Recognition: 1 theorem link
· Lean TheoremFedUTR: Federated Recommendation with Augmented Universal Textual Representation for Sparse Interaction Scenarios
Pith reviewed 2026-05-16 10:03 UTC · model grok-4.3
The pith
Item textual representations complement sparse interaction data to improve federated recommendation performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that augmenting federated recommenders with item textual representations as a universal complement to sparse interaction behaviors, fused via the Collaborative Information Fusion Module and adapted locally via the Local Adaptation Module, yields higher accuracy under high sparsity while preserving privacy and providing convergence guarantees.
What carries the argument
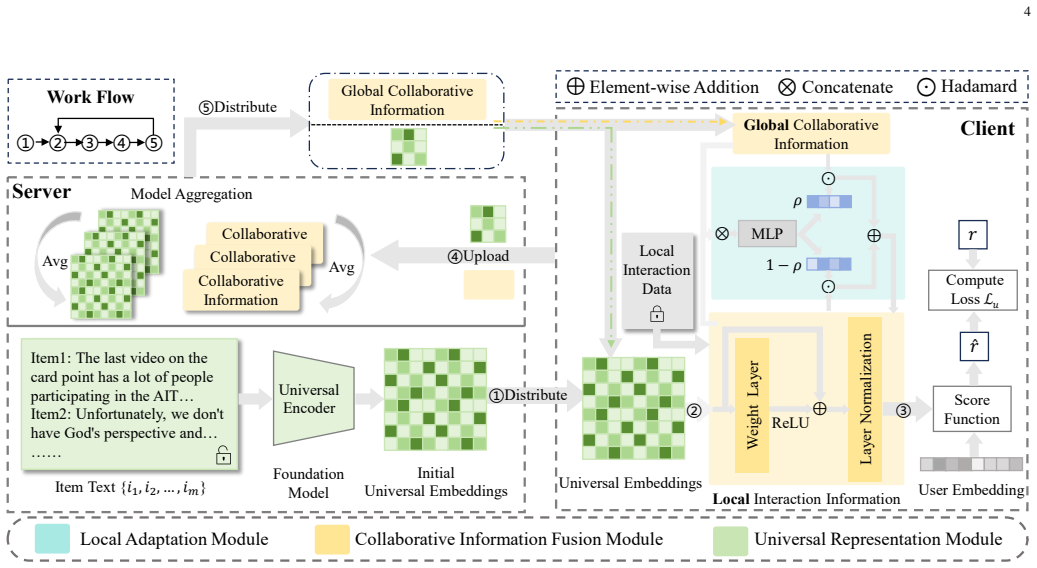
The Collaborative Information Fusion Module (CIFM) that merges universal textual item representations with personalized interaction signals, together with the Local Adaptation Module (LAM) that reuses the local model for client-specific preferences.
Load-bearing premise
Item textual descriptions supply generic knowledge that reliably supplements rather than contradicts users' sparse personal interaction histories.
What would settle it
Running the method on datasets where item text is noisy or contradicts observed user behavior and finding no accuracy gain or outright degradation would falsify the claim.
Figures





read the original abstract
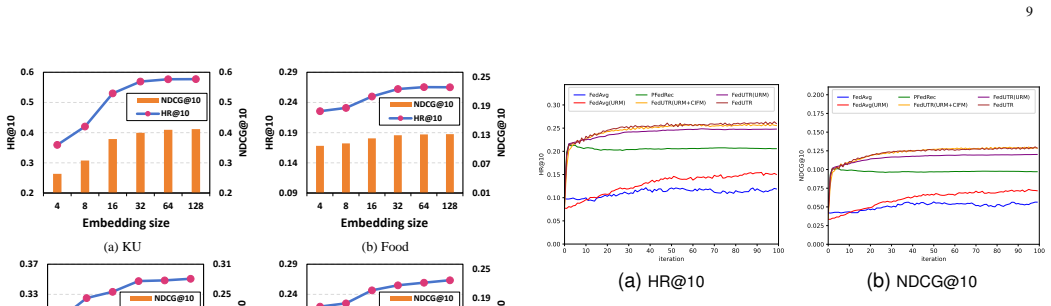
Federated recommendations (FRs) have emerged as an on-device privacy-preserving paradigm, attracting considerable attention driven by rising demands for data security. Existing FRs predominantly adapt ID embeddings to represent items, making the quality of item embeddings entirely dependent on users' historical behaviors. However, we empirically observe that this pattern leads to suboptimal recommendation performance under high data sparsity scenarios, due to its strong reliance on historical interactions. To address this issue, we propose a novel method named FedUTR, which incorporates item textual representations as a complement to interaction behaviors, aiming to enhance model performance under high data sparsity. Specifically, we utilize textual modality as the universal representation to capture generic item knowledge, and design a Collaborative Information Fusion Module (CIFM) to complement each user's personalized interaction information. Besides, we introduce a Local Adaptation Module (LAM) that adaptively exploits the off-the-shelf local model to efficiently preserve client-specific personalized preferences. Moreover, we propose a variant of FedUTR, termed FedUTR-SAR, which incorporates a sparsity-aware resnet component to granularly balance universal and personalized information. The convergence analysis proves theoretical guarantees for the effectiveness of FedUTR. Extensive experiments on four real-world datasets show that our method achieves superior performance, with improvements of up to 59% across all datasets compared to the SOTA baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedUTR, a federated recommendation method for sparse interaction scenarios that augments ID embeddings with universal textual item representations to capture generic knowledge. It introduces a Collaborative Information Fusion Module (CIFM) to complement personalized interactions and a Local Adaptation Module (LAM) to preserve client-specific preferences, along with a FedUTR-SAR variant using a sparsity-aware ResNet for balancing information types. The work includes a convergence analysis providing theoretical guarantees and reports up to 59% improvements over SOTA baselines on four real-world datasets.
Significance. If the empirical gains and convergence result hold under rigorous verification, the work would be significant for federated recommendation systems by demonstrating how textual modalities can mitigate sparsity without compromising privacy, extending multimodal techniques to on-device settings and potentially improving robustness in data-scarce environments.
major comments (2)
- [Abstract] Abstract: The claims of 'improvements of up to 59%' and a 'convergence analysis [that] proves theoretical guarantees' are load-bearing for the central contribution, yet the abstract (and summary) provides no details on experimental setup, baselines, metrics (e.g., Recall@K or NDCG), dataset statistics, or the specific assumptions and derivation steps in the proof, preventing assessment of whether the data support the claims.
- [Method] Method and Theoretical Analysis sections: The CIFM and LAM modules are presented as adaptively fusing textual and interaction data in a federated setting, but without explicit equations showing how the fusion avoids privacy leakage or performance degradation (the weakest assumption), it is unclear whether the modules introduce unstated hyperparameters that undermine the 'universal' claim.
minor comments (1)
- [Method] Ensure acronyms CIFM and LAM are expanded at first use and that notation for textual vs. ID embeddings is consistent across figures and text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below and have revised the manuscript to provide the requested clarifications and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'improvements of up to 59%' and a 'convergence analysis [that] proves theoretical guarantees' are load-bearing for the central contribution, yet the abstract (and summary) provides no details on experimental setup, baselines, metrics (e.g., Recall@K or NDCG), dataset statistics, or the specific assumptions and derivation steps in the proof, preventing assessment of whether the data support the claims.
Authors: We agree the abstract is concise and could better contextualize the claims. In the revised version we have expanded it to note the four real-world datasets (with sparsity statistics), evaluation metrics (Recall@K and NDCG@K), and SOTA federated baselines. For the convergence result we added a one-sentence summary of the main assumptions (Lipschitz-smooth local losses and bounded gradient variance) and proof outline. Full experimental tables and the complete derivation remain in Sections 4 and 5, as abstract length constraints preclude exhaustive detail. revision: partial
-
Referee: [Method] Method and Theoretical Analysis sections: The CIFM and LAM modules are presented as adaptively fusing textual and interaction data in a federated setting, but without explicit equations showing how the fusion avoids privacy leakage or performance degradation (the weakest assumption), it is unclear whether the modules introduce unstated hyperparameters that undermine the 'universal' claim.
Authors: We thank the referee for highlighting this clarity issue. The revised manuscript now includes explicit equations for CIFM (Eq. 3) and LAM (Eq. 5) that express the fusion as a locally computed convex combination of textual and interaction embeddings. All operations occur on-device; only the pre-trained textual embeddings (derived from a public language model) are shared, so no user interaction data leaves the client, preserving the federated privacy guarantee. The modules reuse existing model parameters and introduce no additional hyperparameters beyond those already listed in the experimental setup. We have added a short paragraph clarifying that the textual representations remain universal because they are not fine-tuned per client. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces FedUTR as an empirical augmentation to federated recommendation by incorporating pre-trained textual item representations via CIFM and LAM modules, plus a sparsity-aware variant and asserted convergence analysis. No equations, derivations, or load-bearing steps are exhibited that reduce claimed predictions or results to fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a manner that collapses the central argument to prior author work or tautological definitions. The approach relies on standard multimodal fusion practices and external dataset experiments, remaining self-contained without internal circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Textual modality serves as the universal representation to capture generic item knowledge
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 1–3 and Theorem 1 derive O(1/T) rate from L-smoothness, μ-strong convexity, bounded variance σ² and gradient G, extending FedAvg without altering the local update rule beyond proximal regularization and convex combination gating.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A multi-modal prompt-tuning framework for non-overlapping multi-domain recommendation,
L. Wang, S. Wang, Q. Wu, and M. Xu, “A multi-modal prompt-tuning framework for non-overlapping multi-domain recommendation,”IEEE TMM, vol. Early Access, pp. 1–10, 2025
work page 2025
-
[2]
The eu general data protection reg- ulation (gdpr),
P. V oigt and A. V on dem Bussche, “The eu general data protection reg- ulation (gdpr),”A practical guide, 1st ed., Cham: Springer International Publishing, vol. 10, pp. 10–5555, 2017
work page 2017
-
[3]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inAISTATS, 2017, pp. 1273–1282
work page 2017
-
[4]
Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System
M. Ammad-Ud-Din, E. Ivannikova, S. A. Khan, W. Oyomno, Q. Fu, K. E. Tan, and A. Flanagan, “Federated collaborative filtering for privacy-preserving personalized recommendation system,”arXiv preprint arXiv:1901.09888, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[5]
Federated multi-task attention for cross-individual human activity recognition,
Q. Shen, H. Feng, R. Song, S. Teso, F. Giunchiglia, H. Xuet al., “Federated multi-task attention for cross-individual human activity recognition,” inIJCAI, 2022, pp. 3423–3429
work page 2022
-
[6]
Prototype-decomposed knowledge distillation for learning generalized federated representation,
A. Wu, J. Yu, Y . Wang, and C. Deng, “Prototype-decomposed knowledge distillation for learning generalized federated representation,”IEEE TMM, vol. 26, pp. 10 991–11 002, 2024
work page 2024
-
[7]
Federated user pref- erence modeling for privacy-preserving cross-domain recommendation,
L. Wang, S. Wang, Q. Zhang, Q. Wu, and M. Xu, “Federated user pref- erence modeling for privacy-preserving cross-domain recommendation,” IEEE TMM, vol. 27, pp. 5324–5336, 2025
work page 2025
-
[8]
Lightfr: Lightweight federated recommendation with privacy-preserving matrix factorization,
H. Zhang, F. Luo, J. Wu, X. He, and Y . Li, “Lightfr: Lightweight federated recommendation with privacy-preserving matrix factorization,” ACM TOIS, vol. 41, pp. 1–28, 2023
work page 2023
-
[9]
Federated neural collaborative filter- ing,
V . Perifanis and P. S. Efraimidis, “Federated neural collaborative filter- ing,”KBS, vol. 242, p. 108441, 2022
work page 2022
-
[10]
Gpfe- drec: Graph-guided personalization for federated recommendation,
C. Zhang, G. Long, T. Zhou, Z. Zhang, P. Yan, and B. Yang, “Gpfe- drec: Graph-guided personalization for federated recommendation,” in SIGKDD, 2024, pp. 4131–4142
work page 2024
-
[11]
Federated recommendation with additive personalization,
Z. Li, G. Long, and T. Zhou, “Federated recommendation with additive personalization,” inICLR, 2024, pp. 11 770–11 787
work page 2024
-
[12]
Beyond similarity: Personalized federated recom- mendation with composite aggregation,
H. Zhang, H. Li, J. Chen, S. Cui, K. Yan, A. Wuerkaixi, X. Zhou, Z. Shen, and Y . Li, “Beyond similarity: Personalized federated recom- mendation with composite aggregation,”ACM TOIS, p. Just Accepted, 2025
work page 2025
-
[13]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inNAACL, 2019, pp. 4171–4186
work page 2019
-
[14]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML, 2021, pp. 8748–8763
work page 2021
-
[15]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Vbpr: visual bayesian personalized ranking from implicit feedback,
R. He and J. McAuley, “Vbpr: visual bayesian personalized ranking from implicit feedback,” inAAAI, 2016, pp. 144–150
work page 2016
-
[17]
Personalized item repre- sentations in federated multimodal recommendation,
Z. Li, G. Long, J. Jiang, and C. Zhang, “Personalized item repre- sentations in federated multimodal recommendation,”arXiv preprint arXiv:2410.08478, 2024
-
[18]
What makes training multi-modal classification networks hard?
W. Wang, D. Tran, and M. Feiszli, “What makes training multi-modal classification networks hard?” inCVPR, 2020, pp. 12 695–12 705
work page 2020
-
[19]
Ninerec: A benchmark dataset suite for evaluating transferable recommendation,
J. Zhang, Y . Cheng, Y . Ni, Y . Pan, Z. Yuan, J. Fu, Y . Li, J. Wang, and F. Yuan, “Ninerec: A benchmark dataset suite for evaluating transferable recommendation,”IEEE TPAMI, vol. 47, pp. 5256–5267, 2024
work page 2024
-
[20]
Federated causally invariant feature learning,
X. Guo, K. Yu, L. Cui, H. Yu, and X. Li, “Federated causally invariant feature learning,” inAAAI, 2025, pp. 16 978–16 986
work page 2025
-
[21]
Neural collaborative filtering,
X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua, “Neural collaborative filtering,” inWWW, 2017, pp. 173–182
work page 2017
-
[22]
Dual personalization on federated recommendation,
C. Zhang, G. Long, T. Zhou, P. Yan, Z. Zhang, C. Zhang, and B. Yang, “Dual personalization on federated recommendation,” inIJCAI, 2023, pp. 4558–4566
work page 2023
-
[23]
Fedfast: Going beyond average for faster training of federated recommender systems,
K. Muhammad, Q. Wang, D. O’Reilly-Morgan, E. Tragos, B. Smyth, N. Hurley, J. Geraci, and A. Lawlor, “Fedfast: Going beyond average for faster training of federated recommender systems,” inSIGKDD, 2020, pp. 1234–1242
work page 2020
-
[24]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[26]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,” inNeurIPS, 2020, pp. 1877–1901
work page 2020
-
[27]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
On the convergence of fedavg on non-iid data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-iid data,” inICLR, 2020
work page 2020
-
[29]
Bootstrap latent representations for multi-modal recommen- dation,
X. Zhou, H. Zhou, Y . Liu, Z. Zeng, C. Miao, P. Wang, Y . You, and F. Jiang, “Bootstrap latent representations for multi-modal recommen- dation,” inWWW, 2023, pp. 845–854
work page 2023
-
[30]
Multi-view graph convolutional network for multimedia recommendation,
P. Yu, Z. Tan, G. Lu, and B.-K. Bao, “Multi-view graph convolutional network for multimedia recommendation,” inMM, 2023, pp. 6576–6585
work page 2023
-
[31]
Learning private neural language modeling with attentive aggregation,
S. Ji, S. Pan, G. Long, X. Li, J. Jiang, and Z. Huang, “Learning private neural language modeling with attentive aggregation,” inIJCNN, 2019, pp. 1–8
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.