Recognition: 2 theorem links
· Lean TheoremVersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis
Pith reviewed 2026-05-10 18:55 UTC · model grok-4.3
The pith
A trait-routing attention module with mixture-of-experts and an automated preference pipeline together unify garment generation and virtual dressing inside one diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VersaVogue jointly supports garment generation and virtual dressing by replacing static feature concatenation with a trait-routing attention module that uses mixture-of-experts routing to send each condition to the most compatible expert and generative layer, thereby disentangling texture, shape, and color. An automated multi-perspective preference optimization pipeline then assembles reliable preference pairs from fidelity, alignment, and perceptual evaluators and applies direct preference optimization, removing the need for human labels or task-specific reward models.
What carries the argument
The trait-routing attention (TA) module, a mixture-of-experts mechanism that dynamically assigns condition features to the most compatible experts and generative layers for disentangled attribute injection.
If this is right
- One model replaces two separate systems for the design and showcase stages of the fashion lifecycle.
- Dynamic expert routing reduces attribute entanglement that arises from simple concatenation of heterogeneous conditions.
- Preference pairs built from multiple automated evaluators allow direct preference optimization without human annotation or custom reward models.
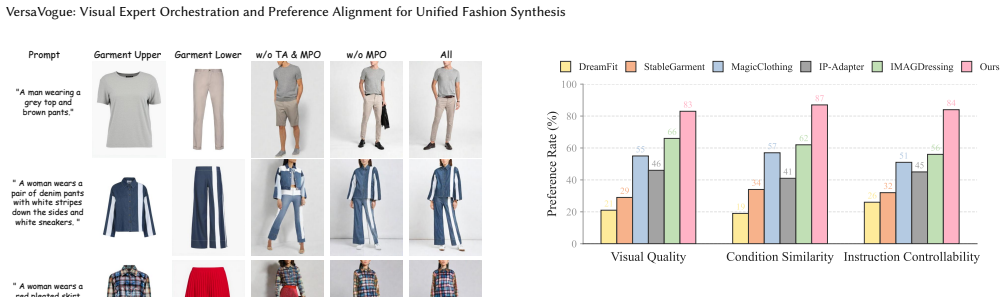
- Benchmarks show consistent gains in visual fidelity, semantic consistency, and fine-grained controllability for both garment generation and virtual dressing.
- The framework handles multi-source conditions such as text, reference images, and masks within a single generative process.
Where Pith is reading between the lines
- The same routing-plus-preference pattern could be tested on other multi-condition image tasks such as interior layout or product visualization.
- If the MPO pipeline generalizes, it offers a template for reward-free alignment in additional diffusion domains.
- Real-time fashion applications could combine the unified model with live user inputs to shorten the path from sketch to virtual model.
Load-bearing premise
The automated evaluators of content fidelity, textual alignment, and perceptual quality produce unbiased preference pairs that correctly reflect human preference.
What would settle it
A large-scale human preference study on multi-condition fashion prompts in which raters consistently choose outputs from prior separate models over VersaVogue outputs would falsify the claimed gains in fidelity and controllability.
Figures












read the original abstract
Diffusion models have driven remarkable advancements in fashion image generation, yet prior works usually treat garment generation and virtual dressing as separate problems, limiting their flexibility in real-world fashion workflows. Moreover, fashion image synthesis under multi-source heterogeneous conditions remains challenging, as existing methods typically rely on simple feature concatenation or static layer-wise injection, which often causes attribute entanglement and semantic interference. To address these issues, we propose VersaVogue, a unified framework for multi-condition controllable fashion synthesis that jointly supports garment generation and virtual dressing, corresponding to the design and showcase stages of the fashion lifecycle. Specifically, we introduce a trait-routing attention (TA) module that leverages a mixture-of-experts mechanism to dynamically route condition features to the most compatible experts and generative layers, enabling disentangled injection of visual attributes such as texture, shape, and color. To further improve realism and controllability, we develop an automated multi-perspective preference optimization (MPO) pipeline that constructs preference data without human annotation or task-specific reward models. By combining evaluators of content fidelity, textual alignment, and perceptual quality, MPO identifies reliable preference pairs, which are then used to optimize the model via direct preference optimization (DPO). Extensive experiments on both garment generation and virtual dressing benchmarks demonstrate that VersaVogue consistently outperforms existing methods in visual fidelity, semantic consistency, and fine-grained controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VersaVogue, a unified framework for multi-condition controllable fashion synthesis that jointly addresses garment generation and virtual dressing. It proposes a trait-routing attention (TA) module leveraging mixture-of-experts to dynamically route condition features for disentangled injection of attributes such as texture, shape, and color. An automated multi-perspective preference optimization (MPO) pipeline constructs preference pairs using three evaluators (content fidelity, textual alignment, perceptual quality) without human annotation, which are then used to optimize the model via direct preference optimization (DPO). The central claim is that VersaVogue consistently outperforms prior methods in visual fidelity, semantic consistency, and fine-grained controllability on garment generation and virtual dressing benchmarks.
Significance. If the results hold, the work could advance unified fashion synthesis by reducing task fragmentation and attribute entanglement through dynamic routing, while offering a scalable alternative to human-annotated preference data via automated evaluators. The MPO approach, if validated, would be particularly impactful for alignment in generative vision models.
major comments (2)
- [§3.3] §3.3: The MPO pipeline constructs preference pairs exclusively from three automated evaluators (content fidelity, textual alignment, perceptual quality) and applies them directly in DPO. No correlation analysis, human study, or inter-evaluator agreement metrics are reported to establish that these rankings align with human perception of fashion attributes (e.g., texture fidelity or fine-grained controllability). This is load-bearing for the claimed gains in semantic consistency and visual fidelity, as misalignment would cause DPO to optimize toward evaluator artifacts rather than the intended objectives.
- [Results section] Results section: The manuscript asserts extensive experiments showing consistent outperformance, yet provides no ablation tables isolating the TA module versus the MPO pipeline, no quantitative effect sizes or statistical significance tests on benchmark metrics, and no error analysis or failure-case breakdowns. Without these, the strongest claim of superiority across visual fidelity, semantic consistency, and controllability cannot be rigorously evaluated.
minor comments (1)
- [§3.2] The notation for the trait-routing attention module could be clarified with an explicit equation for the expert routing weights and layer selection to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. The comments highlight important aspects of validation for the MPO pipeline and the rigor of our experimental analysis. We address each point below and commit to revisions that strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [§3.3] §3.3: The MPO pipeline constructs preference pairs exclusively from three automated evaluators (content fidelity, textual alignment, perceptual quality) and applies them directly in DPO. No correlation analysis, human study, or inter-evaluator agreement metrics are reported to establish that these rankings align with human perception of fashion attributes (e.g., texture fidelity or fine-grained controllability). This is load-bearing for the claimed gains in semantic consistency and visual fidelity, as misalignment would cause DPO to optimize toward evaluator artifacts rather than the intended objectives.
Authors: We agree that explicit validation of the automated evaluators against human perception is necessary to support the claims. The current manuscript relies on established metrics for each evaluator (e.g., CLIP-based textual alignment, perceptual quality via LPIPS/FID variants, and content fidelity via reconstruction metrics), but does not report inter-evaluator agreement or human correlation. In the revision, we will add: (1) pairwise Pearson correlations and Cohen's kappa between the three evaluators on a held-out set of 500 samples; (2) a small-scale human study (20 participants, 200 image pairs) rating preference alignment on texture fidelity, shape controllability, and overall quality, with results reported in a new subsection of §3.3. This will quantify how well the MPO rankings match human judgments and mitigate concerns about evaluator artifacts. revision: yes
-
Referee: [Results section] Results section: The manuscript asserts extensive experiments showing consistent outperformance, yet provides no ablation tables isolating the TA module versus the MPO pipeline, no quantitative effect sizes or statistical significance tests on benchmark metrics, and no error analysis or failure-case breakdowns. Without these, the strongest claim of superiority across visual fidelity, semantic consistency, and controllability cannot be rigorously evaluated.
Authors: The referee correctly notes that the current results section lacks component-wise ablations, statistical tests, and failure analysis. While the manuscript includes overall benchmark comparisons, it does not isolate the Trait-Routing Attention (TA) module from the MPO pipeline or provide effect sizes. We will revise the Results section to include: (1) ablation tables showing performance with/without TA and with/without MPO on both garment generation and virtual dressing tasks; (2) statistical significance via paired t-tests and Cohen's d effect sizes on primary metrics (FID, CLIP score, controllability accuracy); (3) a dedicated error analysis subsection with quantitative breakdown of failure modes (e.g., by attribute type: texture vs. shape) and qualitative examples of remaining limitations. These additions will allow rigorous evaluation of each component's contribution. revision: yes
Circularity Check
No significant circularity detected in derivation or claims.
full rationale
The paper's core contributions—the trait-routing attention module using mixture-of-experts for condition injection and the MPO pipeline that constructs preference pairs via three automated evaluators before applying standard DPO—are presented as independent methodological innovations. The outperformance claims rest on benchmark experiments rather than any reduction of results to fitted parameters, self-definitions, or self-citation chains by construction. No equations or steps equate the final performance metrics to the input evaluators or routing logic; the MPO reliability is an empirical assumption validated externally via experiments, not a tautology. This keeps the derivation self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models can be conditioned on heterogeneous visual and textual inputs
- ad hoc to paper Mixture-of-experts routing can achieve disentangled attribute injection
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce a trait-routing attention (TA) module that leverages a mixture-of-experts mechanism to dynamically route condition features...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearautomated multi-perspective preference optimization (MPO) pipeline that constructs preference data without human annotation
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika39, 3/4 (1952), 324–345
1952
-
[3]
Weifeng Chen, Tao Gu, Yuhao Xu, and Arlene Chen. 2024. Magic clothing: Controllable garment-driven image synthesis. InProceedings of the 32nd ACM International Conference on Multimedia. 6939–6948
2024
-
[4]
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao
-
[5]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Anydoor: Zero-shot object-level image customization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6593–6602
-
[6]
Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. 2021. VITON- HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR)
2021
-
[7]
Zheng Chong, Yanwei Lei, Shiyue Zhang, Zhuandi He, Zhen Wang, Xujie Zhang, Xiao Dong, Yiling Wu, Dongmei Jiang, and Xiaodan Liang. 2025. FastFit: Ac- celerating Multi-Reference Virtual Try-On via Cacheable Diffusion Models. arXiv:2508.20586 [cs.CV] https://arxiv.org/abs/2508.20586
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[9]
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, and Junshi Huang
- [10]
-
[11]
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. 2024. Implicit style-content separation using b-lora. InEuropean Conference on Computer Vision. Springer, 181–198
2024
-
[12]
Masato Fujitake. 2024. Rl-logo: Deep reinforcement learning localization for logo recognition. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2830–2834
2024
-
[13]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
2017
-
[14]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
-
[15]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [16]
-
[17]
Jeongho Kim, Guojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. 2024. Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8176–8185
2024
-
[18]
Dongxu Li, Junnan Li, and Steven Hoi. 2023. Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing.Advances in Neural Information Processing Systems36 (2023), 30146–30166
2023
-
[19]
Xinghui Li, Qichao Sun, Pengze Zhang, Fulong Ye, Zhichao Liao, Wanquan Feng, Songtao Zhao, and Qian He. 2025. Anydressing: Customizable multi-garment virtual dressing via latent diffusion models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 23723–23733
2025
-
[20]
Ente Lin, Xujie Zhang, Fuwei Zhao, Yuxuan Luo, Xin Dong, Long Zeng, and Xiao- dan Liang. 2025. Dreamfit: Garment-centric human generation via a lightweight anything-dressing encoder. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 5218–5226
2025
-
[21]
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. 2023. Latent con- sistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378(2023)
work page internal anchor Pith review arXiv 2023
-
[22]
Davide Morelli, Matteo Fincato, Marcella Cornia, Federico Landi, Fabio Cesari, and Rita Cucchiara. 2022. Dress Code: High-Resolution Multi-Category Virtual Try-On. InProceedings of the European Conference on Computer Vision
2022
-
[23]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. 2024. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 4296–4304
2024
-
[24]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[25]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. Sdxl: Improving latent diffu- sion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[27]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[28]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[29]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[30]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Fei Shen, Xin Jiang, Xin He, Hu Ye, Cong Wang, Xiaoyu Du, Zechao Li, and Jinhui Tang. 2025. Imagdressing-v1: Customizable virtual dressing. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 6795–6804
2025
- [32]
-
[33]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2022. Denoising Diffusion Implicit Models. arXiv:2010.02502 [cs.LG] https://arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik
-
[35]
InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Diffusion model alignment using direct preference optimization. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8228–8238
- [36]
- [37]
- [38]
-
[39]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612
2004
-
[40]
Yuhao Xu, Tao Gu, Weifeng Chen, and Arlene Chen. 2025. Ootdiffusion: Outfit- ting fusion based latent diffusion for controllable virtual try-on. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8996–9004
2025
-
[41]
Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuofan Zong, Yu Liu, and Ping Luo. 2023. Raphael: Text-to-image generation via large mixture of diffusion paths.Advances in Neural Information Processing Systems36 (2023), 41693–41706
2023
-
[42]
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. 2024. Using human feedback to fine-tune diffusion models without any reward model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8941–8951
2024
-
[43]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721(2023)
work page internal anchor Pith review arXiv 2023
-
[44]
Mingzhe Yu, Yunshan Ma, Lei Wu, Changshuo Wang, Xue Li, and Lei Meng
-
[45]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
FashionDPO: Fine-tune Fashion Outfit Generation Model using Direct Preference Optimization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 212–222
- [46]
-
[47]
Cheng Zhang, Dong Gong, Jiumei He, Yu Zhu, Jinqiu Sun, and Yanning Zhang
- [48]
-
[49]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. 2022. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv:2203.03605 [cs.CV]
work page internal anchor Pith review arXiv 2022
- [50]
-
[51]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF inter- national conference on computer vision. 3836–3847
2023
-
[52]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[53]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[54]
Xujie Zhang, Yu Sha, Michael C Kampffmeyer, Zhenyu Xie, Zequn Jie, Chengwen Huang, Jianqing Peng, and Xiaodan Liang. 2022. Armani: Part-level garment-text alignment for unified cross-modal fashion design. InProceedings of the 30th ACM International Conference on Multimedia. 4525–4535
2022
-
[55]
Xujie Zhang, Binbin Yang, Michael C Kampffmeyer, Wenqing Zhang, Shiyue Zhang, Guansong Lu, Liang Lin, Hang Xu, and Xiaodan Liang. 2023. Diffcloth: Diffusion based garment synthesis and manipulation via structural cross-modal semantic alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision. 23154–23163
2023
-
[56]
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. 2023. Uni-controlnet: All-in-one control to text- to-image diffusion models.Advances in Neural Information Processing Systems 36 (2023), 11127–11150
2023
-
[57]
Mingkang Zhu, Xi Chen, Zhongdao Wang, Hengshuang Zhao, and Jiaya Jia. 2024. Logosticker: Inserting logos into diffusion models for customized generation. In European Conference on Computer Vision. Springer, 363–378
2024
-
[58]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593(2019). VersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis Supplementary Material The appendices pro...
work page internal anchor Pith review arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.