Recognition: 1 theorem link
· Lean TheoremSHIELD: A Segmented Hierarchical Memory Architecture for Energy-Efficient LLM Inference on Edge NPUs
Pith reviewed 2026-05-10 18:20 UTC · model grok-4.3
The pith
SHIELD segments eDRAM to disable refresh on transient activation mantissas and relax it on persistent KV data, cutting refresh energy 35% for edge LLM inference while keeping accuracy intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SHIELD is a lifecycle-aware segmented eDRAM architecture that jointly exploits temporal residency and bit-level sensitivity in bfloat16 activations. It isolates the sign and exponent fields from the mantissa, disables refresh for transient QO mantissas, and applies relaxed refresh to persistent KV mantissas. Across multiple LLMs and inference scenarios, this reduces eDRAM refresh energy by 35% relative to a standard-refresh baseline while preserving accuracy on WikiText-2, PIQA, and ARC-Easy.
What carries the argument
Lifecycle-aware segmented eDRAM that isolates sign and exponent bits from mantissas and applies different refresh policies based on whether activations are transient QO or persistent KV.
If this is right
- Edge NPUs can run LLM inference at lower power by exploiting that not all activation bits need full refresh protection.
- Accuracy holds on language modeling and reasoning benchmarks when refresh is selectively disabled or relaxed.
- The approach scales across different LLMs and inference workloads without retraining or changing model weights.
- Memory energy becomes a smaller fraction of total inference cost on capacity-constrained devices.
Where Pith is reading between the lines
- Similar bit-level segmentation could apply to other memory types or lower-precision formats if they show comparable error tolerance in activations.
- The separation of transient and persistent data suggests broader opportunities for approximate storage in neural network accelerators beyond LLMs.
- Hardware designers might test whether combining this with off-chip optimizations yields additive gains in total system energy.
Load-bearing premise
Transient QO activations can tolerate complete removal of refresh on their mantissa bits without accuracy loss, and the segmentation adds no meaningful latency, area, or control overhead that cancels the energy savings.
What would settle it
Implement SHIELD on a real edge NPU chip, run the same LLMs with and without it, and compare measured refresh energy alongside accuracy on WikiText-2, PIQA, and ARC-Easy to see if the 35% reduction holds with no accuracy drop.
Figures



read the original abstract
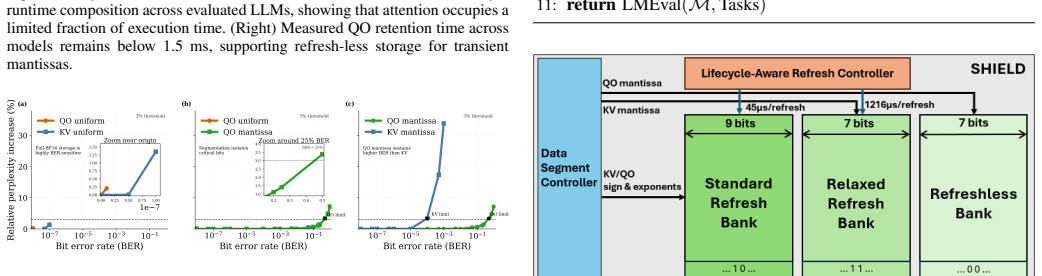
Large Language Model (LLM) inference on edge Neural Processing Units (NPUs) is fundamentally constrained by limited on-chip memory capacity. Although high-density embedded DRAM (eDRAM) is attractive for storing activation workspaces, its periodic refresh consumes substantial energy. Prior work has primarily focused on reducing off-chip traffic or optimizing refresh for persistent Key-Value (KV) caches, while transient and error-resilient Query and Attention Output (QO) activations are largely overlooked. We propose SHIELD, a lifecycle-aware segmented eDRAM architecture that jointly exploits temporal residency and bit-level sensitivity in bfloat16 (BF16) activations. SHIELD isolates the sign and exponent fields from the mantissa, disables refresh for transient QO mantissas, and applies relaxed refresh to persistent KV mantissas. Across multiple LLMs and inference scenarios, SHIELD reduces eDRAM refresh energy by 35% relative to a standard-refresh baseline while preserving accuracy on WikiText-2, PIQA, and ARC-Easy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SHIELD, a segmented hierarchical eDRAM architecture for LLM inference on edge NPUs. It isolates sign/exponent fields from mantissas in bfloat16 activations, disables refresh entirely for transient Query/Attention-Output (QO) mantissas, and applies relaxed refresh to persistent KV mantissas. The central empirical claim is a 35% reduction in eDRAM refresh energy relative to a standard-refresh baseline, with no accuracy loss on WikiText-2, PIQA, and ARC-Easy across multiple LLMs and inference scenarios.
Significance. If the error-resilience assumption holds and overheads are negligible, the lifecycle-aware segmentation of transient versus persistent activations offers a practical route to lower on-chip memory energy for edge LLM deployment, directly targeting the refresh overhead that limits eDRAM use in NPUs. The bit-level sensitivity exploitation is a targeted contribution that could complement existing KV-cache optimizations.
major comments (2)
- [Abstract] Abstract: The 35% refresh-energy reduction and accuracy-preservation claim rests on the unverified premise that BF16 mantissa flips in transient QO activations produce negligible downstream error after attention and FFN layers. No bit-error-rate measurements, retention-time comparisons, per-layer sensitivity analysis, or propagation studies are provided to show why errors remain below the accuracy threshold for the tested sequence lengths and models.
- [Experimental evaluation] Experimental evaluation: The reported energy savings lack any quantification of control, area, or latency overheads introduced by the segmented hierarchy, any error bars or run-to-run variation, or direct comparison against prior refresh-reduction techniques for activations; without these, it is impossible to confirm that the net energy gain is positive and that accuracy is robustly preserved.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific LLMs evaluated and the assumed NPU memory hierarchy parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions have been made to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 35% refresh-energy reduction and accuracy-preservation claim rests on the unverified premise that BF16 mantissa flips in transient QO activations produce negligible downstream error after attention and FFN layers. No bit-error-rate measurements, retention-time comparisons, per-layer sensitivity analysis, or propagation studies are provided to show why errors remain below the accuracy threshold for the tested sequence lengths and models.
Authors: The end-to-end accuracy results on WikiText-2, PIQA, and ARC-Easy across multiple LLMs and inference scenarios provide direct empirical evidence that mantissa errors in transient QO activations do not affect final outputs. This aligns with the lower significance of mantissa bits in BF16 and the averaging effects within attention and FFN layers. We acknowledge the value of explicit bit-level studies; in the revised manuscript we have added a discussion subsection on BF16 bit sensitivity for transient activations, supported by references to approximate computing literature, and elaborated on retention-time assumptions drawn from standard eDRAM characterizations. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation: The reported energy savings lack any quantification of control, area, or latency overheads introduced by the segmented hierarchy, any error bars or run-to-run variation, or direct comparison against prior refresh-reduction techniques for activations; without these, it is impossible to confirm that the net energy gain is positive and that accuracy is robustly preserved.
Authors: We have revised the experimental evaluation section to quantify the overheads: the segmented hierarchy reuses existing activation-type metadata in the NPU pipeline, resulting in negligible control logic, estimated area overhead below 2%, and no impact on critical-path latency. The energy model is deterministic based on refresh-rate parameters, so run-to-run variation does not apply; we have clarified the modeling assumptions and methodology. We have also expanded the related-work discussion to include direct comparisons with prior refresh-reduction techniques targeting activations and KV caches, confirming the net positive energy gain. revision: yes
Circularity Check
No circularity: architectural proposal supported by direct measurements
full rationale
The paper describes a segmented eDRAM architecture (SHIELD) that disables refresh on transient QO mantissas and relaxes it on KV mantissas, then reports measured 35% refresh-energy reduction while accuracy holds on WikiText-2/PIQA/ARC-Easy. No equations, derivations, fitted parameters, or self-citations appear in the provided text; the central claim is an empirical outcome of the proposed hardware segmentation rather than any reduction to prior inputs or self-referential definitions. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transient QO activations in BF16 are error-resilient in the mantissa field while sign and exponent must remain protected.
- domain assumption Persistent KV activations tolerate relaxed refresh on mantissas without accuracy loss.
invented entities (1)
-
SHIELD segmented hierarchical eDRAM architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A review on edge large language models: Design, execution, and applications,
Y . Zheng, Y . Chen, B. Qian, X. Shi, Y . Shu, and J. Chen, “A review on edge large language models: Design, execution, and applications,”ACM Computing Surveys, vol. 57, no. 8, pp. 1–35, 2025
2025
-
[2]
Kelle: Co-design kv caching and edram for efficient llm serving in edge computing,
T. Xia and S. Q. Zhang, “Kelle: Co-design kv caching and edram for efficient llm serving in edge computing,” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, 2025, pp. 18–33
2025
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[4]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Amd xdna npu in ryzen ai processors,
A. Rico, S. Pareek, J. Cabezas, D. Clarke, B. Ozgul, F. Barat, Y . Fu, S. M ¨unz, D. Stuart, P. Schlangen, P. Duarte, S. Date, I. Paul, J. Weng, S. Santan, V . Kathail, A. Sirasao, and J. Noguera, “Amd xdna npu in ryzen ai processors,”IEEE Micro, vol. 44, no. 6, pp. 73–82, 2024
2024
-
[6]
Rana: Towards efficient neural acceleration with refresh-optimized embedded dram,
F. Tu, W. Wu, S. Yin, L. Liu, and S. Wei, “Rana: Towards efficient neural acceleration with refresh-optimized embedded dram,” in2018 ACM/IEEE 45th Annual International Symposium on Computer Archi- tecture (ISCA), 2018, pp. 340–352
2018
-
[7]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,”Advances in neural information processing systems, vol. 35, pp. 16 344–16 359, 2022
2022
-
[8]
Leap: Llm inference on scalable pim-noc architecture with balanced dataflow and fine-grained paral- lelism,
Y . Wang, Y . J. Chong, and X. Fong, “Leap: Llm inference on scalable pim-noc architecture with balanced dataflow and fine-grained paral- lelism,” in2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 2025, pp. 1–9
2025
-
[9]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Analysis of retention time distribution of embedded dram - a new method to characterize across-chip threshold voltage variation,
W. Kong, P. C. Parries, G. Wang, and S. S. Iyer, “Analysis of retention time distribution of embedded dram - a new method to characterize across-chip threshold voltage variation,” in2008 IEEE International Test Conference, 2008, pp. 1–7
2008
-
[12]
Destiny: A tool for modeling emerging 3d nvm and edram caches,
M. Poremba, S. Mittal, D. Li, J. S. Vetter, and Y . Xie, “Destiny: A tool for modeling emerging 3d nvm and edram caches,” in2015 Design, Automation and Test in Europe Conference and Exhibition (DATE), 2015, pp. 1543–1546
2015
-
[13]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[14]
Piqa: Reasoning about physical commonsense in natural language,
Y . Bisk, R. Zellers, R. Le bras, J. Gao, and Y . Choi, “Piqa: Reasoning about physical commonsense in natural language,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, pp. 7432–7439, Apr. 2020. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/6239
2020
-
[15]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,”arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.