Recognition: no theorem link
ASTRAFier: A Novel and Scalable Transformer-based Stellar Variability Classifier
Pith reviewed 2026-05-10 17:07 UTC · model grok-4.3
The pith
ASTRAFier classifies stellar variability types directly from light curves using a hybrid Transformer model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
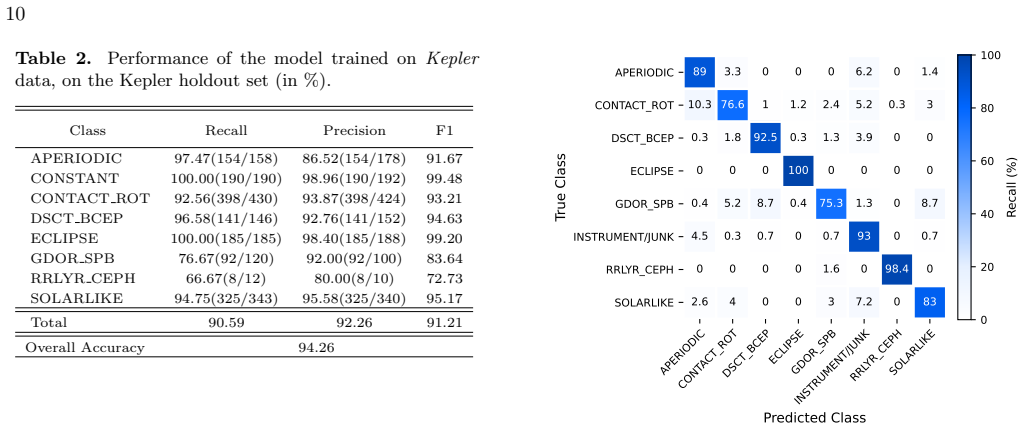
ASTRAFier integrates Transformer, BiLSTM, and CNN components into a single model that classifies stellar variability classes from raw time series light curves, achieving 94.26 percent accuracy on Kepler data and 88.22 percent on TESS data while scaling to process approximately 2.8 million TESS observations and release the resulting catalog.
What carries the argument
The ASTRAFier architecture, which fuses Transformer attention mechanisms with bidirectional LSTM for long-range sequence dependencies and CNN layers for local feature detection to enable direct end-to-end classification from light curve time series.
If this is right
- Large photometric datasets can be classified without the time-consuming step of manual feature engineering.
- New catalogs of stellar variability become feasible to produce at the scale of millions of light curves.
- The framework supports ongoing updates as additional TESS sectors or future survey data arrive.
Where Pith is reading between the lines
- The same architecture could be retrained on combined data from multiple surveys to reduce instrument-specific biases in variability labels.
- Population-level statistics derived from the released catalog might reveal previously hidden trends in the occurrence rates of different variability types.
- Similar hybrid models could be tested on other time-domain astronomy tasks such as transient detection or exoplanet signal identification.
Load-bearing premise
The labels used to train and validate the model accurately represent distinct stellar variability classes and the model generalizes to new TESS data without large instrument-specific biases or overfitting.
What would settle it
A comparison of ASTRAFier outputs against independently verified variability labels on a held-out sample of several thousand TESS light curves would directly test whether the reported accuracies are reproducible.
Figures












read the original abstract
Photometric missions such as Kepler and TESS have generated millions of light curves covering almost the entire sky, offering unprecedented opportunities to study stellar variability and advance our understanding of the Universe. In this data-rich environment, machine learning has emerged as a powerful tool to efficiently and accurately process and classify light curves according to their type of stellar variability. In this work, we introduce ASTRAFier: a novel Transformer-based model for variability classification that integrates Bidirectional Long Short-Term Memory (BiLSTM) and Convolutional Neural Networks (CNNs). The model operates directly on time series without requiring feature engineering, creating an easy-to-maintain and efficient end-to-end classification framework. We train and validate our model using both Kepler and TESS light curves and, respectively, achieve a classification accuracy of $94.26\%$ on Kepler and $88.22\%$ on TESS. We demonstrate scalability by deploying our model on $\sim 2.8$ million TESS light curves from sectors 14, 15, and 26 (Kepler Field-of-View) delivered by MIT's Quick-look Pipeline (QLP) and release the resulting stellar variability catalog.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ASTRAFier, a Transformer-based model that integrates BiLSTM and CNN components to classify stellar variability directly from Kepler and TESS photometric time series without feature engineering. It reports classification accuracies of 94.26% on Kepler data and 88.22% on TESS data, demonstrates scalability by applying the model to approximately 2.8 million TESS light curves from sectors 14, 15, and 26, and releases the resulting stellar variability catalog.
Significance. If the performance claims are supported by rigorous validation, the end-to-end framework could offer a maintainable approach for processing large photometric datasets from ongoing and future surveys. The public release of the catalog derived from 2.8 million light curves constitutes a concrete community resource that strengthens the work's potential utility.
major comments (2)
- [Abstract] Abstract: The stated accuracies (94.26% Kepler, 88.22% TESS) are presented without any information on dataset splits, class balance, cross-validation strategy, preprocessing, or error analysis. These omissions directly affect evaluation of the central performance claims.
- [Results/Deployment] Deployment and results sections: The application to ~2.8 million TESS light curves assumes cross-instrument generalization, yet no cross-mission hold-out experiments, label-source audits, or ablation studies addressing domain shift (differences in cadence, noise, and precision between Kepler and TESS) are described.
minor comments (2)
- [Abstract/Methods] The abstract and methods would benefit from an explicit architectural diagram or pseudocode clarifying how the Transformer, BiLSTM, and CNN components are combined.
- [Introduction] Ensure consistent definition of acronyms (BiLSTM, CNN, QLP) on first use and provide a brief comparison to prior ML classifiers for stellar variability in the introduction.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments, which help strengthen the manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The stated accuracies (94.26% Kepler, 88.22% TESS) are presented without any information on dataset splits, class balance, cross-validation strategy, preprocessing, or error analysis. These omissions directly affect evaluation of the central performance claims.
Authors: We agree that the abstract, constrained by length, omits these methodological details. The full manuscript describes the data preparation in the Methods section, including an 80/10/10 train/validation/test split, handling of class imbalance via weighted loss, 5-fold cross-validation, preprocessing (normalization, gap-filling, and sigma-clipping), and error analysis (overall accuracy plus per-class precision/recall and confusion matrices). To improve accessibility without exceeding abstract limits, we will revise the abstract to include a concise statement on the validation strategy and dataset characteristics. revision: yes
-
Referee: [Results/Deployment] Deployment and results sections: The application to ~2.8 million TESS light curves assumes cross-instrument generalization, yet no cross-mission hold-out experiments, label-source audits, or ablation studies addressing domain shift (differences in cadence, noise, and precision between Kepler and TESS) are described.
Authors: The model was trained and validated on light curves from both missions, with the separate TESS accuracy of 88.22% providing direct evidence of performance on TESS data. We acknowledge that explicit cross-mission hold-out experiments and dedicated domain-shift ablations are not included. In the revised manuscript we will add a dedicated subsection in the Results discussing potential domain differences (cadence, noise properties) and include an ablation comparing Kepler-only versus combined training. Label sources are the standard Kepler and TESS variability catalogs, which we will explicitly audit and document. revision: yes
Circularity Check
No circularity: standard supervised ML on external labeled data
full rationale
The paper describes training and validating a Transformer+BiLSTM+CNN classifier on Kepler and TESS light-curve datasets with pre-existing labels, then deploying the trained model on a larger TESS sample. Reported accuracies (94.26% Kepler, 88.22% TESS) are empirical test-set performance metrics obtained after supervised optimization; they are not obtained by fitting a parameter to the output quantity itself, nor by any self-referential equation, ansatz smuggled via citation, or uniqueness theorem. No load-bearing self-citations, self-definitional steps, or renaming of known results appear in the abstract or described workflow. The derivation chain is the conventional ML pipeline (data ingestion → model training → evaluation → inference) and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and hyperparameters
axioms (1)
- domain assumption Labeled light curves from Kepler and TESS missions represent distinct and learnable classes of stellar variability
Forward citations
Cited by 1 Pith paper
-
Variability classification of TESS targets in LOPS2, the first long-term pointing field of PLATO. Version 1 of the public variability catalogue
Machine learning classification of TESS data for 6 million stars in the LOPS2 field identifies 28% as candidate variables after filtering out 72% instrumental signals, producing one of the largest automated variabilit...
Reference graph
Works this paper leans on
-
[1]
2021, Reviews of Modern Physics, 93, 015001, doi: 10.1103/RevModPhys.93.015001
Aerts, C. 2021, Reviews of Modern Physics, 93, 015001, doi: 10.1103/RevModPhys.93.015001
-
[2]
Aerts, C., Christensen-Dalsgaard, J., & Kurtz, D. W. 2010, Asteroseismology, doi: 10.1007/978-1-4020-5803-5
-
[3]
2024, Astronomy & Astrophysics, 692, R1 3 https://tess.mit.edu/qlp/
Aerts, C., & Tkachenko, A. 2024, Astronomy & Astrophysics, 692, R1 3 https://tess.mit.edu/qlp/
2024
-
[4]
S., & Hey, D
Aerts, C., Van Reeth, T., Mombarg, J. S., & Hey, D. 2025, Astronomy & Astrophysics, 695, A214
2025
-
[5]
Armstrong, D. J., Kirk, J., Lam, K. W. F., et al. 2016, MNRAS, 456, 2260, doi: 10.1093/mnras/stv2836 Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068 Astropy Collaboration, Price-Whelan, A. M., Sip˝ ocz, B. M., et al. 2018, AJ, 156, 123, doi: 10.3847/1538-3881/aabc4f 16
-
[6]
2025, Ap&SS, 370, 72, doi: 10.1007/s10509-025-04460-5
Audenaert, J. 2025, Ap&SS, 370, 72, doi: 10.1007/s10509-025-04460-5
- [7]
-
[8]
2022, A&A, 666, A76, doi: 10.1051/0004-6361/202243469
Audenaert, J., & Tkachenko, A. 2022, A&A, 666, A76, doi: 10.1051/0004-6361/202243469
-
[9]
Audenaert, J., Kuszlewicz, J. S., Handberg, R., et al. 2021, AJ, 162, 209, doi: 10.3847/1538-3881/ac166a
-
[10]
Ba, J. L., Kiros, J. R., & Hinton, G. E. 2016, Layer Normalization. https://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Barbara, N. H., Bedding, T. R., Fulcher, B. D., Murphy, S. J., & Van Reeth, T. 2022, MNRAS, 514, 2793, doi: 10.1093/mnras/stac1515
-
[12]
2025, Multiband Embeddings of Light Curves
Becker, I., Protopapas, P., Catelan, M., & Pichara, K. 2025, Multiband Embeddings of Light Curves. https://arxiv.org/abs/2501.12499
-
[13]
, archivePrefix = "arXiv", eprint =
Blomme, J., Sarro, L. M., O’Donovan, F. T., et al. 2011, MNRAS, 418, 96, doi: 10.1111/j.1365-2966.2011.19466.x
-
[14]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., et al. 2021, arXiv preprint arXiv:2108.07258, arXiv:2108.07258, doi: 10.48550/arXiv.2108.07258
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258 2021
-
[15]
Kepler Planet-Detection Mission: Introduction and First Results.Science2010,327, 977
Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977, doi: 10.1126/science.1185402
-
[16]
2001, Machine Learning, 45, 5
Breiman, L. 2001, Machine Learning, 45, 5
2001
-
[17]
Y., Espinoza-Rojas, F., Copp´ ee, Q., & Hekker, S
Choi, J. Y., Espinoza-Rojas, F., Copp´ ee, Q., & Hekker, S. 2025, A&A, 699, A180, doi: 10.1051/0004-6361/202555279
-
[18]
Clementini, G., Ripepi, V., Garofalo, A., et al. 2023, A&A, 674, A18, doi: 10.1051/0004-6361/202243964
-
[19]
L., Angus, R., David, T., et al
Colman, I. L., Angus, R., David, T., et al. 2024, The Astronomical Journal, 167, 189
2024
-
[20]
Cui, K., Armstrong, D. J., & Feng, F. 2024, ApJS, 274, 29, doi: 10.3847/1538-4365/ad62fd
-
[21]
Language Modeling with Gated Convolutional Networks
Dauphin, Y. N., Fan, A., Auli, M., & Grangier, D. 2016, arXiv e-prints, arXiv:1612.08083, doi: 10.48550/arXiv.1612.08083 De Ridder, J., Ripepi, V., Aerts, C., et al. 2023, Astronomy & Astrophysics, 674, A36
-
[22]
Debosscher, J., Sarro, L. M., Aerts, C., et al. 2007, A&A, 475, 1159, doi: 10.1051/0004-6361:20077638
-
[23]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. 2018, arXiv e-prints, arXiv:1810.04805, doi: 10.48550/arXiv.1810.04805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805 2018
-
[24]
2026, A&A, 707, A170, doi: 10.1051/0004-6361/202554026 —
Donoso-Oliva, C., Becker, I., Protopapas, P., et al. 2026, A&A, 707, A170, doi: 10.1051/0004-6361/202554026 —. 2023, A&A, 670, A54, doi: 10.1051/0004-6361/202243928
-
[25]
Eschen, Y. N. E., Bayliss, D., Wilson, T. G., et al. 2024, arXiv e-prints, arXiv:2409.13039, doi: 10.48550/arXiv.2409.13039
-
[26]
2019, GitHub
Falcon, W., & The PyTorch Lightning team. 2019, GitHub
2019
-
[27]
2023, ApJS, 268, 4, doi: 10.3847/1538-4365/acdee5
Fetherolf, T., Pepper, J., Simpson, E., et al. 2023, ApJS, 268, 4, doi: 10.3847/1538-4365/acdee5
-
[28]
Foumani, N. M., Tan, C. W., Webb, G. I., & Salehi, M. 2023, arXiv e-prints, arXiv:2305.16642, doi: 10.48550/arXiv.2305.16642
-
[29]
Friedman, J. H. 2001, Annals of statistics, 1189
2001
-
[30]
2025a, arXiv preprint arXiv:2512.09395
Fritzewski, D., Kemp, A., Li, G., & Aerts, C. 2025a, arXiv preprint arXiv:2512.09395
-
[31]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Gal, Y., & Ghahramani, Z. 2015, arXiv e-prints, arXiv:1506.02142, doi: 10.48550/arXiv.1506.02142
-
[32]
Han, T., & Brandt, T. D. 2023, AJ, 165, 71, doi: 10.3847/1538-3881/acaaa7
-
[33]
Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357, doi: 10.1038/s41586-020-2649-2
-
[34]
Hatt, E., Nielsen, M. B., Chaplin, W. J., et al. 2023, A&A, 669, A67, doi: 10.1051/0004-6361/202244579
-
[35]
2024, A&A, 688, A93, doi: 10.1051/0004-6361/202450489
Hey, D., & Aerts, C. 2024, A&A, 688, A93, doi: 10.1051/0004-6361/202450489
-
[36]
Neural Computation 9, 1735–1780
Hochreiter, S., & Schmidhuber, J. 1997, Neural Computation, 9, 1735, doi: 10.1162/neco.1997.9.8.1735
-
[37]
Hon, M., Stello, D., Garc´ ıa, R. A., et al. 2019, MNRAS, 485, 5616, doi: 10.1093/mnras/stz622
-
[38]
2018a, MNRAS, 476, 3233, doi: 10.1093/mnras/sty483
Hon, M., Stello, D., & Yu, J. 2018a, MNRAS, 476, 3233, doi: 10.1093/mnras/sty483
-
[39]
Hon, M., Stello, D., & Zinn, J. C. 2018b, ApJ, 859, 64, doi: 10.3847/1538-4357/aabfdb
-
[40]
B., Sobeck, C., Haas, M., et al
Howell, S. B., Sobeck, C., Haas, M., et al. 2014, PASP, 126, 398, doi: 10.1086/676406
-
[41]
X., Vanderburg, A., P´ al, A., et al
Huang, C. X., Vanderburg, A., P´ al, A., et al. 2020a, Research Notes of the American Astronomical Society, 4, 204, doi: 10.3847/2515-5172/abca2e —. 2020b, Research Notes of the American Astronomical Society, 4, 206, doi: 10.3847/2515-5172/abca2d
-
[42]
2025, arXiv e-prints, arXiv:2512.10002, doi: 10.48550/arXiv.2512.10002
Huber, D. 2025, arXiv e-prints, arXiv:2512.10002, doi: 10.48550/arXiv.2512.10002
-
[43]
2025, A&A, 701, A150, doi: 10.1051/0004-6361/202554025
Huijse, P., De Ridder, J., Eyer, L., et al. 2025, A&A, 701, A150, doi: 10.1051/0004-6361/202554025
-
[44]
Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90, doi: 10.1109/MCSE.2007.55
-
[45]
W., Tkachenko, A., Johnston, C., & Aerts, C
IJspeert, L. W., Tkachenko, A., Johnston, C., & Aerts, C. 2024a, arXiv e-prints, arXiv:2409.20540, doi: 10.48550/arXiv.2409.20540
-
[46]
W., Tkachenko, A., Johnston, C., et al
IJspeert, L. W., Tkachenko, A., Johnston, C., et al. 2021, A&A, 652, A120, doi: 10.1051/0004-6361/202141489 17 —. 2024b, A&A, 685, A62, doi: 10.1051/0004-6361/202349079
-
[47]
2015, in Proceedings of Machine Learning Research, Vol
Ioffe, S., & Szegedy, C. 2015, in Proceedings of Machine Learning Research, Vol. 37, Proceedings of the 32nd International Conference on Machine Learning, ed. F. Bach & D. Blei (Lille, France: PMLR), 448–456. https://proceedings.mlr.press/v37/ioffe15.html
2015
-
[48]
Jamal, S., & Bloom, J. S. 2020, ApJS, 250, 30, doi: 10.3847/1538-4365/aba8ff
-
[49]
2025, A&A, 694, A185, doi: 10.1051/0004-6361/202452811
Jannsen, N., Tkachenko, A., Royer, P., et al. 2025, A&A, 694, A185, doi: 10.1051/0004-6361/202452811
-
[50]
Kemp, A., Vrancken, J., Mombarg, J. S. G., et al. 2025, A&A, 704, A280, doi: 10.1051/0004-6361/202557362
-
[51]
Kim, D.-W., & Bailer-Jones, C. A. L. 2016, A&A, 587, A18, doi: 10.1051/0004-6361/201527188
-
[52]
2025, A&A, 703, A240, doi: 10.1051/0004-6361/202556079
Kliapets, M., Huijse, P., Tkachenko, A., et al. 2025, A&A, 703, A240, doi: 10.1051/0004-6361/202556079
-
[53]
Koch, D. G., Borucki, W. J., Basri, G., et al. 2010, ApJL, 713, L79, doi: 10.1088/2041-8205/713/2/L79
-
[54]
Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2012, in Advances in Neural Information Processing Systems, ed. F. Pereira, C. Burges, L. Bottou, & K. Weinberger, Vol. 25 (Curran Associates, Inc.). https://proceedings.neurips.cc/paper files/paper/2012/ file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
2012
-
[55]
2022, Research Notes of the American Astronomical Society, 6, 236, doi: 10.3847/2515-5172/aca158
Kunimoto, M., Tey, E., Fong, W., et al. 2022, Research Notes of the American Astronomical Society, 6, 236, doi: 10.3847/2515-5172/aca158
-
[56]
2021, Research Notes of the American Astronomical Society, 5, 234, doi: 10.3847/2515-5172/ac2ef0
Kunimoto, M., Huang, C., Tey, E., et al. 2021, Research Notes of the American Astronomical Society, 5, 234, doi: 10.3847/2515-5172/ac2ef0
-
[57]
Kurtz, D. W. 2022, ARA&A, 60, 31, doi: 10.1146/annurev-astro-052920-094232
-
[58]
LeCun, Y., Boser, B., Denker, J. S., et al. 1989, Neural Computation, 1, 541, doi: 10.1162/neco.1989.1.4.541
-
[59]
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. 1998, Proceedings of the IEEE, 86, 2278, doi: 10.1109/5.726791
-
[60]
R., et al
Li, G., Van Reeth, T., Bedding, T. R., et al. 2020, Monthly Notices of the Royal Astronomical Society, 491, 3586 Lightkurve Collaboration, Cardoso, J. V. d. M., Hedges, C., et al. 2018, Lightkurve: Kepler and TESS time series analysis in Python, Astrophysics Source Code Library, record ascl:1812.013
2020
-
[61]
Lomb, N. R. 1976, Ap&SS, 39, 447, doi: 10.1007/BF00648343
-
[62]
Decoupled Weight Decay Regularization
Loshchilov, I., & Hutter, F. 2017, arXiv e-prints, arXiv:1711.05101, doi: 10.48550/arXiv.1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2017
-
[63]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., & Melville, J. 2018, arXiv e-prints, arXiv:1802.03426, doi: 10.48550/arXiv.1802.03426
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.03426 2018
-
[64]
2010, in Proceedings of the 9th Python in Science Conference, ed
McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, ed. S. van der Walt & J. Millman, 51–56
2010
-
[65]
2026, in ICLR 2026 Workshop on Foundation Models for Science: Real-World Impact and Science-First Design
Mercader-Perez, P., Cuesta-Lazaro, C., Muthukrishna, D., et al. 2026, in ICLR 2026 Workshop on Foundation Models for Science: Real-World Impact and Science-First Design. https://openreview.net/forum?id=nebGk9bm3L
2026
-
[66]
S., Aerts, C., Van Reeth, T., & Hey, D
Mombarg, J. S., Aerts, C., Van Reeth, T., & Hey, D. 2024, Astronomy & Astrophysics, 691, A131
2024
-
[67]
2025, A&A, 703, A41, doi: 10.1051/0004-6361/202554289
Moreno-Cartagena, D., Protopapas, P., Cabrera-Vives, G., et al. 2025, A&A, 703, A41, doi: 10.1051/0004-6361/202554289
-
[68]
Muthukrishna, D., Narayan, G., Mandel, K. S., Biswas, R., & Hloˇ zek, R. 2019, PASP, 131, 118002, doi: 10.1088/1538-3873/ab1609
-
[69]
2025, A&A, 694, A313, doi: 10.1051/0004-6361/202452325
Nascimbeni, V., Piotto, G., Cabrera, J., et al. 2025, A&A, 694, A313, doi: 10.1051/0004-6361/202452325
-
[70]
S., P´ erez, F., & van der Walt, S
Naul, B., Bloom, J. S., P´ erez, F., & van der Walt, S. 2018, Nature Astronomy, 2, 151, doi: 10.1038/s41550-017-0321-z
-
[71]
Davies, G. R. 2022, A&A, 663, A51, doi: 10.1051/0004-6361/202243064
-
[72]
Olmschenk, G., Barry, R. K., Ishitani Silva, S., et al. 2024, AJ, 168, 83, doi: 10.3847/1538-3881/ad55f1
-
[73]
2024, MNRAS, 528, 5890, doi: 10.1093/mnras/stae068
Pan, J.-S., Ting, Y.-S., & Yu, J. 2024, MNRAS, 528, 5890, doi: 10.1093/mnras/stae068
-
[74]
2024, MNRAS, 531, 4990, doi: 10.1093/mnras/stae1450
Parker, L., Lanusse, F., Golkar, S., et al. 2024, MNRAS, 531, 4990, doi: 10.1093/mnras/stae1450
-
[75]
2019, in Advances in Neural Information Processing Systems 32 (Curran
Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems 32 (Curran
2019
-
[76]
2011, Journal of Machine Learning Research, 12, 2825
Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825
2011
-
[77]
2026, arXiv e-prints, arXiv:2603.22236
Petitpas, G., Haviland, J., Han, T., et al. 2026, arXiv e-prints, arXiv:2603.22236. https://arxiv.org/abs/2603.22236
-
[78]
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. 2018
2018
-
[79]
2025, A&A, 693, A268, doi: 10.1051/0004-6361/202452429
Ranaivomanana, P., Uzundag, M., Johnston, C., et al. 2025, A&A, 693, A268, doi: 10.1051/0004-6361/202452429
-
[80]
2024, arXiv e-prints, arXiv:2410.16336, doi: 10.48550/arXiv.2410.16336
Ranjbar, M., & Rahimzadeh, M. 2024, arXiv e-prints, arXiv:2410.16336, doi: 10.48550/arXiv.2410.16336
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.