Recognition: 2 theorem links
· Lean TheoremInfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models
Pith reviewed 2026-05-10 17:19 UTC · model grok-4.3
The pith
Disaggregating LoRA execution from base model inference enables higher request throughput under strict latency constraints in multi-LoRA LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decoupling LoRA adapter execution from base-model inference, InfiniLoRA uses a shared LoRA Server equipped with parallelism-aware execution, SLO-driven provisioning, and optimizations including GPU-initiated communication and specialized kernels to achieve an average 3.05 times increase in serviceable request rate under strict latency SLOs and raise the share of adapters meeting the SLO by 54 percent.
What carries the argument
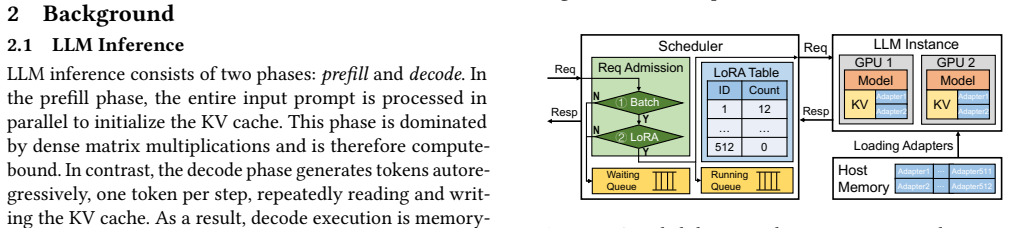
A shared LoRA Server that performs adapter computations independently from the base model, managed with awareness of parallel execution and hardware-specific optimizations to reduce data transfer costs.
If this is right
- The system can handle a higher volume of requests while respecting latency service level objectives.
- A greater percentage of LoRA adapters become usable without breaching performance guarantees.
- Memory usage becomes more efficient for models with high adapter overhead such as those based on mixture of experts.
- Critical path optimizations keep added latency from separation low enough to yield net improvements.
Where Pith is reading between the lines
- The separation technique could extend to other fine-tuning methods beyond LoRA in inference serving.
- Pooling adapter resources in this way might lower the overall hardware requirements for providers offering many customized models.
- Testing the system with non-MoE models would clarify how much the gains depend on the high memory cost of expert-based architectures.
- Further work could explore dynamic migration of adapters between servers to balance load in real time.
Load-bearing premise
The communication and coordination costs introduced by running LoRA on a separate server stay small compared to the benefits from reduced memory contention and better parallelism.
What would settle it
Measuring request throughput on a cluster with slower interconnects between the base model servers and the LoRA server and finding that the gains fall below the reported levels or become negative.
Figures
















read the original abstract
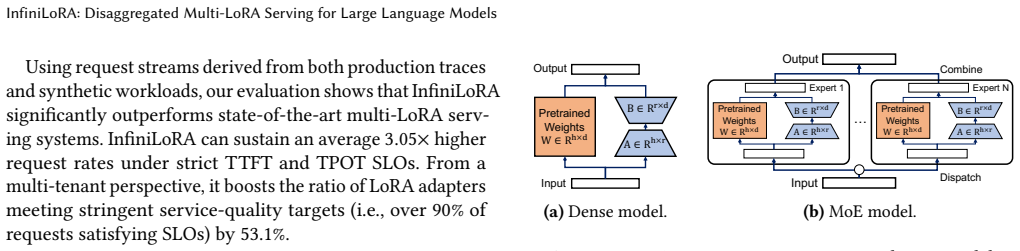
LoRA enables efficient customization of LLMs and is widely used in multi-tenant and multi-task serving. However, emerging model architectures such as MoE significantly increase LoRA memory cost, making existing coupled LoRA serving designs poorly scalable and prone to tail-latency inflation. We present InfiniLoRA, a disaggregated LoRA serving system that decouples LoRA execution from base-model inference. InfiniLoRA introduces a shared LoRA Server with parallelism-aware execution, SLO-driven provisioning, and critical-path optimizations, including GPU-initiated communication and hardware-specialized LoRA kernels. Experiments show that InfiniLoRA can achieve an average $3.05\times$ increase in serviceable request rate under strict latency SLOs, and improve the percentage of LoRA adapters satisfying the SLO requirement by 54.0\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents InfiniLoRA, a disaggregated multi-LoRA serving system for LLMs that decouples LoRA adapter execution from base-model inference to address high memory costs in MoE architectures. It introduces a shared LoRA Server with parallelism-aware execution, SLO-driven provisioning, GPU-initiated communication, and specialized kernels. The central claim, supported by experiments, is an average 3.05× increase in serviceable request rate under strict latency SLOs together with a 54% improvement in the fraction of adapters meeting those SLOs.
Significance. If the measured gains prove robust, the disaggregation approach could meaningfully advance scalable multi-tenant LLM serving by improving memory efficiency and latency compliance for memory-intensive MoE models without proportional hardware increases. The work supplies a concrete systems design and empirical quantification that could inform future inference-stack research.
major comments (2)
- [§4] §4 (Evaluation): The headline 3.05× request-rate and +54% SLO-compliance claims are presented without a latency-component breakdown or explicit measurement showing that GPU-initiated communication and cross-server data movement remain negligible relative to the memory savings; this is load-bearing because the architecture's premise is that disaggregation overheads do not inflate tail latencies under the strict SLOs.
- [§4.2, §5] §4.2 and §5: No ablation or sensitivity results are reported for different interconnect bandwidths, MoE expert counts, or request-trace characteristics, leaving open whether the reported gains generalize beyond the specific high-bandwidth hardware and workloads tested.
minor comments (2)
- [Abstract, §4] The abstract and §4 omit the precise numerical SLO thresholds, model sizes, and baseline system versions used, which would aid immediate interpretation of the quantitative results.
- [§3.3] Notation for the SLO-driven provisioning algorithm in §3.3 could be clarified with a small pseudocode listing or explicit variable definitions to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The feedback highlights important aspects of our evaluation that we will strengthen in the revision. We address each major comment below and commit to incorporating the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The headline 3.05× request-rate and +54% SLO-compliance claims are presented without a latency-component breakdown or explicit measurement showing that GPU-initiated communication and cross-server data movement remain negligible relative to the memory savings; this is load-bearing because the architecture's premise is that disaggregation overheads do not inflate tail latencies under the strict SLOs.
Authors: We agree that an explicit breakdown of latency components would strengthen the central claims. While the manuscript describes the GPU-initiated communication and specialized kernels as critical-path optimizations intended to keep disaggregation overheads low, we did not provide a quantitative decomposition isolating communication versus computation times under load. In the revised version we will add a new subsection (or expanded figure) in §4 that reports per-component latency measurements (base-model inference, LoRA execution, GPU-initiated transfers, and cross-server movement) across the evaluated request rates. These measurements will explicitly show that the added communication remains a small fraction of the SLO budget and does not drive the observed tail-latency improvements. revision: yes
-
Referee: [§4.2, §5] §4.2 and §5: No ablation or sensitivity results are reported for different interconnect bandwidths, MoE expert counts, or request-trace characteristics, leaving open whether the reported gains generalize beyond the specific high-bandwidth hardware and workloads tested.
Authors: We acknowledge that the current evaluation is performed on a single high-bandwidth cluster and a limited set of MoE configurations and traces. To address generalizability, the revised manuscript will include additional sensitivity experiments. We will report results for (1) reduced interconnect bandwidth (e.g., PCIe-only versus NVLink), (2) varying numbers of MoE experts, and (3) alternative request-trace distributions. These results will be placed in an expanded §4.2 with corresponding discussion in §5, allowing readers to assess how the gains scale with hardware and workload parameters. revision: yes
Circularity Check
No significant circularity; empirical systems evaluation with no derivation chain
full rationale
The paper presents a disaggregated LoRA serving architecture for MoE models, supported by experimental measurements of request-rate gains and SLO compliance. No mathematical derivations, fitted parameters, or equations are described that could reduce to self-definition or fitted inputs. Claims rest on external benchmarks (measured throughput and latency under specific workloads) rather than internal construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the abstract or context to justify core results. This is a standard empirical systems paper whose validity is testable via replication on the reported hardware and traces.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
InfiniLoRA introduces a shared LoRA Server with parallelism-aware execution, SLO-driven provisioning, and critical-path optimizations, including GPU-initiated communication and hardware-specialized LoRA kernels.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate provisioning based on ... Immediate Admissibility Rate (IAR) ... Poissonized model ... dynamic programming
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anonymous. 2026. Understanding LoRA As Knowledge Memory: An Empirical Analysis.https://openreview.net/forum?id=i1Mi2R1TsU
2026
-
[2]
Chieh-Yun Chen, Zhonghao Wang, Qi Chen, Zhifan Ye, Min Shi, Yue Zhao, Yinan Zhao, Hui Qu, Wei-An Lin, Yiru Shen, Ajinkya Kale, Irfan Essa, and Humphrey Shi. 2025. MapReduce LoRA: Advancing the Pareto Front in Multi-Preference Optimization for Generative Models. arXiv:2511.20629 [cs.CV]https://arxiv.org/abs/2511.20629
- [3]
- [4]
-
[5]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer
-
[7]
InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23)
QLORA: efficient finetuning of quantized LLMs. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 441, 28 pages
-
[8]
Kuntai Du, Bowen Wang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Yao, Xiaoxuan Liu, Yifan Qiao, Ion Stoica, and Junchen Jiang. 2025. PrefillOnly: An Inference Engine for Prefill-only Workloads in Large Language Model Applications. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, S...
-
[9]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Effi- cient Sparsity. arXiv:2101.03961 [cs.LG]https://arxiv.org/abs/2101. 03961
work page internal anchor Pith review arXiv 2022
-
[10]
Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. 2025. How to Train Long-Context Language Models (Effectively). InACL
2025
-
[11]
Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, Tao Xie, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. 2024. MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool. arXiv:2406.17565 [cs.DC] https://arxiv.org/abs/2406.17565
-
[12]
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Chenxi Wang, Jiang Xu, Shuang Chen, Hao Feng, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. 2025. ShuffleInfer: Disaggregate LLM Inference for Mixed Downstream Workloads.ACM Trans. Archit. Code Optim.22, 2, Article 77 (July 2025), 24 pages. doi:10.1145/3732941
-
[13]
Chenghao Hu, Yufei Kang, and Baochun Li. 2025. Communication- Efficient MoE Fine-Tuning with Locality-Aware Expert Placement. In2025 IEEE 45th International Conference on Distributed Computing Systems (ICDCS). 166–176. doi:10.1109/ICDCS63083.2025.00025
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low- Rank Adaptation of Large Language Models. InInternational Confer- ence on Learning Representations.https://openreview.net/forum?id= nZeVKeeFYf9
2022
-
[15]
Nikoleta Iliakopoulou, Jovan Stojkovic, Chloe Alverti, Tianyin Xu, Hubertus Franke, and Josep Torrellas. 2025. Chameleon: Adaptive Caching and Scheduling for Many-Adapter LLM Inference Environ- ments. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Machinery, New York, NY, USA, 217–231...
-
[16]
Shashwat Jaiswal, Shrikara Arun, Anjaly Parayil, Ankur Mallick, Spyros Mastorakis, Alind Khare, Chloi Alverti, Renee St Amant, Chetan Bansal, Victor Rühle, and Josep Torrellas. 2025. Serving Het- erogeneous LoRA Adapters in Distributed LLM Inference Systems. arXiv:2511.22880 [cs.DC]https://arxiv.org/abs/2511.22880
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Men- sch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Tev...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Rui Kong, Qiyang Li, Xinyu Fang, Qingtian Feng, Qingfeng He, Yazhu Dong, Weijun Wang, Yuanchun Li, Linghe Kong, and Yunxin Liu
-
[19]
LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design. arXiv:2405.17741 [cs.AI]https: //arxiv.org/abs/2405.17741
-
[20]
Xiaoyu Kong, Jiancan Wu, An Zhang, Leheng Sheng, Hui Lin, Xiang Wang, and Xiangnan He. 2024. Customizing language models with instance-wise LoRA for sequential recommendation. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Article 3593...
2024
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[22]
InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles. 14 InfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models
- [23]
-
[24]
Suyi Li, Yifan Qiao, Jiacheng Ma, Shan Yu, Haoran Ma, Ziming Liu, Hang Ren, Wenguang Chen, Yongwei Wu, Weimin Zheng, and Kang Chen. 2025. Toppings: Modular and Extensible Serverless Function Delivery at High Speed. In2025 USENIX Annual Technical Conference (USENIX ATC 25). USENIX Association, Seattle, WA.https://www. usenix.org/conference/atc25/presentati...
2025
-
[25]
Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guo- hong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, Rui Kong, Yile Wang, Hanfei Geng, Jian Luan, Xuefeng Jin, Zilong Ye, Guan- jing Xiong, Fan Zhang, Xiang Li, Mengwei Xu, Zhijun Li, Peng Li, Yang Liu, Ya-Qin Zhang, and Yunxin Liu. 2024. Personal LLM Agents: Insights and Survey about the...
-
[26]
2022.Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async
Pak Markthub, Jim Dinan, Sreeram Potluri, and Seth How- ell. 2022.Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect Async. NVIDIA.https://developer.nvidia.com/blog/improving-network- performance-of-hpc-systems-using-nvidia-magnum-io-nvshmem- and-gpudirect-async/
2022
-
[27]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL]https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2025. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture (Buenos Aires, Argentina)(ISCA ’24). IEEE Press, 118–132. doi:10. 1109/ISCA59077.2024.00019
-
[29]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Moon- cake: Trading More Storage for Less Computation — A KVCache- centric Architecture for Serving LLM Chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170.https://w...
2025
-
[30]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed-MoE: Advancing Mixture-of- Experts Inference and Training to Power Next-Generation AI Scale. arXiv:2201.05596 [cs.LG]https://arxiv.org/abs/2201.05596
-
[31]
John Schulman and Thinking Machines Lab. 2025. LoRA Without Regret.Thinking Machines Lab: Connectionism(2025). doi:10.64434/ tml.20250929https://thinkingmachines.ai/blog/lora/
2025
-
[32]
Sheng Shen, Le Hou, Yanqi Zhou, Nan Du, Shayne Longpre, Jason Wei, Hyung Won Chung, Barret Zoph, William Fedus, Xinyun Chen, Tu Vu, Yuexin Wu, Wuyang Chen, Albert Webson, Yunxuan Li, Vin- cent Zhao, Hongkun Yu, Kurt Keutzer, Trevor Darrell, and Denny Zhou. 2023. Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models. a...
-
[33]
2025.EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices
Zheyu Shen, Yexiao He, Ziyao Wang, Yuning Zhang, Guoheng Sun, Wanghao Ye, and Ang Li. 2025.EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices. Association for Computing Machinery, New York, NY, USA, 138–153.https://doi.org/10.1145/ 3711875.3729141
-
[34]
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, and Ion Stoica. 2023. S-LoRA: Serving Thousands of Concurrent LoRA Adapters.arXiv preprint arXiv:2311.03285(2023)
- [35]
-
[36]
Smith, Luke Zettlemoyer, Wen tau Yih, and Mike Lewis
Weijia Shi, Sewon Min, Maria Lomeli, Chunting Zhou, Margaret Li, Xi Victoria Lin, Noah A. Smith, Luke Zettlemoyer, Wen tau Yih, and Mike Lewis. 2024. In-Context Pretraining: Language Modeling Beyond Document Boundaries. InThe Twelfth International Confer- ence on Learning Representations.https://openreview.net/forum?id= LXVswInHOo
2024
-
[37]
Xiao Shi, Jiangsu Du, Zhiguang Chen, and Yutong Lu. 2025. AuLoRA: Fine-Grained Loading and Computation Orchestration for Efficient LoRA LLM Serving. In2025 IEEE 43rd International Conference on Computer Design (ICCD). 277–284. doi:10.1109/ICCD65941.2025.00046
-
[38]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
The Mosaic Research Team. 2024. Introducing DBRX: A New State- of-the-Art Open LLM.https://www.databricks.com/blog/introducing- dbrx-new-state-art-open-llm. Accessed: 2026-01-21
2024
-
[40]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, Xin Wang, Qiang Wang, Amelie Chi Zhou, and Xiaowen Chu. 2025. BurstGPT: A Real-World Workload Dataset to Optimize LLM Serving Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). ACM, Tor...
-
[41]
Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He
-
[42]
arXiv preprint arXiv:2502.00592 , year=
M+: Extending MemoryLLM with Scalable Long-Term Memory. arXiv:2502.00592 [cs.CL]https://arxiv.org/abs/2502.00592
-
[43]
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. 2025. LoRA-Pro: Are Low-Rank Adapters Properly Optimized?. InThe Thir- teenth International Conference on Learning Representations (ICLR)
2025
-
[44]
Bingyang Wu, Ruidong Zhu, Zili Zhang, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. dLoRA: Dynamically Orchestrating Requests and Adapters for LoRA LLM Serving. In18th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 24). USENIX Associa- tion, Santa Clara, CA, 911–927.https://www.usenix.org/conference/ osdi24/presentation/wu-bingyang
2024
-
[45]
Shuaipeng Wu, Yanying Lin, Shijie Peng, Wenyan Chen, Chong Ma, Min Shen, Le Chen, Chengzhong Xu, and Kejiang Ye. 2025. Rock: Serving Multimodal Models in Cloud with Heterogeneous-Aware Resource Orchestration for Thousands of LoRA Adapters. In2025 IEEE International Conference on Cluster Computing (CLUSTER). 1–13. doi:10.1109/CLUSTER59342.2025.11186463
-
[46]
Lingnan Xia and Hua Ma. 2024. Enhancing LoRA Model Serving Capacity via Adaptive Operator Scheduling for Multi-Tenancy on GPU.IEEE Access12 (2024), 160441–160449. doi:10.1109/ACCESS. 2024.3483250
-
[47]
Yifei Xia, Fangcheng Fu, Wentao Zhang, Jiawei Jiang, and Bin Cui
-
[48]
InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada) (NIPS ’24)
Efficient multi-task LLM quantization and serving for multiple LoRA adapters. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada) (NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Article 2034, 29 pages
2034
- [49]
- [50]
- [52]
-
[53]
Tianyu Zhang, Peng Zhang, Yusong Gao, and Yun Zhang. 2025. To- gether with SGLang: Best Practices for Serving DeepSeek-R1 on H20- 96G.https://lmsys.org/blog/2025-09-26-sglang-ant-group/. LMSYS Org Blog
2025
-
[54]
You Zhang, Jin Wang, Liang-Chih Yu, Dan Xu, and Xuejie Zhang
-
[55]
Proceedings of the AAAI Conference on Artificial Intelligence38, 17 (Mar
Personalized LoRA for Human-Centered Text Understanding. Proceedings of the AAAI Conference on Artificial Intelligence38, 17 (Mar. 2024), 19588–19596. doi:10.1609/aaai.v38i17.29931
-
[56]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serv- ing. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(Santa Clara, CA, USA)(OSDI’24). USENIX Association, USA, Art...
2024
-
[57]
Changhai Zhou, Yuhua Zhou, Shiyang Zhang, Yibin Wang, and Zekai Liu. 2025. Dynamic Operator Optimization for Efficient Multi-Tenant LoRA Model Serving.Proceedings of the AAAI Conference on Artificial Intelligence39, 21 (Apr. 2025), 22910–22918. doi:10.1609/aaai.v39i21. 34453
-
[58]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. 2025. MegaScale-Infer: Efficient Mixture-of-Experts Model Serving with Dis- aggregated Expert Parallelism...
-
[59]
Ruidong Zhu, Ziyue Jiang, Zhi Zhang, Xin Liu, Xuanzhe Liu, and Xin Jin. 2025. Cannikin: No Lagger of SLO in Concurrent Multiple LoRA LLM Serving.IEEE Transactions on Parallel and Distributed Systems 36, 9 (2025), 1972–1984. doi:10.1109/TPDS.2025.3590014 16 InfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models A Appendix A.1 Additional Sca...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.