Recognition: no theorem link
Non-identifiability of Explanations from Model Behavior in Deep Networks of Image Authenticity Judgments
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
Deep neural networks that predict human image authenticity ratings produce attribution maps that disagree across architectures
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
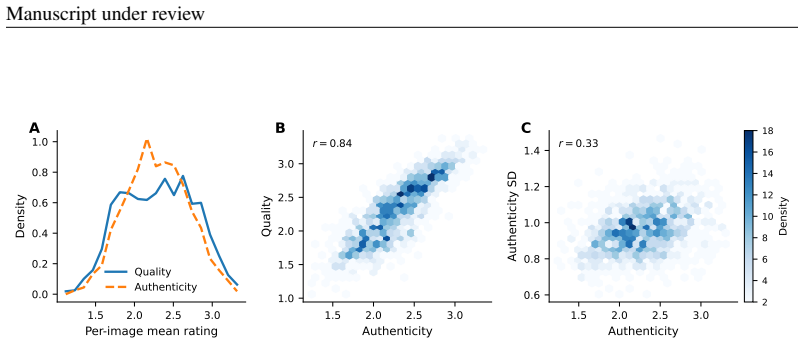
Several pretrained vision models fitted with regression heads predict human authenticity ratings of images at levels reaching about 80 percent of the noise ceiling. Attribution maps from Grad-CAM, LIME, and multiscale pixel masking remain stable within a given architecture across random seeds but show weak agreement across different architectures even when predictive performance is comparable. VGG-based models mainly track overall image quality rather than authenticity-specific features. Ensembles of models raise prediction accuracy and support image-level analysis via pixel masking, yet the cross-architecture disagreement in maps persists. The authors therefore conclude that the networks do
What carries the argument
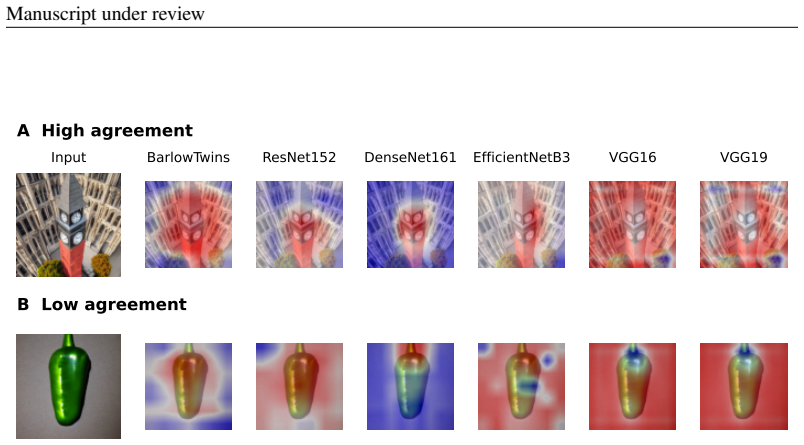
Comparison of attribution maps (visualizations of image regions most influential to each model's rating) across multiple network architectures that achieve similar accuracy in predicting human judgments. The comparison serves as the test for whether any map can be identified as reflecting the cues humans actually use.
If this is right
- Attribution maps are more consistent within an architecture for images humans rate as highly authentic.
- VGG models base ratings primarily on general image quality rather than authenticity cues.
- Ensembles of models improve accuracy in matching human authenticity judgments.
- Post-hoc explanations from models that predict behavior well supply only weak evidence for the underlying cognitive mechanisms.
Where Pith is reading between the lines
- The same pattern of predictive success without cross-model agreement on explanations may appear in models of other human visual judgments such as emotion detection or scene categorization.
- Direct experiments that alter specific image features and measure changes in human ratings could isolate the actual cues without depending on model maps.
- Adding constraints that force models to match not only final ratings but also human reaction times or eye-movement patterns might increase consistency across architectures.
Load-bearing premise
That agreement between the important regions highlighted by different model architectures is necessary to confirm that those regions reflect the cues humans use when judging authenticity.
What would settle it
If two architectures with comparable accuracy in predicting human ratings produce nearly identical attribution maps on the same images, that result would undermine the claim that explanations are non-identifiable.
Figures



read the original abstract
Deep neural networks can predict human judgments, but this does not imply that they rely on human-like information or reveal the cues underlying those judgments. Prior work has addressed this issue using attribution heatmaps, but their explanatory value in itself depends on robustness. Here we tested the robustness of such explanations by evaluating whether models that predict human authenticity ratings also produce consistent explanations within and across architectures. We fit lightweight regression heads to multiple frozen pretrained vision models and generated attribution maps using Grad-CAM, LIME, and multiscale pixel masking. Several architectures predicted ratings well, reaching about 80% of the noise ceiling. VGG models achieved this by tracking image quality rather than authenticity-specific variance, limiting the relevance of their attributions. Among the remaining models, attribution maps were generally stable across random seeds within an architecture, especially for EfficientNetB3 and Barlow Twins, and consistency was higher for images judged as more authentic. Crucially, agreement in attribution across architectures was weak even when predictive performance was similar. To address this, we combined models in ensembles, which improved prediction of human authenticity judgments and enabled image-level attribution via pixel masking. We conclude that while deep networks can predict human authenticity judgments well, they do not produce identifiable explanations for those judgments. More broadly, our findings suggest that post hoc explanations from successful models of behavior should be treated as weak evidence for cognitive mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that deep neural networks can accurately predict human authenticity judgments of images (reaching ~80% of the noise ceiling) but that post-hoc attribution methods (Grad-CAM, LIME, multiscale pixel masking) do not produce consistent, identifiable explanations across architectures. After fitting lightweight regression heads to frozen pretrained vision models, the authors report within-architecture stability (especially for EfficientNetB3 and Barlow Twins) but weak cross-architecture agreement, note that VGG models track image quality rather than authenticity cues, and show that ensembles improve both prediction and image-level attribution. They conclude that successful behavioral models yield only weak evidence for cognitive mechanisms.
Significance. If the core empirical pattern holds, the work usefully cautions against treating post-hoc attributions from high-performing DNNs as direct evidence of human-like cues in perceptual judgment tasks. It is strengthened by the systematic multi-architecture, multi-method design and the constructive use of ensembles. The findings are relevant to both interpretability research in computer vision and cognitive modeling of authenticity perception.
major comments (2)
- [Cross-architecture attribution results] Cross-architecture attribution results (abstract and corresponding results section): The inference that weak agreement across architectures demonstrates non-identifiable explanations treats cross-architecture consistency as a necessary condition for attributions to reflect underlying human cues. The manuscript demonstrates within-architecture stability but does not test the alternative that divergent maps could still be veridical if architectures encode the same cues via different internal representations (e.g., texture statistics versus edge patterns). This alternative is not ruled out by the reported controls and therefore weakens the central non-identifiability claim.
- [Methods and VGG analysis] Methods and VGG analysis (results on model performance): The exclusion of VGG models on the grounds that they track image quality rather than authenticity-specific variance is load-bearing for the remaining cross-architecture comparisons, yet the manuscript provides insufficient detail on how this reliance was quantified (e.g., specific quality metrics or correlation thresholds) and whether analogous checks were applied to the other architectures retained in the analysis.
minor comments (3)
- [Experimental setup] Experimental details: Information on data splits, exact image counts, computation of the noise ceiling, and statistical tests for attribution-map agreement measures is missing or too brief to allow full evaluation of the reported predictive performance and consistency results.
- [Figures] Visualization: Additional attribution-map examples stratified by authenticity rating level, together with side-by-side within- versus across-architecture panels, would improve clarity of the consistency claims.
- [Introduction/Discussion] Related work: The positioning would benefit from explicit citations to prior studies on the robustness and identifiability of post-hoc explanations in perceptual DNN models.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have prompted us to clarify several aspects of our analysis and strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: Cross-architecture attribution results (abstract and corresponding results section): The inference that weak agreement across architectures demonstrates non-identifiable explanations treats cross-architecture consistency as a necessary condition for attributions to reflect underlying human cues. The manuscript demonstrates within-architecture stability but does not test the alternative that divergent maps could still be veridical if architectures encode the same cues via different internal representations (e.g., texture statistics versus edge patterns). This alternative is not ruled out by the reported controls and therefore weakens the central non-identifiability claim.
Authors: We agree that our manuscript does not explicitly rule out the possibility that different architectures could encode the same cues through different representations. Our argument for non-identifiability rests on the observation that multiple high-performing models produce divergent attributions despite similar predictive accuracy, making it difficult to identify a unique set of cues from the model behavior. We will add a paragraph in the discussion section acknowledging this alternative explanation and discussing its implications for the interpretability of post-hoc attributions. revision: partial
-
Referee: Methods and VGG analysis (results on model performance): The exclusion of VGG models on the grounds that they track image quality rather than authenticity-specific variance is load-bearing for the remaining cross-architecture comparisons, yet the manuscript provides insufficient detail on how this reliance was quantified (e.g., specific quality metrics or correlation thresholds) and whether analogous checks were applied to the other architectures retained in the analysis.
Authors: We acknowledge that the manuscript lacks sufficient detail on the quantification of VGG models' reliance on image quality. We will revise the Methods section to provide the specific metrics and procedures used to determine this, as well as the results of analogous checks on the other architectures. revision: yes
Circularity Check
No circularity: purely empirical comparisons with independent results
full rationale
The paper performs an empirical analysis by fitting lightweight regression heads to frozen pretrained vision models, generating attribution maps via Grad-CAM, LIME, and pixel masking, and measuring within- and cross-architecture consistency. Predictive performance reaches ~80% of the noise ceiling for several models, and the central finding of weak cross-architecture agreement in attributions is reported as a direct observational result. No derivation, equation, or claim reduces to a fitted parameter by construction, no self-citation chain bears the load of the identifiability conclusion, and no ansatz or uniqueness theorem is smuggled in. The work is self-contained against external benchmarks of model performance and attribution stability.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/1810. 03292. arXiv:1810.03292 [cs]. Jeffrey S Bowers, Gaurav Malhotra, Marin Dujmovi ´c, Milton Llera Montero, Christian Tsvetkov, Valerio Biscione, Guillermo Puebla, Federico Adolfi, John E Hummel, Rachel F Heaton, et al. Deep problems with neural network models of human vision.Behavioral and Brain Sciences, 46: e385,
-
[2]
Tom Burgert, Oliver Stoll, Paolo Rota, and Beg ¨um Demir. Imagenet-trained cnns are not bi- ased towards texture: Revisiting feature reliance through controlled suppression.arXiv preprint arXiv:2509.20234,
-
[3]
Deep Residual Learning for Image Recognition
URLhttp://arxiv.org/abs/1512.03385. arXiv:1512.03385 [cs]. Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely Connected Convolutional Networks, January
work page internal anchor Pith review arXiv
-
[4]
Densely connected convolutional networks,
URLhttp://arxiv.org/abs/1608.06993. arXiv:1608.06993 [cs]. Aditya Khosla, Akhil S Raju, Antonio Torralba, and Aude Oliva. Understanding and predicting image memorability at a large scale. InProceedings of the IEEE international conference on computer vision, pp. 2390–2398,
-
[5]
ISSN 0920-5691, 1573-1405. doi: 10.1007/s11263-019-01228-7. URLhttp://arxiv.org/ abs/1610.02391. arXiv:1610.02391 [cs]. Karen Simonyan and Andrew Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition, April
-
[6]
Very Deep Convolutional Networks for Large-Scale Image Recognition
URLhttp://arxiv.org/abs/1409.1556. arXiv:1409.1556 [cs]. Katherine R Storrs, Tim C Kietzmann, Alexander Walther, Johannes Mehrer, and Nikolaus Kriegeskorte. Diverse deep neural networks all predict human inferior temporal cortex well, after training and fitting.Journal of cognitive neuroscience, 33(10):2044–2064,
work page internal anchor Pith review Pith/arXiv arXiv 2044
-
[7]
arXiv preprint arXiv:2310.13018 , year=
Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C Love, Erin Grant, Iris Groen, Jascha Achterberg, et al. Getting aligned on repre- sentational alignment.arXiv preprint arXiv:2310.13018,
-
[8]
Efficientnet: Rethinking model scaling for convolutional neural networks,
URLhttp://arxiv.org/abs/1905.11946. arXiv:1905.11946 [cs]. Zhenchen Tang, Zichuan Wang, Bo Peng, and Jing Dong. Clip-agiqa: boosting the performance of ai-generated image quality assessment with clip. InInternational Conference on Pattern Recog- nition, pp. 48–61. Springer,
- [9]
-
[10]
GradCAM similarity IoU @ 5 GradCAM similarity IoU @ 25 Figure A.4:Across-architecture similarity (IoU)
Each cell shows the mean Spearman correlation between prototype Grad-CAM maps for a pair of architectures, averaged across test-set images, with the SD across images in parentheses. GradCAM similarity IoU @ 5 GradCAM similarity IoU @ 25 Figure A.4:Across-architecture similarity (IoU). Each cell shows average Intersection-Over- Union overlap of top 5% (and...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.