Recognition: unknown
TAMEn: Tactile-Aware Manipulation Engine for Closed-Loop Data Collection in Contact-Rich Tasks
Pith reviewed 2026-05-10 17:35 UTC · model grok-4.3
The pith
A cross-morphology wearable interface with dual-modal tracking collects tactile-rich data that raises bimanual manipulation success from 34 percent to 75 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAMEn is a tactile-aware manipulation engine that uses a cross-morphology wearable interface and a dual-modal acquisition pipeline of precision motion-capture mode plus portable VR-based mode. This hardware supports a pyramid-structured data regime that unifies large-scale tactile pretraining, task-specific bimanual demonstrations, and human-in-the-loop recovery data with visualized tactile feedback, enabling closed-loop policy refinement that improves demonstration replayability and lifts success rates from 34 percent to 75 percent across diverse bimanual manipulation tasks.
What carries the argument
The cross-morphology wearable interface together with the dual-modal precision and portable acquisition pipeline that supplies a pyramid-structured regime of tactile pretraining, demonstrations, and recovery data.
If this is right
- The feasibility-aware pipeline produces demonstrations that replay more reliably on the robot.
- Visuo-tactile policies trained under the pyramid regime reach 75 percent success on the tested contact-rich bimanual tasks.
- Human-in-the-loop recovery sessions supply interactive data that refines policies beyond static demonstrations alone.
- The open-sourced hardware and dataset allow direct reproduction and extension of the visuo-tactile collection method.
Where Pith is reading between the lines
- The same wearable hardware could be adapted to collect data for single-arm or multi-robot contact tasks where gripper morphology varies.
- Portable VR mode might enable gathering of tactile demonstrations outside controlled lab spaces in more varied settings.
- Adding recovery data with real tactile feedback may lower the volume of simulation pretraining required for contact-rich skills.
- Similar closed-loop collection pipelines could be tested with other sensory streams such as force-torque or audio to check transfer of the pyramid structure.
Load-bearing premise
The wearable interface and dual-modal pipeline supply sufficiently authentic tactile signals during both high-precision demonstrations and human-in-the-loop recovery without adding artifacts that harm policy learning.
What would settle it
Training the same policy architecture on the collected demonstrations but without the tactile channel and observing success rates that stay at or below the 34 percent baseline on the reported bimanual tasks.
Figures













read the original abstract
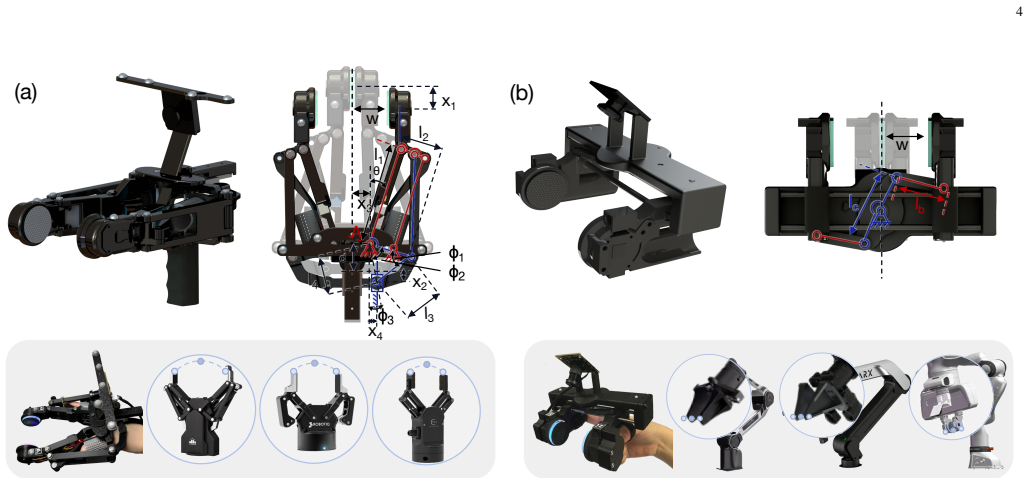
Handheld paradigms offer an efficient and intuitive way for collecting large-scale demonstration of robot manipulation. However, achieving contact-rich bimanual manipulation through these methods remains a pivotal challenge, which is substantially hindered by hardware adaptability and data efficacy. Prior hardware designs remain gripper-specific and often face a trade-off between tracking precision and portability. Furthermore, the lack of online feasibility checking during demonstration leads to poor replayability. More importantly, existing handheld setups struggle to collect interactive recovery data during robot execution, lacking the authentic tactile information necessary for robust policy refinement. To bridge these gaps, we present TAMEn, a tactile-aware manipulation engine for closed-loop data collection in contact-rich tasks. Our system features a cross-morphology wearable interface that enables rapid adaptation across heterogeneous grippers. To balance data quality and environmental diversity, we implement a dual-modal acquisition pipeline: a precision mode leveraging motion capture for high-fidelity demonstrations, and a portable mode utilizing VR-based tracking for in-the-wild acquisition and tactile-visualized recovery teleoperation. Building on this hardware, we unify large-scale tactile pretraining, task-specific bimanual demonstrations, and human-in-the-loop recovery data into a pyramid-structured data regime, enabling closed-loop policy refinement. Experiments show that our feasibility-aware pipeline significantly improves demonstration replayability, and that the proposed visuo-tactile learning framework increases task success rates from 34% to 75% across diverse bimanual manipulation tasks. We further open-source the hardware and dataset to facilitate reproducibility and support research in visuo-tactile manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TAMEn, a tactile-aware manipulation engine for closed-loop data collection in contact-rich bimanual tasks. It proposes a cross-morphology wearable interface for rapid gripper adaptation, a dual-modal pipeline (precision mode with motion capture for high-fidelity data and portable mode with VR for in-the-wild collection and tactile-visualized human-in-the-loop recovery), and a pyramid-structured data regime that combines large-scale tactile pretraining, task demonstrations, and recovery data for policy refinement. The authors claim this yields significantly better demonstration replayability and raises task success rates from 34% to 75% across diverse bimanual tasks, while open-sourcing the hardware and dataset.
Significance. If the empirical outcomes are substantiated, the work could provide a practical advance in scalable data collection for visuo-tactile robot learning by solving hardware adaptability and enabling authentic interactive recovery data. The open-sourcing of hardware and dataset is a clear strength that supports reproducibility and further research in contact-rich manipulation.
major comments (2)
- [Abstract] Abstract: the central claim that the visuo-tactile framework increases success rates from 34% to 75% is presented without any experimental details on trial counts, baselines, statistical tests, variance, or error analysis, preventing evaluation of whether the reported gain is robust or reproducible.
- [Hardware and data pipeline sections] Hardware and data pipeline sections: the load-bearing assumption that the cross-morphology wearable and dual-modal (mocap/VR) streams deliver sufficiently authentic contact forces and slip events for policy training is not supported by any quantitative validation such as force RMSE against calibrated robot sensors, latency measurements, or cross-gripper calibration residuals.
minor comments (2)
- [Data regime description] The description of the pyramid-structured data regime would benefit from a diagram or explicit breakdown of data volumes and weighting at each level to clarify how pretraining, demonstrations, and recovery interact.
- [Figures] Ensure all figures showing the wearable interface include scale bars and clear labels for sensor placement to aid hardware replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the two major comments point by point below, indicating the revisions we will incorporate to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the visuo-tactile framework increases success rates from 34% to 75% is presented without any experimental details on trial counts, baselines, statistical tests, variance, or error analysis, preventing evaluation of whether the reported gain is robust or reproducible.
Authors: We agree that the abstract, being a high-level summary, omits the granular experimental statistics that appear in the Experiments section. To address this, we will revise the abstract to include key details such as the number of trials conducted across tasks, the specific baselines used for comparison, and references to the statistical analysis and variance reported in the body of the paper. This will make the central claim more self-contained while preserving the abstract's brevity. revision: yes
-
Referee: [Hardware and data pipeline sections] Hardware and data pipeline sections: the load-bearing assumption that the cross-morphology wearable and dual-modal (mocap/VR) streams deliver sufficiently authentic contact forces and slip events for policy training is not supported by any quantitative validation such as force RMSE against calibrated robot sensors, latency measurements, or cross-gripper calibration residuals.
Authors: We acknowledge that the manuscript does not include explicit quantitative validation metrics (force RMSE, latency, or cross-gripper residuals) in the hardware and pipeline sections to directly support the authenticity of captured contact forces and slip events. This is a fair observation. We will add these validations in the revised manuscript, including force sensing accuracy comparisons, system latency measurements for both modes, and calibration results across gripper morphologies, to better substantiate the data quality assumptions. revision: yes
Circularity Check
No derivation chain present; empirical system description with measured outcomes
full rationale
The manuscript describes a hardware-software pipeline for visuo-tactile data collection and reports empirical task success rates (34% to 75%). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is an observed performance delta from controlled experiments, not a mathematical reduction to prior inputs. Per the hard rules, absence of any quotable derivation step that reduces to its own inputs yields score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vitamin-b: A reliable and efficient visuo-tactile bimanual manipulation interface,
C. Li, C. Liu, D. Wang, S. Zhang, L. Li, Z. Zeng, F. Liu, J. Xu, and R. Chen, “Vitamin-b: A reliable and efficient visuo-tactile bimanual manipulation interface,”arXiv preprint arXiv:2511.05858, 2025
-
[2]
Occlusion-robust autonomous robotic manipulation of human soft tissues with 3-d surface feedback,
J. Hu, D. Jones, M. R. Dogar, and P. Valdastri, “Occlusion-robust autonomous robotic manipulation of human soft tissues with 3-d surface feedback,”TRO, 2023
2023
-
[3]
Goal-conditioned dual-action imitation learning for dexterous dual-arm robot manipulation,
H. Kim, Y . Ohmura, and Y . Kuniyoshi, “Goal-conditioned dual-action imitation learning for dexterous dual-arm robot manipulation,”TRO, 2024
2024
-
[4]
Evetac: An event-based optical tactile sensor for robotic manipulation,
N. Funk, E. Helmut, G. Chalvatzaki, R. Calandra, and J. Peters, “Evetac: An event-based optical tactile sensor for robotic manipulation,”TRO, 2024
2024
-
[5]
Skillvla: Tackling combinatorial diversity in dual-arm manipulation via skill reuse,
X. Zhai, Z. Huang, L. Wu, Q. Zhao, Q. Yu, J. Ren, C. Hao, and H. Soh, “Skillvla: Tackling combinatorial diversity in dual-arm manipulation via skill reuse,”arXiv preprint arXiv:2603.03836, 2026
-
[6]
RISE: Self-Improving Robot Policy with Compositional World Model
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, P. Luo, X. Yue, and H. Li, “Rise: Self- improving robot policy with compositional world model,”arXiv preprint arXiv:2602.11075, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
π0.5: a vision-language-action model with open-world generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
-
[8]
Rotipbot: Robotic handling of thin and flexible objects using rotatable tactile sensors,
J. Jiang, X. Zhang, D. F. Gomes, T.-T. Do, and S. Luo, “Rotipbot: Robotic handling of thin and flexible objects using rotatable tactile sensors,”TRO, 2025
2025
-
[9]
AnyTouch 2: General optical tactile rep- resentation learning for dynamic tactile perception, 2026
R. Feng, Y . Zhou, S. Mei, D. Zhou, P. Wang, S. Cui, B. Fang, G. Yao, and D. Hu, “Anytouch 2: General optical tactile representation learning for dynamic tactile perception,”arXiv preprint arXiv:2602.09617, 2026
-
[10]
Egomimic: Scaling imitation learning via egocentric video,
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu, “Egomimic: Scaling imitation learning via egocentric video,” inICRA, 2025
2025
-
[11]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang, “Egodex: Learning dexterous manipulation from large-scale egocentric video,” arXiv preprint arXiv:2505.11709, 2026
-
[12]
Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen, “Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,”arXiv preprint arXiv:2602.10106, 2026
-
[13]
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu, “Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,”arXiv preprint arXiv:2503.02881, 2025
-
[14]
Unibidex: A unified teleoperation framework for robotic bimanual dexterous manipulation,
Z. Li, Z. Guo, J. Hu, D. Navarro-Alarcon, J. Pan, H. Wu, and P. Zhou, “Unibidex: A unified teleoperation framework for robotic bimanual dexterous manipulation,”arXiv preprint arXiv:2601.04629, 2026
-
[15]
Dart: Dexterous augmented reality teleoperation platform for large-scale robot data collection in simulation,
Y . Park, J. S. Bhatia, L. Ankile, and P. Agrawal, “Dart: Dexterous augmented reality teleoperation platform for large-scale robot data collection in simulation,” inICRA, 2025
2025
-
[16]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,”arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
H. Ha, Y . Gao, Z. Fu, J. Tan, and S. Song, “Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,”arXiv preprint arXiv:2407.10353, 2024
-
[18]
Mv-umi: A scalable multi- view interface for cross-embodiment learning, 2025
O. Rayyan, J. Abanes, M. Hafez, A. Tzes, and F. Abu-Dakka, “Mv-umi: A scalable multi-view interface for cross-embodiment learning,”arXiv preprint arXiv:2509.18757, 2025
-
[19]
arXiv preprint arXiv:2511.00153 , year=
J. Yu, Y . Shentu, D. Wu, P. Abbeel, K. Goldberg, and P. Wu, “Egomi: Learning active vision and whole-body manipulation from egocentric human demonstrations,”arXiv preprint arXiv:2511.00153, 2026
-
[20]
Zhaxizhuoma, K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, H. Song, D. Qu, D. Wang, Z. Wang, N. Cao, Y . Ding, B. Zhao, and X. Li, “Fastumi: A scalable and hardware- independent universal manipulation interface with dataset,”arXiv preprint arXiv:2409.19499, 2025
-
[21]
Legato: Cross- embodiment imitation using a grasping tool,
M. Seo, H. A. Park, S. Yuan, Y . Zhu, and L. Sentis, “Legato: Cross- embodiment imitation using a grasping tool,”RAL, 2025
2025
-
[22]
Y . Huang, S. Li, X. Li, and W. Ding, “Umigen: A unified framework for egocentric point cloud generation and cross-embodiment robotic imitation learning,”arXiv preprint arXiv:2511.09302, 2025
-
[23]
Tactile-conditioned diffusion policy for force-aware robotic manipulation, 2025
E. Helmut, N. Funk, T. Schneider, C. de Farias, and J. Peters, “Tactile- conditioned diffusion policy for force-aware robotic manipulation,”arXiv preprint arXiv:2510.13324, 2025
-
[24]
Can vision feel touch? tactile- aware visual grasping for transparent objects,
L. Tong, K. Qian, Z. Yue, and S. Luo, “Can vision feel touch? tactile- aware visual grasping for transparent objects,”TCSVT, 2026
2026
-
[25]
G. Lee, Y . Lee, K. Kim, S. Lee, S. Noh, S. Back, and K. Lee, “Manipforce: Force-guided policy learning with frequency-aware representation for contact-rich manipulation,”arXiv preprint arXiv:2509.19047, 2025
-
[26]
Y . Li, Y . Chen, Z. Zhao, P. Li, T. Liu, S. Huang, and Y . Zhu, 12 “Simultaneous tactile-visual perception for learning multimodal robot manipulation,”arXiv preprint arXiv:2512.09851, 2026
-
[27]
Dexgrasp-zero: A morphology-aligned policy for zero-shot cross- embodiment dexterous grasping,
Y . Wu, Y . Lin, W. Lao, Y . Lin, Y .-L. Wei, W.-S. Zheng, and A. Wu, “Dexgrasp-zero: A morphology-aligned policy for zero-shot cross- embodiment dexterous grasping,”arXiv preprint arXiv:2603.16806, 2026
-
[28]
Xgrasp: Gripper-aware grasp detection with multi-gripper data generation,
Y . Lee, J. Mun, H. Shin, G. Hwang, J. Nam, T. Lee, and S. Jo, “Xgrasp: Gripper-aware grasp detection with multi-gripper data generation,”arXiv preprint arXiv:2510.11036, 2026
-
[29]
ARCap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,
S. Chen, C. Wang, K. Nguyen, L. Fei-Fei, and C. K. Liu, “ARCap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,” inICRA, 2025
2025
-
[30]
Robopocket: Improve robot policies instantly with your phone.arXiv preprint arXiv:2603.05504, 2026
J. Fang, W. Chen, H. Xue, F. Zhou, T. Le, Y . Wang, Y . Zhang, J. Lv, C. Wen, and C. Lu, “Robopocket: Improve robot policies instantly with your phone,”arXiv preprint arXiv:2603.05504, 2026
-
[31]
Clear- mp: Clearance learning-based efficient motion planning for dual-arm robots under end-effector orientation constraints,
B. Chen, H. Zhang, K. Li, Y . Fan, Y . Jiang, C. Yang, and Y . Wang, “Clear- mp: Clearance learning-based efficient motion planning for dual-arm robots under end-effector orientation constraints,”TASE, 2026
2026
-
[32]
X. Xu, Y . Hou, C. Xin, Z. Liu, and S. Song, “Compliant residual dagger: Improving real-world contact-rich manipulation with human corrections,” arXiv preprint arXiv:2506.16685, 2025
-
[33]
Racer: Rich language-guided failure recovery policies for imitation learning,
Y . Dai, J. Lee, N. Fazeli, and J. Chai, “Racer: Rich language-guided failure recovery policies for imitation learning,” inICRA, 2025
2025
-
[34]
Z. Hu, R. Wu, N. Enock, J. Li, R. Kadakia, Z. Erickson, and A. Kumar, “Rac: Robot learning for long-horizon tasks by scaling recovery and correction,”arXiv preprint arXiv:2509.07953, 2025
-
[35]
Y . Han, Z. Chen, Y . Zhao, C. Xu, Y . Shao, Y . Peng, Y . Mu, and W. Lian, “Dexhil: A human-in-the-loop framework for vision-language- action model post-training in dexterous manipulation,”arXiv preprint arXiv:2603.09121, 2026
-
[36]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huanget al., “Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,”arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
A humanoid visual-tactile-action dataset for contact-rich manipulation,
E. Kwon, S. Oh, I.-C. Baek, Y . Park, G. Kim, J. Moon, Y . Choi, and K.-J. Kim, “A humanoid visual-tactile-action dataset for contact-rich manipulation,” 2025
2025
-
[38]
Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” 2024
2024
-
[39]
Lemmo-plan: Llm-enhanced learning from multi-modal demonstration for planning sequential contact-rich manipulation tasks,
K. Chen, Z. Shen, Y . Zhang, L. Chen, F. Wu, Z. Bing, S. Haddadin, and A. Knoll, “Lemmo-plan: Llm-enhanced learning from multi-modal demonstration for planning sequential contact-rich manipulation tasks,” 2025
2025
-
[40]
GEN-0: Embodied foundation models that scale with physical interaction,
Generalist AI Team, “GEN-0: Embodied foundation models that scale with physical interaction,” https://generalistai.com/blog/ preview-uqlxvb-bb.html, 2025
2025
-
[41]
L. Wu, C. Yu, J. Ren, L. Chen, Y . Jiang, R. Huang, G. Gu, and H. Li, “Freetacman: Robot-free visuo-tactile data collection system for contact- rich manipulation,”arXiv preprint arXiv:2506.01941, 2025
-
[42]
Fastumi-100k: Advancing data-driven robotic manipulation with a large-scale umi-style dataset,
K. Liu, Z. Jia, Y . Li, Zhaxizhuoma, P. Chen, S. Liu, X. Liu, P. Zhang, H. Song, X. Ye, N. Cao, Z. Wang, J. Zeng, D. Wang, Y . Ding, B. Zhao, and X. Li, “Fastumi-100k: Advancing data-driven robotic manipulation with a large-scale umi-style dataset,” 2025
2025
-
[43]
Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,
X. Zhu, B. Huang, and Y . Li, “Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,” 2025
2025
-
[44]
Available: https://arxiv.org/abs/2601.09988
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song, “In-the-wild compliant manipulation with umi-ft,”arXiv preprint arXiv:2601.09988, 2026
-
[45]
T. Cheng, K. Chen, L. Chen, L. Zhang, Y . Zhang, Y . Ling, M. Hamad, Z. Bing, F. Wu, K. Sharmaet al., “Tacumi: A multi-modal uni- versal manipulation interface for contact-rich tasks,”arXiv preprint arXiv:2601.14550, 2026
-
[46]
MC-Tac: Modular camera-based tactile sensor for robot gripper,
J. Ren, J. Zou, and G. Gu, “MC-Tac: Modular camera-based tactile sensor for robot gripper,” inICIRA, 2023
2023
-
[47]
Omnivta: Visuo-tactile world modeling for contact- rich robotic manipulation, 2026
Y . Zheng, S. Gu, W. Li, Y . Zheng, Y . Zang, S. Tian, X. Li, C. Hao, C. Gao, S. Liu, H. Li, Y . Chen, S. Yan, and W. Ding, “Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation,”arXiv preprint arXiv:2603.19201, 2026
-
[48]
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Z. Zhang, J. Ma, X. Yang, X. Wen, Y . Zhang, B. Li, Y . Qin, J. Liu, C. Zhao, L. Kanget al., “Touchguide: Inference-time steering of visuo- motor policies via touch guidance,”arXiv preprint arXiv:2601.20239, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Vitamin: Learning contact-rich tasks through robot-free visuo-tactile manipulation interface,
F. Liu, C. Li, Y . Qin, J. Xu, P. Abbeel, and R. Chen, “Vitamin: Learning contact-rich tasks through robot-free visuo-tactile manipulation interface,” 2025
2025
-
[50]
exumi: Extensible robot teaching system with action-aware task-agnostic tactile representation, 2025
Y . Xu, L. Wei, P. An, Q. Zhang, and Y .-L. Li, “exumi: Extensible robot teaching system with action-aware task-agnostic tactile representation,” arXiv preprint arXiv:2509.14688, 2025
-
[51]
Force-Aware Residual DAgger via Trajectory Editing for Precision Insertion with Impedance Control
Y . Huang, M. Ning, W. Zhao, Z. Liu, J. Sun, Q. Wang, and Y . Chen, “Force-aware residual dagger via trajectory editing for precision insertion with impedance control,”arXiv preprint arXiv:2603.04038, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inAISTATS, 2011
2011
-
[53]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2024
2024
-
[54]
Learning from interventions,
J. Spencer, S. Choudhury, M. Barnes, M. Schmittle, M. Chiang, P. Ramadge, and S. Srinivasa, “Learning from interventions,” inRSS, 2020
2020
-
[55]
χ0: Resource-aware robust manipulation via taming distributional inconsistencies,
C. Yu, C. Sima, G. Jiang, H. Zhang, H. Mai, H. Li, H. Wang, J. Chen, K. Wu, L. Chen, L. Zhao, M. Shi, P. Luo, Q. Bu, S. Peng, T. Li, and Y . Yuan, “ χ0: Resource-aware robust manipulation via taming distributional inconsistencies,”arXiv preprint arXiv:2602.09021, 2026
-
[56]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel, “Robocopilot: Human-in-the-loop interactive imitation learning for robot manipulation,”arXiv preprint arXiv:2503.07771, 2025
-
[57]
Conrft: A reinforced fine-tuning method for vla models via consistency policy,
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” 2025
2025
-
[58]
Openmocap: Rethinking optical motion capture under real-world occlusion,
C. Qian, D. Li, X. Yu, Z. Yang, and Q. Ma, “Openmocap: Rethinking optical motion capture under real-world occlusion,”arXiv preprint arXiv:2508.12610, 2025
-
[59]
Rapid: Reconfigurable, adaptive platform for iterative design,
Z. Yin, F. Li, S. Zheng, and J. Liu, “Rapid: Reconfigurable, adaptive platform for iterative design,”arXiv preprint arXiv:2602.06653, 2026
-
[60]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRSS, 2023. 13 APPENDIX A. Hardware Design | Supplement to Sec. III-B in the Main paper. Manufacturing and assembly details.Figure 10 shows the exploded view of TAMEn. The structural components are fabricated using 3D printing, enabling ra...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.