Recognition: unknown
Beyond Single Reports: Evaluating Automated ATT&CK Technique Extraction in Multi-Report Campaign Settings
Pith reviewed 2026-05-10 17:16 UTC · model grok-4.3
The pith
Aggregating multiple cybersecurity reports improves automated attack technique extraction by about 26% over single reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
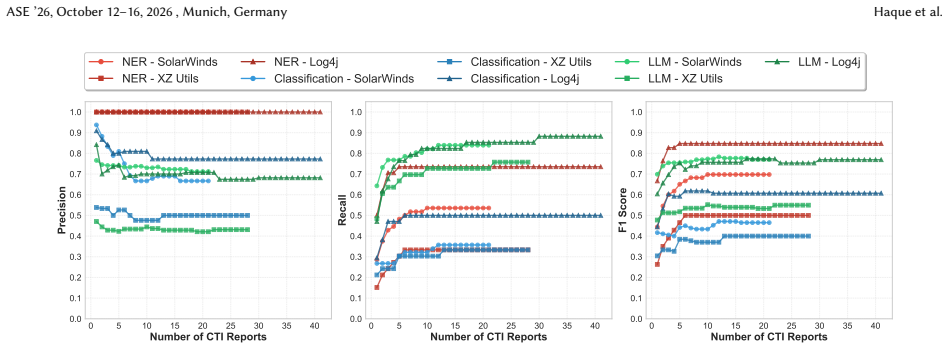
Aggregating multiple CTI reports improves the F1 score by about 26% over single-report analysis, with most approaches reaching performance saturation after 5--15 reports. Extraction performance remains limited, with maximum F1 scores of 78.6% for SolarWinds and 54.9% for XZ Utils, and up to 33.3% of misclassifications involve semantically similar techniques.
What carries the argument
Multi-report aggregation applied to 29 methods spanning named entity recognition, encoder-based classification, and decoder-based LLM approaches for extracting ATT&CK techniques from CTI reports.
If this is right
- Aggregating 5 to 15 reports per campaign brings most of the performance gain.
- Longer reports with technical details yield better extraction results.
- Semantic similarity between techniques causes a notable share of errors and reduces control coverage.
- Overall, even the best multi-report setups leave substantial techniques undetected.
Where Pith is reading between the lines
- Security teams should prioritize gathering several reports on each suspected campaign rather than relying on the first one found.
- Improving disambiguation between similar techniques could yield further gains in control recommendations.
- The saturation after 5-15 reports suggests that additional reports beyond that point add little new information for most methods.
Load-bearing premise
The manually extracted ground-truth technique labels from the 90 reports are complete and unbiased, and the three selected campaigns fairly represent other multi-report scenarios.
What would settle it
Independently verify the complete set of techniques for a new campaign using multiple expert analysts and then run the 29 methods on increasing numbers of its reports to check if the 26% gain and 5-15 report saturation still appear.
Figures





read the original abstract
Large-scale cyberattacks, referred to as campaigns, are documented across multiple CTI reports from diverse sources, with some providing a high-level overview of attack techniques and others providing technical details. Extracting attack techniques from reports is essential for organizations to identify the controls required to protect against attacks. Manually extracting techniques at scale is impractical. Existing automated methods focus on single reports, leaving many attack techniques and their controls undetected, resulting in a fragmented view of campaign behavior. The goal of this study is to aid security researchers in extracting attack techniques and controls from a campaign by replicating and comparing the performance of the state-of-the-art ATT&CK technique extraction methods in a multi-report campaign setting compared to prior single-report evaluations. We conduct an empirical study of 29 methods to extract attack techniques, spanning named entity recognition (NER), encoder-based classification, and decoder-based LLM approaches. Our study analyzes 90 CTI reports across three major attack campaigns: SolarWinds, XZ Utils, and Log4j, using both quantitative performance metrics and their impact on controls. Our results show that aggregating multiple CTI reports improves the F1 score by about 26% over single-report analysis, with most approaches reaching performance saturation after 5--15 reports. Despite these gains, extraction performance remains limited, with maximum F1 scores of 78.6% for SolarWinds and 54.9% for XZ Utils. Moreover, up to 33.3% of misclassifications involve semantically similar techniques that share tactics and overlap in descriptions. The misclassification has a disproportionate effect on control coverage. Reports that are longer and include technical details consistently perform better, even though their readability scores are low.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates 29 automated methods for extracting MITRE ATT&CK techniques from CTI reports, spanning NER, encoder-based classification, and decoder-based LLM approaches. Using 90 reports across three campaigns (SolarWinds, XZ Utils, Log4j), it claims that aggregating multiple reports improves F1 scores by approximately 26% over single-report analysis, with most methods reaching performance saturation after 5-15 reports. Additional findings include maximum F1 scores of 78.6% (SolarWinds) and 54.9% (XZ Utils), up to 33.3% of misclassifications involving semantically similar techniques, disproportionate effects on control coverage, and better performance from longer, technically detailed reports.
Significance. If the empirical results hold, the work demonstrates the value of multi-report aggregation for more complete ATT&CK technique extraction in campaign settings, which could improve downstream control identification in security practice. The broad comparison of method families and the inclusion of saturation curves and misclassification analysis are positive contributions. However, absolute performance remains modest, and the practical significance is constrained by the three-campaign scope and unresolved questions around ground-truth reliability.
major comments (3)
- [§3.2] §3.2 (Dataset and Ground Truth Construction): The ground-truth ATT&CK technique labels for the 90 reports are extracted from the same corpus used for evaluation, but the section provides no inter-annotator agreement metrics, independent validation against MITRE ATT&CK pages, or external corroboration. This directly undermines the central 26% F1 aggregation gain reported in §5.3, as incomplete or biased labels could artifactually inflate measured improvements from multi-report union.
- [§5.3] §5.3 (Results and Saturation Analysis): The 26% F1 improvement and saturation after 5-15 reports are presented without statistical significance tests, confidence intervals, or variance across the 29 methods. The aggregation strategy (e.g., union vs. majority vote) and single-report baseline implementation details are also insufficiently specified, making it difficult to assess robustness or replicate the headline result.
- [§6] §6 (Discussion and Limitations): The claim that the three campaigns are representative of broader multi-report CTI scenarios lacks supporting evidence or comparison to other campaigns; this is load-bearing for generalizing the saturation curves and misclassification rates (up to 33.3%) to the wider domain.
minor comments (3)
- [Abstract] Abstract: The phrase 'up to 33.3% of misclassifications' should specify whether this is an average, maximum, or per-campaign figure, and cross-reference the exact table or figure in the main text.
- [Figure 4] Figure 4 (or equivalent saturation plot): Add error bars or shaded variance regions across methods to clarify the consistency of the 5-15 report saturation point.
- [§4] §4 (Method Implementations): Ensure all 29 baseline methods include explicit citations to their original papers and note any re-implementation choices or hyperparameter settings used in this study.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each of the major comments below, proposing revisions to improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Dataset and Ground Truth Construction): The ground-truth ATT&CK technique labels for the 90 reports are extracted from the same corpus used for evaluation, but the section provides no inter-annotator agreement metrics, independent validation against MITRE ATT&CK pages, or external corroboration. This directly undermines the central 26% F1 aggregation gain reported in §5.3, as incomplete or biased labels could artifactually inflate measured improvements from multi-report union.
Authors: We agree that detailed documentation of ground truth construction is essential for validating the reported improvements. The ground truth labels were derived through expert annotation of the reports, with each technique mapped to the official MITRE ATT&CK knowledge base entries for the respective campaigns. To address this, we will revise §3.2 to provide a step-by-step description of the annotation process, including cross-referencing with ATT&CK pages. We will also add a note in the limitations section acknowledging the absence of inter-annotator agreement metrics due to the focused annotation effort and discuss potential implications for label reliability. revision: partial
-
Referee: [§5.3] §5.3 (Results and Saturation Analysis): The 26% F1 improvement and saturation after 5-15 reports are presented without statistical significance tests, confidence intervals, or variance across the 29 methods. The aggregation strategy (e.g., union vs. majority vote) and single-report baseline implementation details are also insufficiently specified, making it difficult to assess robustness or replicate the headline result.
Authors: We appreciate this feedback on enhancing statistical robustness. In the study, aggregation was implemented as the union of extracted techniques across reports for a given campaign, while the single-report baseline consisted of the mean F1 score computed individually per report. We will update §5.3 to explicitly describe these strategies, include bootstrap-derived confidence intervals for the F1 scores and the 26% improvement, report variance across methods, and perform paired statistical tests (e.g., Wilcoxon signed-rank) to confirm significance of the gains. These additions will allow better assessment of the results. revision: yes
-
Referee: [§6] §6 (Discussion and Limitations): The claim that the three campaigns are representative of broader multi-report CTI scenarios lacks supporting evidence or comparison to other campaigns; this is load-bearing for generalizing the saturation curves and misclassification rates (up to 33.3%) to the wider domain.
Authors: The campaigns were chosen for their extensive public documentation and availability of multiple independent CTI reports, enabling the multi-report analysis. The consistent patterns observed (saturation at 5-15 reports and similar misclassification trends) across the three provide some basis for the observations. We will expand the discussion in §6 to better justify the selection criteria with reference to campaign diversity in tactics and report characteristics, while explicitly qualifying the generalizability and recommending validation on additional campaigns in future work. revision: partial
Circularity Check
No circularity: empirical F1 measurements against independent ground-truth annotations
full rationale
This is a purely empirical evaluation paper with no derivation chain, first-principles predictions, or mathematical claims. The headline result (26% F1 lift from multi-report aggregation, saturation at 5-15 reports) is obtained by running 29 existing extraction methods on 90 reports, aggregating their outputs, and directly measuring precision/recall/F1 against manually annotated ground-truth technique labels extracted from the same corpus. These are observed performance quantities, not quantities defined or forced by the paper's own equations, fitted parameters, or self-referential definitions. No self-citation is load-bearing for the central claim; prior single-report methods are replicated as external baselines. The evaluation is self-contained against the external benchmark of the ground-truth annotations, so the paper receives the default low circularity score.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ATT&CK provides a stable, complete taxonomy usable as ground truth for extraction evaluation
- domain assumption The three selected campaigns are representative of typical multi-report CTI scenarios
Reference graph
Works this paper leans on
-
[1]
Ehsan Aghaei, Xi Niu, Waseem Shadid, and Ehab Al-Shaer. 2022. Secure- bert: A domain-specific language model for cybersecurity. Ininternational conference on security and privacy in communication systems. Springer, 39–56
2022
-
[2]
Bader Al-Sada, Alireza Sadighian, and Gabriele Oligeri. 2024. MITRE ATT&CK: State of the art and way forward.Comput. Surveys57, 1 (2024), 1–37
2024
-
[3]
Dharun Anandayuvaraj, Matthew Campbell, Arav Tewari, and James C Davis. 2024. FAIL: Analyzing software failures from the news using LLMs. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 506–518
2024
-
[4]
Vimala Balakrishnan and Ethel Lloyd-Yemoh. 2014. Stemming and lemma- tization: A comparison of retrieval performances.Lecture notes on software engineering2, 3 (2014), 262
2014
-
[5]
Sebastian Baltes and Paul Ralph. 2022. Sampling in software engineering research: A critical review and guidelines.Empirical Software Engineering 27, 4 (2022), 94
2022
-
[6]
Markus Bayer, Philipp Kuehn, Ramin Shanehsaz, and Christian Reuter
-
[7]
Cysecbert: A domain-adapted language model for the cybersecurity domain.ACM Transactions on Privacy and Security27, 2 (2024), 1–20
2024
-
[8]
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A pretrained language model for scientific text. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3615– 3620
2019
-
[9]
David Braue. 2025. Cybercrime To Cost The World 12.2 Trillion Annually By 2031. https://cybersecurityventures.com/official-cybercrime-report- 2025/ Accessed: March 25, 2026
2025
-
[10]
Matt Bromiley. 2016. Threat intelligence: What it is, and how to use it effectively.SANS Institute InfoSec Reading Room15 (2016), 172
2016
-
[11]
Marvin Büchel, Tommaso Paladini, Stefano Longari, Michele Carminati, Stefano Zanero, Hodaya Binyamini, Gal Engelberg, Dan Klein, Giancarlo Guizzardi, Marco Caselli, et al. 2025. {SoK}: Automated {TTP } Extrac- tion from {CTI} Reports–Are We There Yet?. In34th USENIX Security Symposium (USENIX Security 25). 4621–4641
2025
-
[12]
Tristan JB Cann, Ben Dennes, Travis Coan, Saffron O’Neill, and Hywel TP Williams. 2025. Using semantic similarity to measure the echo of strategic communications.EPJ Data Science14, 1 (2025), 20
2025
-
[13]
Jeffrey C Carver. 2010. Towards reporting guidelines for experimental replications: A proposal. In1st international workshop on replication in empirical software engineering, Vol. 1. 1–4
2010
-
[14]
Minghao Chen, Kaijie Zhu, Bin Lu, Ding Li, Qingjun Yuan, and Yuefei Zhu
-
[15]
AECR: Automatic attack technique intelligence extraction based on fine-tuned large language model.Computers & Security150 (2025), 104213
2025
- [16]
-
[17]
MITRE Corporation. 2023. Threat Report ATT&CK Mapping (TRAM) Dataset. https://github.com/center-for-threat-informed-defense/tram. Ac- cessed: 2025-10-09
2023
-
[18]
Alan R Dennis and Joseph S Valacich. 2015. A replication manifesto.AIS Transactions on Replication Research1, 1 (2015), 1
2015
-
[19]
LLC MITRE Engenuity. 2023. Threat report att&ck mapper (tram)
2023
-
[20]
Reza Fayyazi, Rozhina Taghdimi, and Shanchieh Jay Yang. 2024. Advanc- ing TTP analysis: Harnessing the power of large language models with retrieval augmented generation. In2024 Annual Computer Security Appli- cations Conference Workshops (ACSAC Workshops). IEEE, 255–261
2024
-
[21]
1998.WordNet: An electronic lexical database
Christiane Fellbaum. 1998.WordNet: An electronic lexical database. MIT press
1998
-
[22]
Yu Fengrui and Yanhui Du. 2024. Few-shot learning of TTPs classification using large language models
2024
-
[23]
Romy Fieblinger, Md Tanvirul Alam, and Nidhi Rastogi. 2024. Actionable cyber threat intelligence using knowledge graphs and large language mod- els. In2024 IEEE European symposium on security and privacy workshops (EuroS&PW). IEEE, 100–111
2024
-
[24]
Lingyu Gao, Debanjan Ghosh, and Kevin Gimpel. 2023. The benefits of label-description training for zero-shot text classification. InProceedings of the 2023 conference on empirical methods in natural language processing. 13823–13844
2023
-
[25]
Peng Gao, Fei Shao, Xiaoyuan Liu, Xusheng Xiao, Zheng Qin, Fengyuan Xu, Prateek Mittal, Sanjeev R Kulkarni, and Dawn Song. 2021. Enabling efficient cyber threat hunting with cyber threat intelligence. In2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 193–204
2021
-
[26]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Greg Guest, Emily Namey, and Mario Chen. 2020. A simple method to assess and report thematic saturation in qualitative research.PloS one15, 5 (2020), e0232076
2020
-
[28]
Sivana Hamer, Jacob Bowen, Md Nazmul Haque, Robert Hines, Chris Madden, and Laurie Williams. 2026. Closing the Chain: How to reduce your risk of being SolarWinds, Log4j, or XZ Utils. In2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE). IEEE
2026
-
[29]
Monique M Hennink, Bonnie N Kaiser, and Vincent C Marconi. 2017. Code saturation versus meaning saturation: how many interviews are enough? Qualitative health research27, 4 (2017), 591–608
2017
-
[30]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[31]
Yi-Ting Huang, R Vaitheeshwari, Meng-Chang Chen, Ying-Dar Lin, Ren- Hung Hwang, Po-Ching Lin, Yuan-Cheng Lai, Eric Hsiao-Kuang Wu, Chung-Hsuan Chen, Zi-Jie Liao, et al . 2024. MITREtrieval: Retrieving MITRE techniques from unstructured threat reports by fusion of deep learning and ontology.IEEE Transactions on Network and Service Manage- ment21, 4 (2024),...
2024
-
[32]
Ghaith Husari, Ehab Al-Shaer, Mohiuddin Ahmed, Bill Chu, and Xi Niu
-
[33]
InProceedings of the 33rd annual computer security applications conference
Ttpdrill: Automatic and accurate extraction of threat actions from unstructured text of cti sources. InProceedings of the 33rd annual computer security applications conference. 103–115
-
[34]
IBM. 2016. IBM Watson to Tackle Cybercrime. https://uk.newsroom.ibm. com/2016-May-10-IBM-Watson-to-Tackle-Cybercrime Accessed: March 11 ASE ’26, October 12–16, 2026 , Munich, Germany Haque et al. 18, 2026
2016
-
[35]
Youngjin Jin, Eugene Jang, Jian Cui, Jin-Woo Chung, Yongjae Lee, and Seungwon Shin. 2023. Darkbert: A language model for the dark side of the internet. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 7515–7533
2023
-
[36]
Chris Johnson, Lee Badger, David Waltermire, Julie Snyder, Clem Skorupka, et al. 2016. Guide to cyber threat information sharing.NIST special publication800, 150 (2016), 35
2016
-
[37]
1975.Derivation of new readability formulas (automated read- ability index, fog count and flesch reading ease formula) for navy enlisted personnel
J Peter Kincaid, Robert P Fishburne Jr, Richard L Rogers, and Brad S Chissom. 1975.Derivation of new readability formulas (automated read- ability index, fog count and flesch reading ease formula) for navy enlisted personnel. Technical Report
1975
-
[38]
McDonald, and Joakim Nivre
Sandra Kübler, Ryan T. McDonald, and Joakim Nivre. 2009.Dependency Parsing. Synthesis Lectures on Human Language Technologies. Morgan & Claypool Publishers
2009
-
[39]
Udesh Kumarasinghe, Ahmed Lekssays, Husrev Taha Sencar, Sabri Boughorbel, Charitha Elvitigala, and Preslav Nakov. 2024. Semantic rank- ing for automated adversarial technique annotation in security text. In Proceedings of the 19th ACM Asia conference on computer and communica- tions security. 49–62
2024
-
[40]
Lukas Lange, Marc Müller, Ghazaleh Haratinezhad Torbati, Dragan Milchevski, Patrick Grau, Subhash Pujari, and Annemarie Friedrich. 2024. Annoctr: A dataset for detecting and linking entities, tactics, and tech- niques in cyber threat reports.arXiv preprint arXiv:2404.07765(2024)
-
[41]
Zhenyuan Li, Jun Zeng, Yan Chen, and Zhenkai Liang. 2022. AttacKG: Constructing technique knowledge graph from cyber threat intelligence reports. InEuropean symposium on research in computer security. Springer, 589–609
2022
-
[42]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281(2023)
work page internal anchor Pith review arXiv 2023
-
[43]
Xiaojing Liao, Kan Yuan, XiaoFeng Wang, Zhou Li, Luyi Xing, and Raheem Beyah. 2016. Acing the ioc game: Toward automatic discovery and analysis of open-source cyber threat intelligence. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security. 755–766
2016
- [44]
-
[45]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[46]
Thomas W MacFarland and Jan M Yates. 2016. Mann–whitney u test. In Introduction to nonparametric statistics for the biological sciences using R. Springer, 103–132
2016
-
[47]
Christopher D Manning. 2011. Part-of-speech tagging from 97% to 100%: is it time for some linguistics?. InInternational conference on intelligent text processing and computational linguistics. Springer, 171–189
2011
-
[48]
MITRE. 2026. MITRE ATT&CK™Framework. https://attack.mitre.org/. Last accessed: 2026-02-24
2026
-
[49]
MITRE Corporation. 2024. ATT&CK Campaigns. https://attack.mitre.org/ campaigns/ Accessed: March 18, 2026
2024
-
[50]
Vittorio Orbinato, Mariarosaria Barbaraci, Roberto Natella, and Domenico Cotroneo. 2022. Automatic mapping of unstructured cyber threat intelli- gence: An experimental study:(practical experience report). In2022 IEEE 33rd International symposium on software reliability engineering (ISSRE). IEEE, 181–192
2022
-
[51]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al . 2011. Scikit-learn: Machine learning in Python.the Journal of machine Learning research12 (2011), 2825–2830
2011
-
[52]
Joël Plisson, Nada Lavrac, Dunja Mladenic, et al . 2004. A rule based approach to word lemmatization. InProceedings of IS, Vol. 3. 83–86
2004
-
[53]
Fariha Ishrat Rahman, Sadaf Md Halim, Anoop Singhal, and Latifur Khan
-
[54]
InIFIP Annual Conference on Data and Applications Security and Privacy
Alert: A framework for efficient extraction of attack techniques from cyber threat intelligence reports using active learning. InIFIP Annual Conference on Data and Applications Security and Privacy. Springer, 203– 220
- [55]
-
[56]
Priyanka Ranade, Aritran Piplai, Anupam Joshi, and Tim Finin. 2021. Cy- bert: Contextualized embeddings for the cybersecurity domain. In2021 IEEE international conference on big data (Big Data). IEEE, 3334–3342
2021
-
[57]
Nanda Rani, Bikash Saha, Vikas Maurya, and Sandeep Kumar Shukla. 2023. TTPHunter: Automated extraction of actionable intelligence as TTPs from narrative threat reports. InProceedings of the 2023 australasian computer science week. 126–134
2023
-
[58]
Nanda Rani, Bikash Saha, Vikas Maurya, and Sandeep Kumar Shukla. 2024. Ttpxhunter: Actionable threat intelligence extraction as ttps from finished cyber threat reports.Digital Threats: Research and Practice5, 4 (2024), 1–19
2024
-
[59]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embed- dings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th interna- tional joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[60]
Álvaro Ruiz-Ródenas, Jaime Pujante Sáez, Daniel García-Algora, Mario Ro- dríguez Béjar, Jorge Blasco, and José Luis Hernández-Ramos. 2025. Syn- thCTI: LLM-Driven Synthetic CTI Generation to enhance MITRE Tech- nique Mapping.Future Generation Computer Systems(2025), 108232
2025
-
[61]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A systematic survey of prompt engi- neering in large language models: Techniques and applications.arXiv preprint arXiv:2402.079271 (2024)
work page internal anchor Pith review arXiv 2024
- [62]
-
[63]
Giuseppe Siracusano, Davide Sanvito, Roberto Gonzalez, Manikantan Srinivasan, Sivakaman Kamatchi, Wataru Takahashi, Masaru Kawakita, Takahiro Kakumaru, and Roberto Bifulco. 2023. Time for action: Auto- mated analysis of cyber threat intelligence in the wild.arXiv preprint arXiv:2307.10214(2023)
-
[64]
Wiem Tounsi. 2019. What is cyber threat intelligence and how is it evolv- ing?Cyber-Vigilance and Digital Trust: Cyber Security in the Era of Cloud Computing and IoT(2019), 1–49
2019
-
[65]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research9, 11 (2008)
2008
-
[66]
Jonathan J Webster and Chunyu Kit. 1992. Tokenization as the initial phase in NLP. InCOLING 1992 volume 4: The 14th international conference on computational linguistics
1992
- [67]
-
[68]
Ming Xu, Hongtai Wang, Jiahao Liu, Yun Lin, Chenyang Xu Yingshi Liu, Hoon Wei Lim, and Jin Song Dong. 2024. Intelex: A llm-driven attack-level threat intelligence extraction framework.arXiv e-prints(2024), arXiv– 2412
2024
-
[69]
Yongheng Zhang, Tingwen Du, Yunshan Ma, Xiang Wang, Yi Xie, Guozheng Yang, Yuliang Lu, and Ee-Chien Chang. 2025. AttacKG+: Boost- ing attack graph construction with large language models.Computers & Security150 (2025), 104220. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.