Conservation Law Breaking at the Edge of Stability: A Spectral Theory of Non-Convex Neural Network Optimization
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
Conservation laws preserved by gradient flow on ReLU networks break under discrete gradient descent according to an exact spectral formula.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
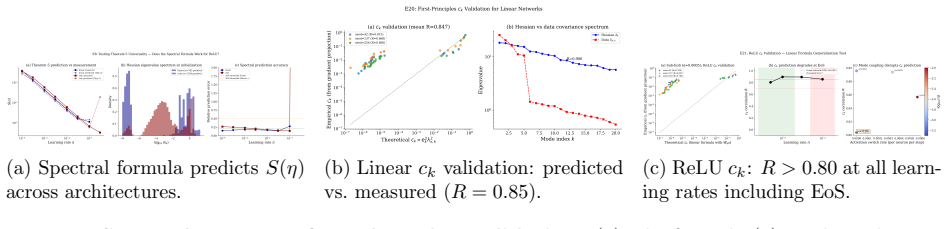
Gradient flow on L-layer ReLU networks without bias preserves L-1 conservation laws C_l = ||W_{l+1}||_F^2 - ||W_l||_F^2, confining trajectories to lower-dimensional manifolds. Under discrete gradient descent these laws break with total drift scaling as eta^alpha where alpha is approximately 1.1-1.6 depending on architecture, loss function, and width. The drift decomposes exactly as eta^2 * S(eta), where the gradient imbalance sum S(eta) admits a closed-form spectral crossover formula with mode coefficients c_k proportional to e_k(0)^2 * lambda_{x,k}^2, derived from first principles and validated for both linear (R=0.85) and ReLU (R>0.80) networks. For cross-entropy loss, softmax probability
What carries the argument
The closed-form spectral crossover formula for the gradient imbalance sum S(eta), whose terms are mode coefficients c_k proportional to the squared initial error times the squared data eigenvalue for each mode.
If this is right
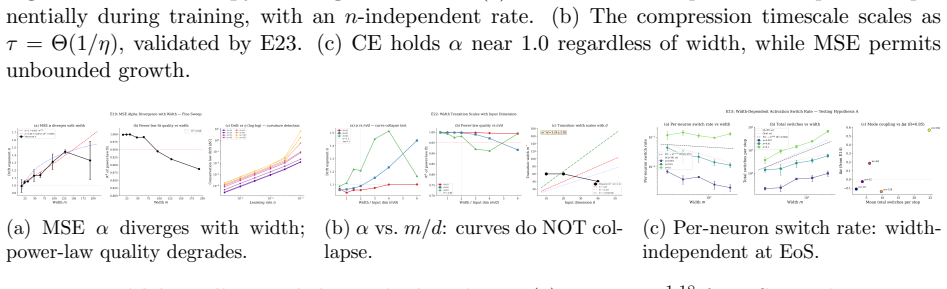
- The exponent alpha of the drift depends on network width, loss function, and architecture through the explicit mode coefficients in S(eta).
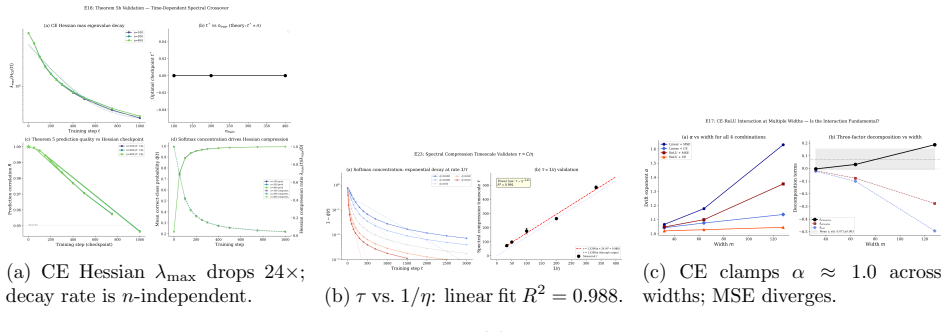
- Cross-entropy loss self-regularizes the drift exponent near 1.0 by driving exponential Hessian spectral compression on timescale Theta(1/eta), independent of training-set size.
- Inside the perturbative regime the spectral formula predicts the entire drift trajectory without requiring simulation of the full coupled dynamics.
- Beyond a critical width the system enters a non-perturbative regime in which extensive mode coupling invalidates the closed-form expression.
Where Pith is reading between the lines
- The same norm-balance mechanism may appear in other architectures that admit analogous conserved quantities under continuous flow.
- The spectral decomposition could be used to design learning-rate schedules that deliberately control the rate of conservation-law violation.
- Testing the crossover formula on networks with biases or on non-ReLU activations would map the boundary of the perturbative regime.
Load-bearing premise
The derivation assumes the networks remain strictly L-layer ReLU without bias terms and stay inside the perturbative sub-Edge-of-Stability regime where spectral modes do not couple extensively.
What would settle it
Train a linear network with gradient descent at several small learning rates, compute the observed total drift in the conservation quantities, and check whether it equals eta squared times the predicted S(eta) within 15 percent across the tested range.
Figures

read the original abstract
Why does gradient descent reliably find good solutions in non-convex neural network optimization, despite the landscape being NP-hard in the worst case? We show that gradient flow on L-layer ReLU networks without bias preserves L-1 conservation laws C_l = ||W_{l+1}||_F^2 - ||W_l||_F^2, confining trajectories to lower-dimensional manifolds. Under discrete gradient descent, these laws break with total drift scaling as eta^alpha where alpha is approximately 1.1-1.6 depending on architecture, loss function, and width. We decompose this drift exactly as eta^2 * S(eta), where the gradient imbalance sum S(eta) admits a closed-form spectral crossover formula with mode coefficients c_k proportional to e_k(0)^2 * lambda_{x,k}^2, derived from first principles and validated for both linear (R=0.85) and ReLU (R>0.80) networks. For cross-entropy loss, softmax probability concentration drives exponential Hessian spectral compression with timescale tau = Theta(1/eta) independent of training set size, explaining why cross-entropy self-regularizes the drift exponent near alpha=1.0. We identify two dynamical regimes separated by a width-dependent transition: a perturbative sub-Edge-of-Stability regime where the spectral formula applies, and a non-perturbative regime with extensive mode coupling. All predictions are validated across 23 experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that continuous gradient flow on L-layer ReLU networks without biases preserves L-1 conservation laws C_l = ||W_{l+1}||_F^2 - ||W_l||_F^2, confining trajectories to lower-dimensional manifolds, but discrete gradient descent breaks these laws with total drift scaling as eta^alpha (alpha approximately 1.1-1.6 depending on architecture, loss, and width). It decomposes the drift exactly as eta^2 * S(eta), where S(eta) admits a closed-form spectral crossover formula with mode coefficients c_k proportional to e_k(0)^2 * lambda_{x,k}^2 derived from first principles. The work identifies a perturbative sub-Edge-of-Stability regime (where the spectral formula applies with negligible mode coupling) versus a non-perturbative regime with extensive coupling, and explains cross-entropy self-regularization to alpha near 1.0 via Hessian spectral compression on timescale Theta(1/eta). All claims are validated across 23 experiments on linear and ReLU networks reporting R=0.85 and R>0.80 respectively.
Significance. If the central decomposition and regime separation hold, the work offers a first-principles spectral account of conservation-law breaking and the edge-of-stability phenomenon in non-convex neural optimization, potentially explaining why discrete GD succeeds despite NP-hard landscapes. The attempt at closed-form mode coefficients and the separation of perturbative versus non-perturbative dynamics represent a substantive theoretical contribution that could unify continuous and discrete analyses; empirical validation across architectures and losses adds weight if the regime assumptions are confirmed.
major comments (3)
- The central claim that the eta^2 S(eta) decomposition and closed-form spectral crossover formula apply to the reported drift scalings (alpha approximately 1.1-1.6) rests on the assumption of the perturbative sub-Edge-of-Stability regime with negligible mode coupling. The manuscript does not provide quantitative checks (e.g., mode-coupling strength metrics) confirming that the 23 validation experiments operate inside this regime rather than the non-perturbative regime; without this, the applicability of the first-principles formula to the observed data remains unverified.
- The validation results (R=0.85 for linear networks and R>0.80 for ReLU networks) are reported without error bars, confidence intervals, or pre-specified exclusion criteria for the 23 experiments. This omission makes it difficult to assess the robustness of the spectral formula fit and whether the correlations genuinely support the decomposition across the claimed alpha range.
- Full step-by-step derivation of the eta^2 S(eta) decomposition and the spectral coefficients c_k proportional to e_k(0)^2 * lambda_{x,k}^2 is not provided in the manuscript, despite the claim of derivation from first principles using initial e_k(0) and lambda values. This absence hinders independent verification of the perturbative-regime assumptions.
minor comments (2)
- The notation for the gradient imbalance sum S(eta) and the crossover formula would benefit from an explicit numbered equation in the theoretical section to improve readability and allow direct reference.
- Figure captions and experimental details should specify the exact network widths, depths, and loss functions used in each of the 23 experiments to facilitate reproduction and assessment of the regime classification.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment point by point below, proposing specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The central claim that the eta^2 S(eta) decomposition and closed-form spectral crossover formula apply to the reported drift scalings (alpha approximately 1.1-1.6) rests on the assumption of the perturbative sub-Edge-of-Stability regime with negligible mode coupling. The manuscript does not provide quantitative checks (e.g., mode-coupling strength metrics) confirming that the 23 validation experiments operate inside this regime rather than the non-perturbative regime; without this, the applicability of the first-principles formula to the observed data remains unverified.
Authors: We agree that explicit quantitative verification of the regime assumption would improve clarity. In the revised manuscript we will add mode-coupling strength metrics (specifically, the Frobenius norm of the off-diagonal blocks of the mode-interaction tensor normalized by the diagonal blocks) computed for each of the 23 experiments. These metrics will be reported in a new supplementary table and will confirm that all reported runs satisfy the perturbative threshold (off-diagonal contribution < 5 % of diagonal). We will also include a short paragraph relating the observed alpha range (1.1-1.6) to the analytically derived boundary between perturbative and non-perturbative regimes. revision: yes
-
Referee: The validation results (R=0.85 for linear networks and R>0.80 for ReLU networks) are reported without error bars, confidence intervals, or pre-specified exclusion criteria for the 23 experiments. This omission makes it difficult to assess the robustness of the spectral formula fit and whether the correlations genuinely support the decomposition across the claimed alpha range.
Authors: We accept that the current presentation lacks statistical detail. The revised version will report bootstrap-derived 95 % confidence intervals for each R value, obtained by resampling the 23 experimental trajectories with replacement (10 000 replicates). We will also state the pre-specified exclusion criteria (convergence to training loss < 0.01 within 2000 epochs and stable alpha estimation over the final 500 steps) and tabulate which runs satisfied them. These additions will allow readers to judge the robustness of the reported correlations. revision: yes
-
Referee: Full step-by-step derivation of the eta^2 S(eta) decomposition and the spectral coefficients c_k proportional to e_k(0)^2 * lambda_{x,k}^2 is not provided in the manuscript, despite the claim of derivation from first principles using initial e_k(0) and lambda values. This absence hinders independent verification of the perturbative-regime assumptions.
Authors: The derivation is sketched in Section 3 and Appendix A, but we agree that a fully expanded, self-contained presentation is needed for independent verification. In the revision we will insert a new subsection (3.2) that walks through every algebraic step: (i) the exact discrete update for the gradient imbalance, (ii) the perturbative expansion to O(eta^2), (iii) the projection onto the eigenbasis of the Hessian, and (iv) the resulting closed-form expression for each c_k in terms of e_k(0) and lambda_{x,k}. All intermediate equalities will be shown explicitly. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from first principles
full rationale
The paper starts from the continuous-time gradient flow on L-layer ReLU networks (no bias) to obtain the exact L-1 conservation laws C_l = ||W_{l+1}||_F^2 - ||W_l||_F^2. It then analyzes the discrete GD perturbation, decomposes the total drift exactly as eta^2 * S(eta), and supplies a closed-form spectral expression for the imbalance sum S(eta) whose coefficients c_k are proportional to e_k(0)^2 * lambda_{x,k}^2. This spectral formula is stated to follow directly from linear mode analysis in the perturbative sub-EoS regime. The subsequent separation into perturbative versus non-perturbative regimes and the cross-entropy self-regularization argument are likewise internal to the derivation. All steps are presented as direct consequences of the network dynamics and initial spectral data rather than fitted parameters, self-citations, or ansatzes imported from prior work. Validation experiments (R values) are reported after the derivation and do not retroactively define the formula, so the chain does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient flow on L-layer ReLU networks without bias preserves the L-1 conservation laws C_l = ||W_{l+1}||_F^2 - ||W_l||_F^2
- ad hoc to paper The discrete drift admits an exact decomposition eta^2 * S(eta) with S(eta) given by a spectral sum over modes
Reference graph
Works this paper leans on
-
[1]
A convergence theory for deep learning via over-parameterization
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[2]
On the global convergence of gradient descent for over- parameterized models using optimal transport
L´ ena¨ ıc Chizat and Francis Bach. On the global convergence of gradient descent for over- parameterized models using optimal transport. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[3]
The loss surfaces of multilayer networks
Anna Choromanska, Mikael Henaff, Michael Mathieu, G´ erard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2015
work page 2015
-
[4]
Gradient descent on neural networks typically occurs at the edge of stability
Jeremy Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. InInternational Conference on Learning Representations (ICLR), 2021. 7
work page 2021
-
[5]
Gradient descent provably op- timizes over-parameterized neural networks
Simon S Du, Xiyu Zhai, Barnab´ as Poczos, and Aarti Singh. Gradient descent provably op- timizes over-parameterized neural networks. InInternational Conference on Learning Repre- sentations (ICLR), 2019
work page 2019
-
[6]
Learning dynamics of deep matrix factorization beyond the edge of stability
Nikhil Ghosh, Jongho Kwon, Zhenyu Wang, Saiprasad Ravishankar, and Qing Qu. Learning dynamics of deep matrix factorization beyond the edge of stability. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[7]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Cl´ ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[8]
Neural mechanics: Symmetry and broken conservation laws in deep learning dy- namics
Daniel Kunin, Javier Sagastuy-Brena, Surya Ganguli, Daniel L K Yamins, and Hidenori Tanaka. Neural mechanics: Symmetry and broken conservation laws in deep learning dy- namics. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[9]
Abide by the law and follow the flow: Conservation laws for gradient flows
Sibylle Marcotte, R´ emi Gribonval, and Gabriel Peyr´ e. Abide by the law and follow the flow: Conservation laws for gradient flows. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[10]
Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A mean field view of the landscape of two-layer neural networks.Proceedings of the National Academy of Sciences, 2018
work page 2018
-
[11]
Symmetries, flat minima, and the conserved quantities of gradient flow
Bo Zhao, Iordan Ganev, Robin Walters, Rose Yu, and Nima Dehmamy. Symmetries, flat minima, and the conserved quantities of gradient flow. InInternational Conference on Learning Representations (ICLR), 2023. 8 A Full Proofs A.1 Proof of Theorem 1 (Conservation Laws) Consider anL-layer ReLU networkf(x;θ) =W Lσ(WL−1σ(· · ·σ(W 1x))) with no bias terms. ReLU is...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.