
-
[33]
Ramon Ruiz-Dolz and John Lawrence. 2023. Detecting argumentative fallacies in the wild: Problems and limitations of large language models. InProceedings of the 10th Workshop on Argument Mining. Association for Computational Linguistics
2023
-
[34]
Frank Spillers. 2010. Progressive disclosure
2010
-
[35]
Christian Stab and Iryna Gurevych. 2017. Parsing Argumentation Structures in Persuasive Essays.Comput. Linguist.43, 3 (sep 2017), 619–659. doi:10.1162/ COLI_a_00295
2017
-
[36]
Christian Stab and Iryna Gurevych. 2017. Recognizing insufficiently supported arguments in argumentative essays. InProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. 980–990
2017
-
[37]
John Sweller. 1988. Cognitive load during problem solving: Effects on learning. Cognitive science12, 2 (1988), 257–285
1988
-
[38]
1987.An Introduction to Legal Reasoning, Writing, and Research Techniques; and Trial Preparation and Appellate Advocacy
Peter N Swisher. 1987.An Introduction to Legal Reasoning, Writing, and Research Techniques; and Trial Preparation and Appellate Advocacy
1987
-
[39]
Lev Tankelevitch, Viktor Kewenig, Auste Simkute, Ava Elizabeth Scott, Advait Sarkar, Abigail Sellen, and Sean Rintel. 2024. The metacognitive demands and opportunities of generative AI. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–24
2024
-
[40]
Thiemo Wambsganss, Andreas Janson, Matthias Söllner, Ken Koedinger, and Jan Marco Leimeister. 2024. Improving Students’ Argumentation Skills Using Dynamic Machine-Learning–Based Modeling.Information Systems Research36, 1 (6 2024), 474–507. doi:10.1287/isre.2021.0615
-
[41]
Florian Weber, Thiemo Wambsganss, Seyed Parsa Neshaei, and Matthias Soellner
-
[42]
LegalWriter: An Intelligent Writing Support System for Structured and Persuasive Legal Case Writing for Novice Law Students. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA) (CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 1052, 23 pages. doi:10.1145/3613904.3642743
-
[43]
Linjin Xi, Yi Zhang, and Qiyun Wang. 2025. Investigating the effects of an LLM- based Socratic conversational agent on students’ academic performance and reflective thinking in higher education.Computers & Education(2025), 105494
2025
-
[44]
Ann Yuan, Andy Coenen, Emily Reif, and Daphne Ippolito. 2022. Wordcraft: story writing with large language models. InProceedings of the 27th International Conference on Intelligent User Interfaces. 841–852
2022
-
[45]
Chao Zhang, Kexin Ju, Peter Bidoshi, Yu-Chun Grace Yen, and Jeffrey M Rzes- zotarski. 2025. Friction: Deciphering Writing Feedback into Writing Revisions through LLM-Assisted Reflection. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–27
2025
-
[46]
Zheng Zhang, Jie Gao, Ranjodh Singh Dhaliwal, and Toby Jia-Jun Li. 2023. Visar: A human-ai argumentative writing assistant with visual programming and rapid draft prototyping. InProceedings of the 36th annual ACM symposium on user interface software and technology. 1–30. A Prompts To ensure reproducibility, we provide the exact system prompts used for the...
2023
-
[47]
Extract every distinct argumentative statement ( reasons , premises , evidence ) as separate atomic quotes
-
[48]
Map which reasons support which claims
-
[49]
Distinguish direct support ( statements that directly support the main claim ) from indirect support ( statements that support other , , Philipp Hugenroth, Valdemar Danry, and Pattie Maes supporting statements )
-
[50]
Identify joined reasons ( work ONLY together ) vs independent reasons
-
[51]
content
Continue tracing support chains until reaching axioms ( unsupported base claims ) JSON Format : { claim : { " content ": " author's core position in your words " , " claim_quote ": " exact quote of the main thesis " , " s up po rt _r ela ti on s ": { " quotes ": { "1": " exact quote atomic reason in this case for claim_quote " , "2": " exact quote atomic ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.