Recognition: 2 theorem links
· Lean TheoremAre Face Embeddings Compatible Across Deep Neural Network Models?
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
Simple linear mappings align face embeddings from different DNN models and improve cross-model recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Different DNN models encode facial identity in sufficiently similar geometric structures that low-capacity linear mappings can align their embedding spaces, leading to substantial improvements in cross-model face recognition for both identification and verification. These alignment patterns generalize across datasets and vary systematically across model families, pointing to representational convergence in facial identity encoding.
What carries the argument
Low-capacity linear mappings, or affine transformations, applied to the point clouds formed by face embeddings from different models to test and achieve alignment between their geometric structures.
If this is right
- Cross-model face recognition can be performed without retraining or complex non-linear alignments.
- Alignment behavior is consistent enough to generalize from one dataset to another.
- Different model families exhibit distinct but still alignable embedding geometries.
- Model ensembles in biometrics may benefit from simple pre-alignment steps.
- Shared representations raise questions about template security when embeddings from multiple models are used together.
Where Pith is reading between the lines
- The same linear-mapping approach might reveal compatibility patterns in other biometric traits such as fingerprints or voice.
- If the convergence holds, updating or swapping one model for another in a deployed system could require only a lightweight adapter rather than full re-enrollment.
- Foundation models pretrained on broad vision tasks may already capture core identity features that specialized face models refine.
- Limits of this compatibility could be probed by including models trained on non-face domains or on heavily augmented data.
Load-bearing premise
The embedding spaces of different models share enough geometric similarity that affine transformations can produce meaningful alignment, and that measured performance gains arise from this alignment rather than from dataset overlap or other unaccounted factors.
What would settle it
Training the linear mappings on one pair of models and datasets then testing on a fresh pair of models and a disjoint face dataset yields no accuracy gain over the unaligned baseline in identification or verification.
Figures




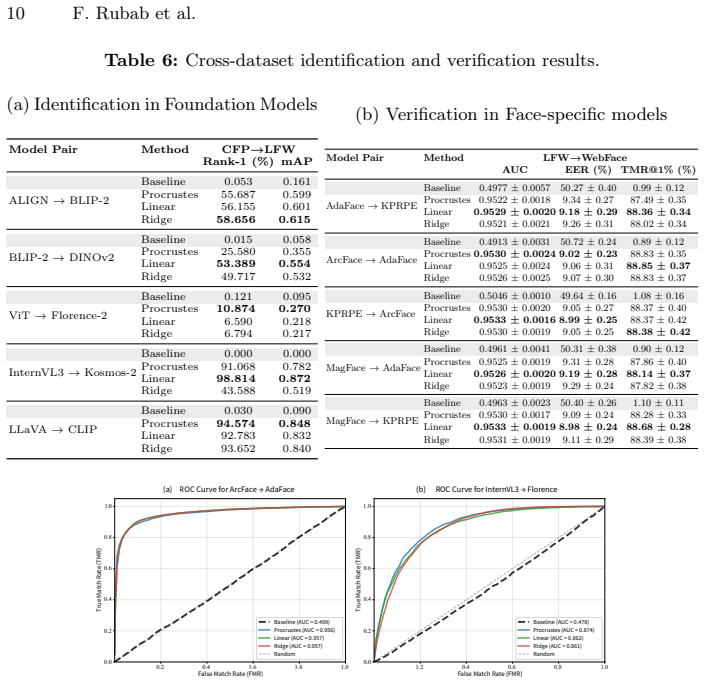


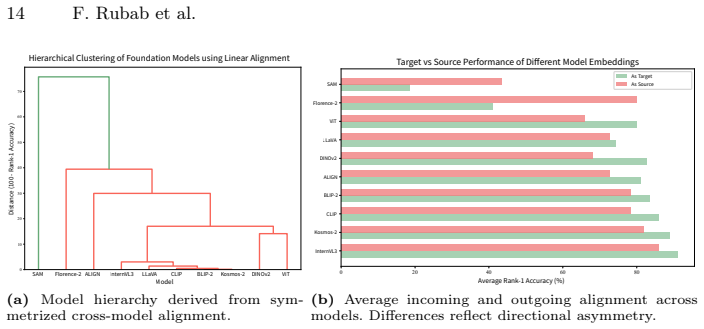
read the original abstract
Automated face recognition has made rapid strides over the past decade due to the unprecedented rise of deep neural network (DNN) models that can be trained for domain-specific tasks. At the same time, foundation models that are pretrained on broad vision or vision-language tasks have shown impressive generalization across diverse domains, including biometrics. This raises an important question: Do different DNN models--both domain-specific and foundation models--encode facial identity in similar ways, despite being trained on different datasets, loss functions, and architectures? In this regard, we directly analyze the geometric structure of embedding spaces imputed by different DNN models. Treating embeddings of face images as point clouds, we study whether simple affine transformations can align face representations of one model with another. Our findings reveal surprising cross-model compatibility: low-capacity linear mappings substantially improve cross-model face recognition over unaligned baselines for both face identification and verification tasks. Alignment patterns generalize across datasets and vary systematically across model families, indicating representational convergence in facial identity encoding. These findings have implications for model interoperability, ensemble design, and biometric template security.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether face embeddings from different DNN models (domain-specific and foundation models) encode facial identity in compatible ways by testing if low-capacity affine transformations can align their embedding spaces, treated as point clouds. It reports that such mappings substantially improve cross-model face identification and verification over unaligned baselines, with patterns that generalize across datasets and vary systematically by model family, interpreted as evidence of representational convergence.
Significance. If robust, the results would support the existence of shared geometric structure in facial identity representations across diverse training regimes, enabling better model interoperability, ensembles, and insights into biometric template security. The use of low-capacity mappings provides a simple, falsifiable test of compatibility that generalizes across datasets, which is a strength of the empirical design.
major comments (3)
- [Abstract] Abstract and experimental description: the central claim that improvements arise from geometric alignment (representational convergence) rather than dataset biases or leakage requires explicit controls, such as fitting the affine mappings on completely disjoint identities and data from the recognition benchmarks. No such splits or controls are described, leaving open that the mappings act as supervised adapters.
- [Abstract] Abstract: the unaligned baseline is not defined for models with differing embedding dimensions and scales. Without details on normalization, zero-padding, or projection steps used in the baseline, the reported gains cannot be attributed specifically to alignment of geometric structures.
- [Results] Results section: no statistical tests, confidence intervals, or multiple-run variance are reported for the identification and verification improvements, weakening the claims that alignment patterns 'generalize across datasets' and 'vary systematically across model families'.
minor comments (2)
- [Abstract] Abstract: terminology inconsistency between 'affine transformations' and 'low-capacity linear mappings' – clarify whether the mappings include a translation/bias term.
- Provide the exact number of parameters in the mappings, the optimization objective used to learn them, and the specific models/datasets to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify key areas where additional controls, clarity, and statistical rigor will strengthen the manuscript's claims about representational convergence in face embeddings. We address each major comment point-by-point below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: the central claim that improvements arise from geometric alignment (representational convergence) rather than dataset biases or leakage requires explicit controls, such as fitting the affine mappings on completely disjoint identities and data from the recognition benchmarks. No such splits or controls are described, leaving open that the mappings act as supervised adapters.
Authors: We agree that this is a valid concern. In the current experiments, the affine transformations were fitted using the same set of face images and identities appearing in the identification and verification benchmarks, which does not fully rule out the possibility that the mappings exploit dataset-specific information rather than intrinsic geometric compatibility. To address this, we will add new experiments in the revised manuscript that fit the affine mappings exclusively on completely disjoint identities and images, separate from all recognition benchmark data. These controls will be reported alongside the original results to demonstrate that the cross-model improvements persist under stricter conditions. revision: yes
-
Referee: [Abstract] Abstract: the unaligned baseline is not defined for models with differing embedding dimensions and scales. Without details on normalization, zero-padding, or projection steps used in the baseline, the reported gains cannot be attributed specifically to alignment of geometric structures.
Authors: The referee is correct that the abstract and experimental description lack sufficient detail on the unaligned baseline. For models with different embedding dimensions, our unaligned comparisons normalized embeddings to unit length and applied zero-padding (for lower-dimensional models) or a fixed random projection to a common dimension before computing distances. However, these steps were not explicitly documented. We will revise the abstract, methods, and results sections to provide a complete, precise definition of the unaligned baseline, including all normalization and projection procedures, so that the specific contribution of the learned affine alignment can be clearly isolated and evaluated. revision: yes
-
Referee: [Results] Results section: no statistical tests, confidence intervals, or multiple-run variance are reported for the identification and verification improvements, weakening the claims that alignment patterns 'generalize across datasets' and 'vary systematically across model families'.
Authors: We acknowledge that the lack of statistical analysis limits the strength of the generalization claims. The original results reported single-run point estimates without variance or significance testing. In the revision, we will re-run the identification and verification experiments across multiple random seeds for affine fitting and data subsampling, include bootstrap confidence intervals or standard deviations for all metrics, and add paired statistical tests (e.g., Wilcoxon signed-rank) to quantify whether improvements are significant across datasets and model families. These additions will be incorporated into the results section and figures. revision: yes
Circularity Check
No significant circularity; empirical measurements of alignment effects
full rationale
The paper is an empirical study that extracts embeddings from multiple DNN models, treats them as point clouds, fits low-capacity affine mappings between pairs of embedding spaces, and measures resulting gains in cross-model identification and verification accuracy relative to unaligned baselines. No derivation chain, uniqueness theorem, or predictive claim is advanced that reduces by construction to the fitted parameters or to self-citations. Alignment patterns are reported as observed outcomes across datasets and model families; the central claim of representational convergence is an interpretation of those measurements rather than a quantity forced by the fitting procedure itself. External validity concerns (dataset bias, leakage) are orthogonal to circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- affine transformation parameters
axioms (1)
- domain assumption Embedding spaces from different DNNs are related by affine transformations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
low-capacity linear mappings substantially improve cross-model face recognition... geometric structure of embedding spaces... tangent-space alignment
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
simple affine transformations can align face representations... manifold learning theory
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Asso- ciation for Computational Linguistics (ACL)
Artetxe, M., Labaka, G., Agirre, E.: A robust self-learning method for fully unsu- pervised cross-lingual mappings of word embeddings. In: Proceedings of the Asso- ciation for Computational Linguistics (ACL). pp. 789–798 (2018) 3
2018
-
[2]
IEEE Transactions on Biometrics, Behavior, and Identity Science (2026) 1
Bhatta, A., Argueta, G., King, M.C., Bowyer, K.W.: Revocable biometric sys- tem using multiple identical deep neural matcher instances. IEEE Transactions on Biometrics, Behavior, and Identity Science (2026) 1
2026
-
[3]
In: 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG)
Bhatta, A., King, M.C., Bowyer, K.W.: Deep cnn face matchers inherently support revocable biometric templates. In: 2025 IEEE 19th International Conference on Automatic Face and Gesture Recognition (FG). pp. 1–10 (2025) 1, 4
2025
-
[4]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2024) 3
Chettaoui, C., Daoudi, M., Boutellaâ, N.: Face recognition with foundation models: A study with clip and dinov2. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2024) 3
2024
-
[6]
In: International Conference on Learning Representations (ICLR) (2018) 3
Conneau, A., Lample, G., Ranzato, M., Denoyer, L., Jégou, H.: Word translation without parallel data. In: International Conference on Learning Representations (ICLR) (2018) 3
2018
-
[7]
poor” verification system be a “good
DeCann, B., Ross, A.: Can a “poor” verification system be a “good” identification system?apreliminarystudy.In:2012IEEEInternationalWorkshoponInformation Forensics and Security (WIFS). pp. 31–36 (2012) 11
2012
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4690–4699 (2019) 1, 3, 4
2019
-
[9]
Huang, G.B., Mattar, M., Berg, T., Learned-Miller, E.: Labeled faces in the wild: A databaseforstudyingfacerecognitioninunconstrainedenvironments.In:Workshop on faces in’Real-Life’Images: detection, alignment, and recognition (2008) 4
2008
-
[10]
EURASIP Journal on Advances in Signal Processing pp
Jain, A.K., Nandakumar, K., Nagar, A.: Biometric template security. EURASIP Journal on Advances in Signal Processing pp. 1–17 (2008) 4
2008
-
[11]
In: International Conference on Machine Learning (ICML)
Jia,C.,Yang,Y.,Xia,Y.,Chen,Y.T.,Parekh,Z.,Pham,H.,Le,Q.,Sung,Y.H.,Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International Conference on Machine Learning (ICML). pp. 4904–4916 (2021) 4
2021
-
[12]
Proceedings of the National Academy of Sciences 120(43), e2304085120 (2023) 3
Jiahui, G., Feilong, M., Visconti di Oleggio Castello, M., Nastase, S.A., Haxby, J.V., Gobbini, M.I.: Modeling naturalistic face processing in humans with deep convolutional neural networks. Proceedings of the National Academy of Sciences 120(43), e2304085120 (2023) 3
2023
-
[13]
IEEE Transac- tions on Pattern Analysis and Machine Intelligence (2026) 4
Kim, M., Jain, A., Liu, X.: 50 years of automated face recognition. IEEE Transac- tions on Pattern Analysis and Machine Intelligence (2026) 4
2026
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kim,M.,Jain,A.K.,Liu,X.:Adaface:Qualityadaptivemarginforfacerecognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18750–18759 (2022) 1, 3, 4 16 F. Rubab et al
2022
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kim, M., Su, Y., Liu, F., Jain, A., Liu, X.: Keypoint relative position encoding for face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 244–255 (2024) 4
2024
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4015– 4026 (2023) 4
2023
-
[17]
ACM Computing Surveys57(9), 1–52 (2025) 3
Klabunde, M., Schumacher, T., Strohmaier, M., Lemmerich, F.: Similarity of neu- ral network models: A survey of functional and representational measures. ACM Computing Surveys57(9), 1–52 (2025) 3
2025
-
[18]
International Conference on Machine Learning (ICML) pp
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. International Conference on Machine Learning (ICML) pp. 3519–3529 (2019) 3
2019
-
[19]
In: International Conference on Machine Learning (ICML) (2023) 4
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International Conference on Machine Learning (ICML) (2023) 4
2023
-
[20]
Li, Y., Yosinski, J., Clune, J., Lipson, H., Hopcroft, J.: Convergent learning: Do different neural networks learn the same representations? arXiv preprint arXiv:1511.07543 (2015) 3
work page Pith review arXiv 2015
-
[21]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Advances in Neural Information Processing Systems (NeurIPS) (2023) 4
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Meng, Q., Zhao, S., Huang, Z., Zhou, F.: Magface: A universal representation for face recognition and quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). pp. 14225–14234 (2021) 1, 3, 4
2021
-
[23]
Transactions on Machine Learning Research (TMLR) (2024) 4
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research (TMLR) (2024) 4
2024
-
[24]
O’Toole, A.J., Castillo, C.D., Parde, C.J., Hill, M.Q., Chellappa, R.: Face space representationsindeepconvolutionalneuralnetworks.TrendsinCognitiveSciences 22(9), 794–809 (2018) 12
2018
-
[25]
In: International Conference on Learning Representations (ICLR) (2024) 4
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos- 2: Grounding multimodal large language models to the world. In: International Conference on Learning Representations (ICLR) (2024) 4
2024
-
[26]
In: International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (ICML). pp. 8748–8763 (2021) 4
2021
-
[27]
Ad- vances in Neural Information Processing Systems (NeurIPS)30(2017) 3
Raghu, M., Gilmer, J., Yosinski, J., Sohl-Dickstein, J.: Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. Ad- vances in Neural Information Processing Systems (NeurIPS)30(2017) 3
2017
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelli- gence (TPAMI)29(4), 561–572 (2007) 4
Ratha, N.K., Chikkerur, S., Connell, J.H., Bolle, R.M.: Generating cancelable fin- gerprint templates. IEEE Transactions on Pattern Analysis and Machine Intelli- gence (TPAMI)29(4), 561–572 (2007) 4
2007
-
[29]
Psychometrika31(1), 1–10 (1966) 6
Schönemann, P.H.: A generalized solution of the orthogonal procrustes problem. Psychometrika31(1), 1–10 (1966) 6
1966
-
[30]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 815–823 (2015) 3 Are Face Embeddings Compatible Across Deep Neural Network Models? 17
2015
-
[31]
In: IEEE Winter Conference on Applications of Computer Vision (WACV)
Sengupta, S., Chen, J.C., Castillo, C., Patel, V.M., Chellappa, R., Jacobs, D.W.: Frontal to profile face verification in the wild. In: IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 1–9 (2016) 4
2016
-
[32]
In: 2024 IEEE 18th International Confer- ence on Automatic Face and Gesture Recognition (FG)
Shahreza, H.O., Marcel, S.: Breaking template protection: Reconstruction of face images from protected facial templates. In: 2024 IEEE 18th International Confer- ence on Automatic Face and Gesture Recognition (FG). pp. 1–7 (2024) 4
2024
-
[33]
Benchmarking foun- dation models for zero-shot biometric tasks.arXiv preprint arXiv:2505.24214, 2025
Sony, R., Farmanifard, P., Alzwairy, H., Shukla, N., Ross, A.: Benchmarking foundation models for zero-shot biometric tasks. arXiv preprint arXiv:2505.24214 (2025) 1, 3
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCVw)
Sony, R., Farmanifard, P., Ross, A., Jain, A.K.: Foundation versus domain-specific models: Performance comparison, fusion, and explainability in face recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCVw). pp. 3656–3666 (2025) 1
2025
-
[35]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z., Liu, W.: Cos- face: Large margin cosine loss for deep face recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5265–5274 (2018) 3
2018
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 4
Xiao, B., Wu, H., Xu, W., Dai, X., Hu, H., Lu, Y., Zeng, M., Liu, C., Yuan, L.: Florence-2: Advancing a unified representation for a variety of vision tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 4
2024
-
[37]
Learning Face Representation from Scratch
Yi, D., Lei, Z., Liao, S., Li, S.Z.: Learning face representation from scratch. arXiv preprint arXiv:1411.7923 (2014) 5
work page Pith review arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.