Recognition: no theorem link
Weaves, Wires, and Morphisms: Formalizing and Implementing the Algebra of Deep Learning
Pith reviewed 2026-05-10 18:45 UTC · model grok-4.3
The pith
A categorical framework using axis-stride and array-broadcasted categories lets deep learning architectures be expressed and manipulated as precise compositions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing the axis-stride category and the array-broadcasted category, the paper shows that broadcasting operations and model compositions in deep learning can be captured exactly as morphisms, so that any architecture becomes a well-defined arrow whose behavior is preserved under composition and can be translated directly into executable code or visual diagrams.
What carries the argument
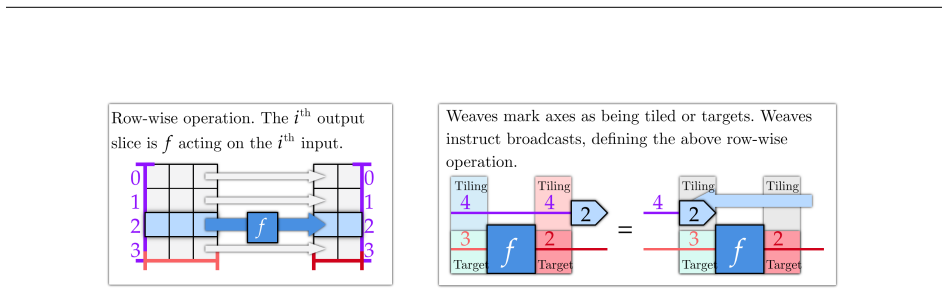
The axis-stride category and array-broadcasted category, which encode array broadcasting and nonlinear operations as morphisms so that model architectures become composable arrows.
If this is right
- Architectures can be built by algebraic combination of basic components rather than manual wiring.
- Any model can be converted to a graph representation for analysis or optimization.
- The same definitions compile directly to PyTorch tensors and operations.
- Human-readable diagrams can be generated automatically from the categorical description.
- Model design and analysis become systematic rather than dependent on informal notation.
Where Pith is reading between the lines
- The framework could support automated checks that a proposed architecture preserves desired mathematical properties under composition.
- It opens the possibility of moving models between frameworks while guaranteeing that the underlying function stays identical.
- Further extensions might formalize operations such as dynamic shapes or conditional execution that current deep learning code handles informally.
Load-bearing premise
The new categories must match every broadcasting rule and composition behavior already used in existing deep learning code without hidden mismatches or missing cases.
What would settle it
A working deep learning model whose broadcasting or composition produces different numerical results when expressed in the axis-stride and array-broadcasted categories versus a standard framework such as PyTorch.
Figures




















read the original abstract
Despite deep learning models running well-defined mathematical functions, we lack a formal mathematical framework for describing model architectures. Ad-hoc notation, diagrams, and pseudocode poorly handle nonlinear broadcasting and the relationship between individual components and composed models. This paper introduces a categorical framework for deep learning models that formalizes broadcasting through the novel axis-stride and array-broadcasted categories. This allows the mathematical function underlying architectures to be precisely expressed and manipulated in a compositional manner. These mathematical definitions are translated into human manageable diagrams and machine manageable data structures. We provide a mirrored implementation in Python (pyncd) and TypeScript (tsncd) to show the universal aspect of our framework, along with features including algebraic construction, graph conversion, PyTorch compilation and diagram rendering. This lays the foundation for a systematic, formal approach to deep learning model design and analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a categorical framework for deep learning model architectures that formalizes nonlinear broadcasting via two novel constructs: the axis-stride category and the array-broadcasted category. These are claimed to enable precise, compositional mathematical expression of the functions realized by DL models, moving beyond ad-hoc notation and diagrams. The definitions are translated into human-readable diagrams and machine-readable data structures, with mirrored implementations in Python (pyncd) and TypeScript (tsncd) that support algebraic construction of models, graph conversion, PyTorch compilation, and diagram rendering.
Significance. If the new categories are shown to be faithful to existing broadcasting semantics and to support sound composition, the work would supply a systematic algebraic language for DL architectures. The dual-language implementations and direct compilation path to PyTorch constitute concrete evidence of practicality and could facilitate automated verification or transformation of models.
major comments (2)
- [§3 (Category Definitions)] The central claim that the axis-stride and array-broadcasted categories 'precisely express' broadcasting and composition (abstract and §3) rests on the assertion that the defined morphisms and objects match the broadcasting rules of frameworks such as PyTorch. No explicit verification, naturality diagrams, or counter-example checks against standard broadcasting cases (e.g., implicit dimension expansion, stride handling) are supplied in the category-definition sections; this is load-bearing for the claim that the framework avoids ad-hoc extensions.
- [§5–6 (Implementations and Compilation)] The implementation sections (§5–6) state that the Python and TypeScript libraries compile to PyTorch and preserve algebraic semantics, yet no proof or test suite is given showing that the categorical composition operation corresponds exactly to the PyTorch forward pass under broadcasting. Without such a correspondence theorem or exhaustive test cases, the 'machine manageable' claim cannot be evaluated.
minor comments (2)
- [§3] Notation for the axis-stride objects and morphisms is introduced without a consolidated table of symbols; readers must cross-reference multiple paragraphs to reconstruct the signature of a broadcasted morphism.
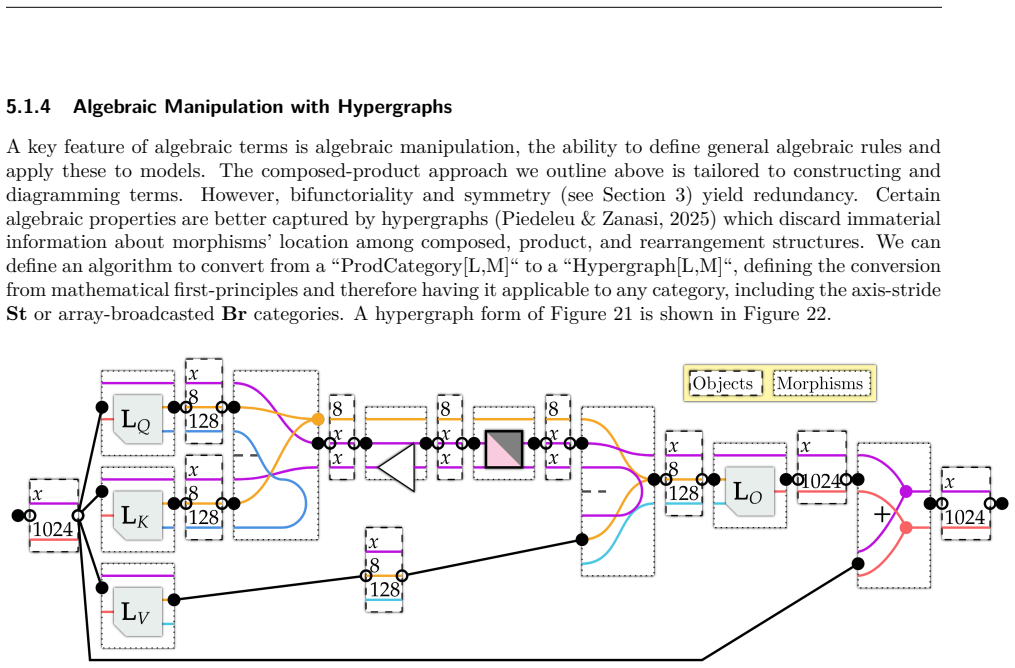
- [§4] Figure captions for the diagram-rendering examples do not indicate which categorical operations are being visualized, making it difficult to connect the rendered diagrams back to the formal definitions.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address each major point below, acknowledging where additional verification is needed, and outline the revisions we will undertake.
read point-by-point responses
-
Referee: [§3 (Category Definitions)] The central claim that the axis-stride and array-broadcasted categories 'precisely express' broadcasting and composition (abstract and §3) rests on the assertion that the defined morphisms and objects match the broadcasting rules of frameworks such as PyTorch. No explicit verification, naturality diagrams, or counter-example checks against standard broadcasting cases (e.g., implicit dimension expansion, stride handling) are supplied in the category-definition sections; this is load-bearing for the claim that the framework avoids ad-hoc extensions.
Authors: We agree that the manuscript would benefit from explicit verification to substantiate the claim of precise expression. Although the axis-stride and array-broadcasted categories were constructed directly from standard broadcasting rules (including implicit expansions and stride semantics), the current text does not include naturality diagrams or systematic counter-example checks. In the revision we will add a dedicated subsection to §3 that supplies naturality squares for the key morphisms and verifies the categories against representative PyTorch broadcasting cases, thereby confirming the absence of ad-hoc extensions. revision: yes
-
Referee: [§5–6 (Implementations and Compilation)] The implementation sections (§5–6) state that the Python and TypeScript libraries compile to PyTorch and preserve algebraic semantics, yet no proof or test suite is given showing that the categorical composition operation corresponds exactly to the PyTorch forward pass under broadcasting. Without such a correspondence theorem or exhaustive test cases, the 'machine manageable' claim cannot be evaluated.
Authors: The referee correctly identifies that a formal correspondence result or comprehensive test suite is missing. While the libraries were implemented to mirror the categorical definitions and the compilation path to PyTorch is functional, no explicit theorem or exhaustive test coverage is provided in the current draft. We will augment §6 with a concise correspondence argument explaining why algebraic composition preserves PyTorch semantics under broadcasting, accompanied by an expanded test suite that exercises the relevant cases. These additions will make the machine-manageable claim directly evaluable. revision: yes
Circularity Check
No significant circularity in the categorical formalization
full rationale
The paper introduces novel categorical definitions (axis-stride and array-broadcasted categories) directly as a new formal framework for broadcasting and compositional manipulation of deep learning models. These are not derived from fitted parameters, self-referential equations, or load-bearing self-citations; instead, they are presented as original constructions translated into diagrams and code (Python/TypeScript implementations). No derivation chain reduces a claimed result to its own inputs by construction, and the central claim remains a self-contained formalization rather than a prediction or renaming of prior results. This is the expected non-circular outcome for a purely definitional paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
net/forum?id=pF2ukh7HxA
URL https://openreview. net/forum?id=pF2ukh7HxA. Vincent Abbott, Kotaro Kamiya, Gerard Glowacki, Yu Atsumi, Gioele Zardini, and Yoshihiro Maruyama. Accelerating Machine Learning Systems via Category Theory: Applications to Spherical Attention for Gene Regulatory Networks. InArtificial General Intelligence: 18th International Conference, AGI 2025, Reykjavi...
2025
-
[2]
Springer- Verlag. ISBN 978-3-032-00685-1. doi: 10.1007/978-3-032-00686-8_1. URL https://doi.org/10.1007/ 978-3-032-00686-8_1. Michael M. Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges.arXiv preprint arXiv:2104.13478,
- [3]
-
[4]
URL https://doi.org/10.1080/00927877608822127
doi: 10.1080/00927877608822127. URL https://doi.org/10.1080/00927877608822127. TobiasFritz, TomášGonda, PaoloPerrone, andEigilFjeldgrenRischel. RepresentableMarkovcategoriesand comparison of statistical experiments in categorical probability.Theoretical Computer Science, 961:113896,
-
[5]
doi: https://doi.org/10.1016/j.tcs.2023.113896
ISSN 0304-3975. doi: https://doi.org/10.1016/j.tcs.2023.113896. URL https://www.sciencedirect. com/science/article/pii/S0304397523002098. Bruno Gavranović.Fundamental Components of Deep Learning: A Category-Theoretic Approach. PhD thesis, University of Strathclyde,
-
[6]
arXiv preprint arXiv:2207.09238 , year=
Mary Phuong and Marcus Hutter. Formal Algorithms for Transformers.arXiv preprint arXiv:2207.09238,
-
[7]
The classical result from Fox (1976) relates Cartesian to monoidal categories
A Appendix A.1 Fox’s Theorem Fox’s theorem relates the naturality of a product category to the algebraic properties and degrees of freedom of its morphisms. The classical result from Fox (1976) relates Cartesian to monoidal categories. We split the result into two sections, relating it to the properties of copying (unique identification) and deletion (fre...
1976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.